 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 3.6 标准和工具
3.6 标准和工具
一个用途广泛的语料库需要支持广泛的格式。然而,NLP 研究的前沿需要各种新定义的没有得到广泛支持的标注。一般情况下,并没有广泛使用的适当的创作、发布和使用语言数据的工具。大多数项目都必须制定它们自己的一套工具,供内部使用,这对缺乏必要的资源的其他人没有任何帮助。此外,我们还没有一个可以胜任的普遍接受的标准来表示语料库的结构和内容。没有这样的标准,就不可能有通用的工具——同时,没有可用的工具,适当的标准也不太可能被开发、使用和接受。
针对这种情况的一个反应就是开拓未来开发一种通用的能充分表现捕获多种标注类型(见8的例子)的格式。NLP 的挑战是编写程序处理这种格式的泛化。例如,如果编程任务涉及树数据,文件格式允许任意有向图,那么必须验证输入数据检查树的属性如根、连通性、无环。如果输入文件包含其他层的标注,该程序将需要知道数据加载时如何忽略它们,将树数据保存到文件时不能否定或抹杀这些层。
另一种反应一直是写一个一次性的脚本来操纵语料格式;这样的脚本将许多 NLP 研究人员的文件夹弄得乱七八糟。在语料格式解析工作应该只进行一次(每编程语言)的前提下,NLTK 中的语料库阅读器是更系统的方法。
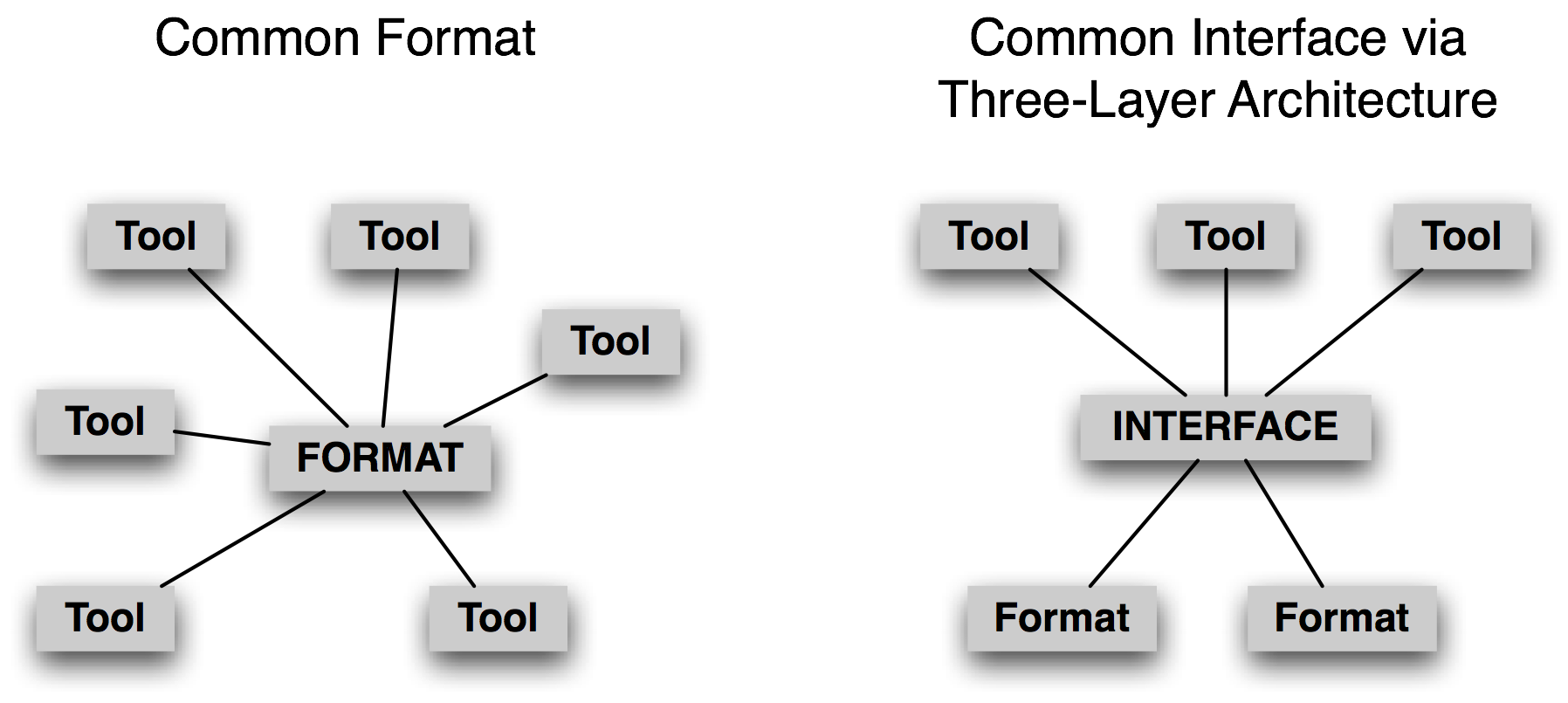
图 3.2:通用格式对比通用接口
不是集中在一种共同的格式,我们认为更有希望开发一种共同的接口(参见nltk.corpus)。思考 NLP 中的一个重要的语料类型 treebanks 的情况。将短语结构树存储在一个文件中的方法很多。我们可以使用嵌套的括号、或嵌套的 XML 元素、或每行带有一个(child-id,parent-id)对的依赖符号、或一个 XML 版本的依赖符号等。然而,每种情况中的逻辑结构几乎是相同的。很容易设计一种共同的接口,使应用程序员编写代码使用如children()、leaves()、depth()等方法来访问树数据。注意这种做法来自计算机科学中已经接受的做法,即即抽象数据类型、面向对象设计、三层结构(3.2)。其中的最后一个——来自关系数据库领域——允许终端用户应用程序使用通用的模型(“关系模型”)和通用的语言(SQL)抽象出文件存储的特质,并允许新的文件系统技术的出现,而不会干扰到终端用户的应用。以同样的方式,一个通用的语料库接口将应用程序从数据格式隔离。
在此背景下,创建和发布一个新的语料库时,尽可能使用现有广泛使用的格式是权宜之计。如果这样不可能,语料库可以带有一些软件——如nltk.corpus模块——支持现有的接口方法。
