 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 5 朴素贝叶斯分类器
5 朴素贝叶斯分类器
在朴素贝叶斯分类器中,每个特征都得到发言权,来确定哪个标签应该被分配到一个给定的输入值。为一个输入值选择标签,朴素贝叶斯分类器以计算每个标签的先验概率开始,它由在训练集上检查每个标签的频率来确定。之后,每个特征的贡献与它的先验概率组合,得到每个标签的似然估计。似然估计最高的标签会分配给输入值。5.1说明了这一过程。
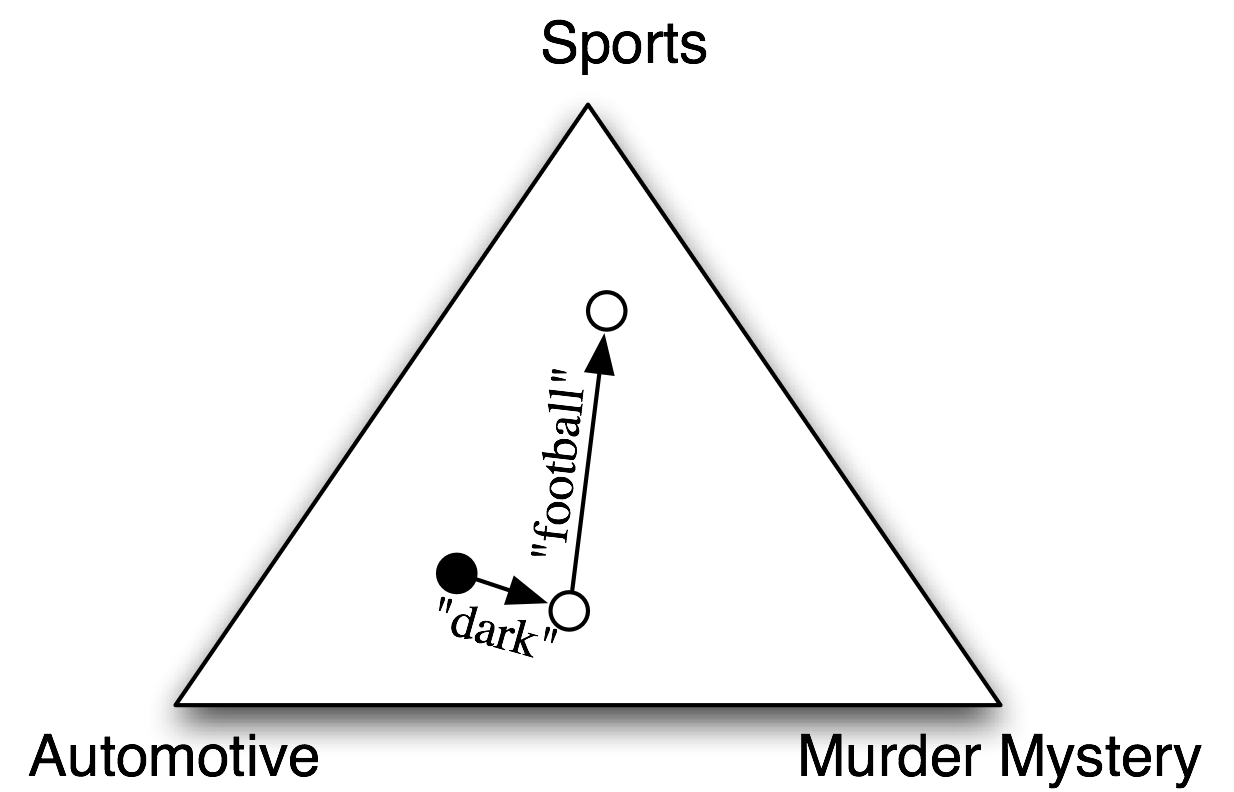
图 5.1:使用朴素贝叶斯分类器为文档选择主题的程序的抽象图解。在训练语料中,大多数文档是有关汽车的,所以分类器从接近“汽车”的标签的点上开始。但它会考虑每个特征的影响。在这个例子中,输入文档中包含的词”dark”,它是谋杀之谜的一个不太强的指标,也包含词”football”,它是体育文档的一个有力指标。每个特征都作出了贡献之后,分类器检查哪个标签最接近,并将该标签分配给输入。
