 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 5.2 验证 Toolbox 词汇
5.2 验证 Toolbox 词汇
Toolbox 格式的许多词汇不符合任何特定的模式。有些条目可能包括额外的字段,或以一种新的方式排序现有字段。手动检查成千上万的词汇条目是不可行的。我们可以在Counter的帮助下很容易地找出频率异常的字段序列:
>>> from collections import Counter>>> field_sequences = Counter(':'.join(field.tag for field in entry) for entry in lexicon)>>> field_sequences.most_common()[('lx:ps:pt:ge:tkp:dt:ex:xp:xe', 41), ('lx:rt:ps:pt:ge:tkp:dt:ex:xp:xe', 37),('lx:rt:ps:pt:ge:tkp:dt:ex:xp:xe:ex:xp:xe', 27), ('lx:ps:pt:ge:tkp:nt:dt:ex:xp:xe', 20), ...]
检查完高频字段序列后,我们可以设计一个词汇条目的上下文无关语法。在5.2中的语法使用我们在8.看到的 CFG 格式。这样的语法模型隐含 Toolbox 条目的嵌套结构,建立一个树状结构,树的叶子是单独的字段名。最后,我们遍历条目并报告它们与语法的一致性,如5.2所示。那些被语法接受的在前面加一个'+' ![[1]](/uploads/projects/1594/65961.jpg) ,那些被语法拒绝的在前面加一个
,那些被语法拒绝的在前面加一个'-' ![[2]](/uploads/projects/1594/65962.jpg) 。在开发这样一个文法的过程中,它可以帮助过滤掉一些标签
。在开发这样一个文法的过程中,它可以帮助过滤掉一些标签![[3]](/uploads/projects/1594/65963.jpg) 。
。
grammar = nltk.CFG.fromstring('''S -> Head PS Glosses Comment Date Sem_Field ExamplesHead -> Lexeme RootLexeme -> "lx"Root -> "rt" |PS -> "ps"Glosses -> Gloss Glosses |Gloss -> "ge" | "tkp" | "eng"Date -> "dt"Sem_Field -> "sf"Examples -> Example Ex_Pidgin Ex_English Examples |Example -> "ex"Ex_Pidgin -> "xp"Ex_English -> "xe"Comment -> "cmt" | "nt" |''')def validate_lexicon(grammar, lexicon, ignored_tags):rd_parser = nltk.RecursiveDescentParser(grammar)for entry in lexicon:marker_list = [field.tag for field in entry if field.tag not in ignored_tags]if list(rd_parser.parse(marker_list)):print("+", ':'.join(marker_list)) ![[1]](/projects/nlp-py-2e-zh/Images/346344c2e5a627acfdddf948fb69cb1d.jpg)else:print("-", ':'.join(marker_list)) ![[2]](/projects/nlp-py-2e-zh/Images/f9e1ba3246770e3ecb24f813f33f2075.jpg)
另一种方法是用一个词块分析器(7.),因为它能识别局部结构并报告已确定的局部结构,会更加有效。在5.3中我们为词汇条目建立一个词块语法,然后解析每个条目。这个程序的输出的一个示例如5.4所示。
grammar = r"""lexfunc: {<lf>(<lv><ln|le>*)*}example: {<rf|xv><xn|xe>*}sense: {<sn><ps><pn|gv|dv|gn|gp|dn|rn|ge|de|re>*<example>*<lexfunc>*}record: {<lx><hm><sense>+<dt>}"""
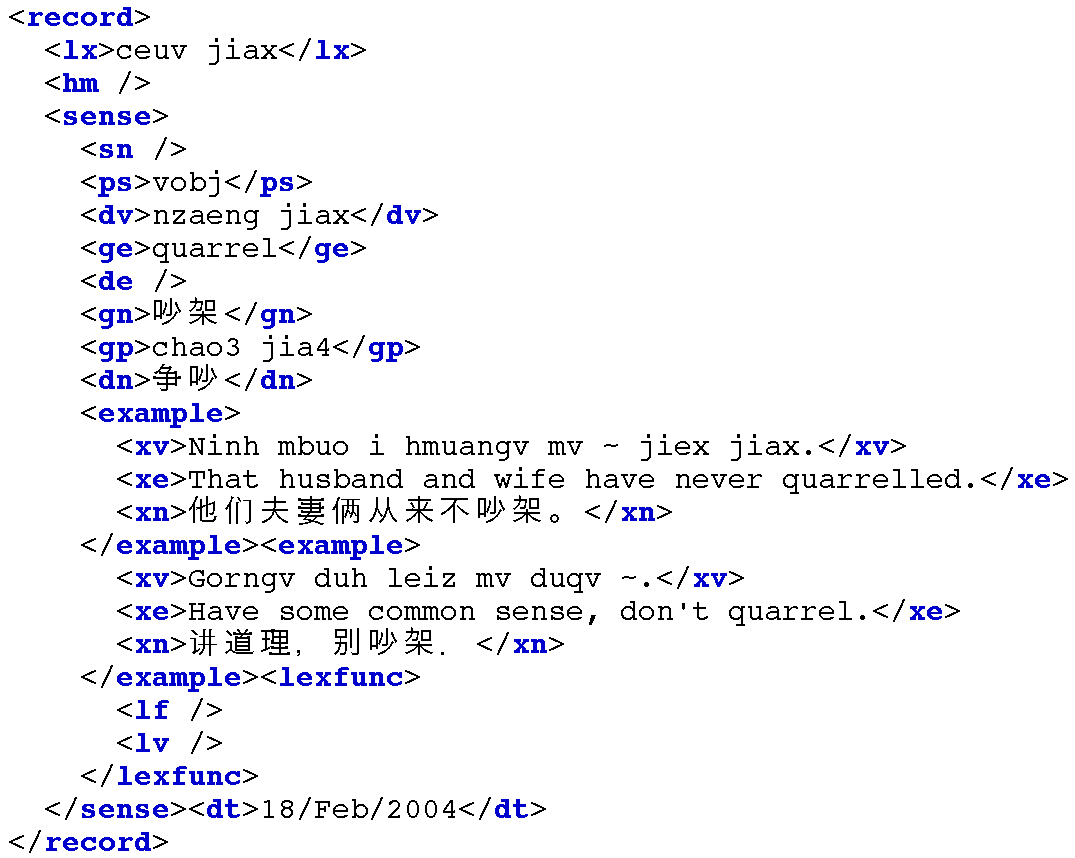
图 5.4:一个词条的 XML 表示,对 Toolbox 记录的词块分析的结果
