我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 6.1 树库和语法
6.1 树库和语法
corpus模块定义了treebank语料的阅读器,其中包含了宾州树库语料的 10%的样本。
>>> from nltk.corpus import treebank>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]>>> print(t)(S(NP-SBJ(NP (NNP Pierre) (NNP Vinken))(, ,)(ADJP (NP (CD 61) (NNS years)) (JJ old))(, ,))(VP(MD will)(VP(VB join)(NP (DT the) (NN board))(PP-CLR(IN as)(NP (DT a) (JJ nonexecutive) (NN director)))(NP-TMP (NNP Nov.) (CD 29))))(. .))
我们可以利用这些数据来帮助开发一个语法。例如,6.1中的程序使用一个简单的过滤器找出带句子补语的动词。假设我们已经有一个形如VP -> Vs S的产生式,这个信息使我们能够识别那些包括在Vs的扩张中的特别的动词。
def filter(tree):child_nodes = [child.label() for child in treeif isinstance(child, nltk.Tree)]return (tree.label() == 'VP') and ('S' in child_nodes)
PP 附着语料库nltk.corpus.ppattach是另一个有关特别动词配价的信息源。在这里,我们演示挖掘这个语料库的技术。它找出具有固定的介词和名词的介词短语对,其中介词短语附着到VP还是NP,由选择的动词决定。
>>> from collections import defaultdict>>> entries = nltk.corpus.ppattach.attachments('training')>>> table = defaultdict(lambda: defaultdict(set))>>> for entry in entries:... key = entry.noun1 + '-' + entry.prep + '-' + entry.noun2... table[key][entry.attachment].add(entry.verb)...>>> for key in sorted(table):... if len(table[key]) > 1:... print(key, 'N:', sorted(table[key]['N']), 'V:', sorted(table[key]['V']))
这个程序的输出行中我们发现offer-from-group N: ['rejected'] V: ['received'],这表示 received 期望一个单独的PP附着到VP而 rejected 不是的。和以前一样,我们可以使用此信息来帮助构建语法。
NLTK 语料库收集了来自 PE08 跨框架跨领域分析器评估共享任务的数据。一个更大的文法集合已准备好用于比较不同的分析器,它可以通过下载large_grammars包获得(如python -m nltk.downloader large_grammars)。
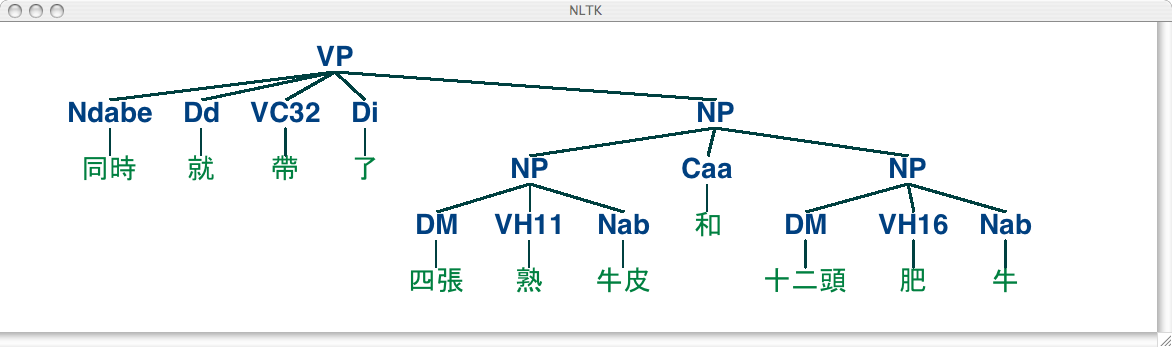
NLTK 语料库也收集了 中央研究院树库语料 ,包括 10,000 句已分析的句子,来自 现代汉语中央研究院平衡语料库 。让我们加载并显示这个语料库中的一棵树。
>>> nltk.corpus.sinica_treebank.parsed_sents()[3450].draw()