个别特征对整体决策作出自己的贡献,通过“投票反对”那些不经常出现的特征的标签。特别是,每个标签的似然得分由于与输入值具有此特征的标签的概率相乘而减小。例如,如果词 run 在 12%的体育文档中出现,在 10%的谋杀之谜的文档中出现,在 2%的汽车文档中出现,那么体育标签的似然得分将被乘以 0.12,谋杀之谜标签将被乘以 0.1,汽车标签将被乘以 0.02。整体效果是略高于体育标签的得分的谋杀之谜标签的得分会减少,而汽车标签相对于其他两个标签会显著减少。这个过程如5.2和5.3所示。
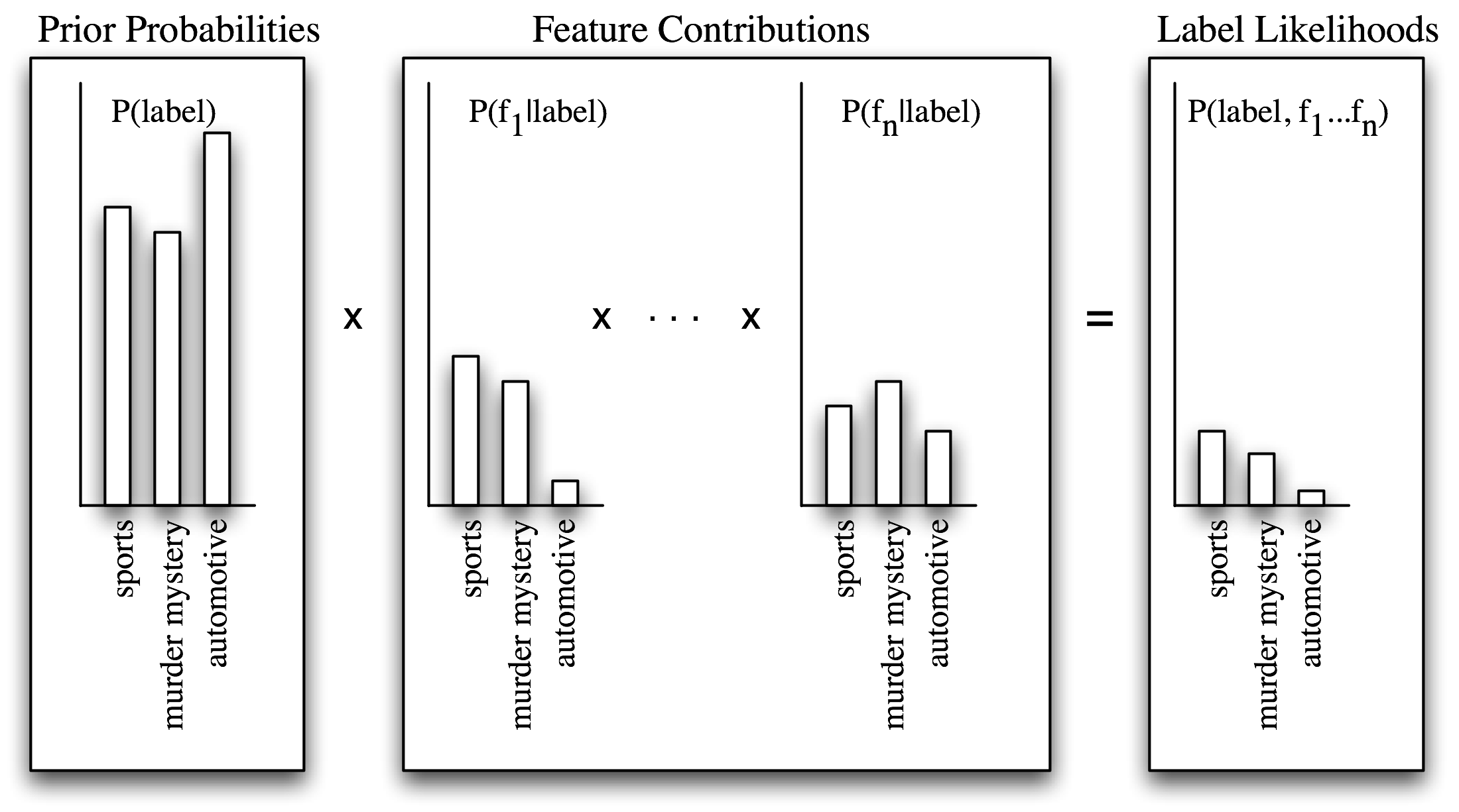
图 5.2:计算朴素贝叶斯的标签似然得分。朴素贝叶斯以计算每个标签的先验概率开始,基于每个标签出现在训练数据中的频率。然后每个特征都用于估计每个标签的似然估计,通过用输入值中有那个特征的标签的概率乘以它。似然得分结果可以认为是从具有给定的标签和特征集的训练集中随机选取的值的概率的估计,假设所有特征概率是独立的。
