 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 1.8 文本语料库的结构
1.8 文本语料库的结构
到目前为止,我们已经看到了大量的语料库结构;1.3总结了它们。最简单的一种没有任何结构,仅仅是一个文本集合。通常,文本会按照其可能对应的文体、来源、作者、语言等分类。有时,这些类别会重叠,尤其是在按主题分类的情况下,因为一个文本可能与多个主题相关。偶尔的,文本集有一个时间结构,新闻集合是最常见的例子。
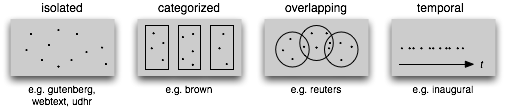
图 1.3:文本语料库的常见结构:最简单的一种语料库是一些孤立的没有什么特别的组织的文本集合;一些语料库按如文体(布朗语料库)等分类组织结构;一些分类会重叠,如主题类别(路透社语料库);另外一些语料库可以表示随时间变化语言用法的改变(就职演说语料库)。
表 1.3:
NLTK 中定义的基本语料库函数:使用help(nltk.corpus.reader)可以找到更多的文档,也可以阅读http://nltk.org/howto上的在线语料库的 HOWTO。
>>> raw = gutenberg.raw("burgess-busterbrown.txt")>>> raw[1:20]'The Adventures of B'>>> words = gutenberg.words("burgess-busterbrown.txt")>>> words[1:20]['The', 'Adventures', 'of', 'Buster', 'Bear', 'by', 'Thornton', 'W', '.','Burgess', '1920', ']', 'I', 'BUSTER', 'BEAR', 'GOES', 'FISHING', 'Buster','Bear']>>> sents = gutenberg.sents("burgess-busterbrown.txt")>>> sents[1:20][['I'], ['BUSTER', 'BEAR', 'GOES', 'FISHING'], ['Buster', 'Bear', 'yawned', 'as','he', 'lay', 'on', 'his', 'comfortable', 'bed', 'of', 'leaves', 'and', 'watched','the', 'first', 'early', 'morning', 'sunbeams', 'creeping', 'through', ...], ...]
