 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 1.2 选择正确的特征
1.2 选择正确的特征
选择相关的特征,并决定如何为一个学习方法编码它们,这对学习方法提取一个好的模型可以产生巨大的影响。建立一个分类器的很多有趣的工作之一是找出哪些特征可能是相关的,以及我们如何能够表示它们。虽然使用相当简单而明显的特征集往往可以得到像样的性能,但是使用精心构建的基于对当前任务的透彻理解的特征,通常会显著提高收益。
典型地,特征提取通过反复试验和错误的过程建立的,由哪些信息是与问题相关的直觉指引的。它通常以“厨房水槽”的方法开始,包括你能想到的所有特征,然后检查哪些特征是实际有用的。我们在1.2中对名字性别特征采取这种做法。
def gender_features2(name):features = {}features["first_letter"] = name[0].lower()features["last_letter"] = name[-1].lower()for letter in 'abcdefghijklmnopqrstuvwxyz':features["count({})".format(letter)] = name.lower().count(letter)features["has({})".format(letter)] = (letter in name.lower())return features
然而,你要用于一个给定的学习算法的特征的数目是有限的——如果你提供太多的特征,那么该算法将高度依赖你的训练数据的特性,而一般化到新的例子的效果不会很好。这个问题被称为过拟合,当运作在小训练集上时尤其会有问题。例如,如果我们使用1.2中所示的特征提取器训练朴素贝叶斯分类器,将会过拟合这个相对较小的训练集,造成这个系统的精度比只考虑每个名字最后一个字母的分类器的精度低约 1%:
>>> featuresets = [(gender_features2(n), gender) for (n, gender) in labeled_names]>>> train_set, test_set = featuresets[500:], featuresets[:500]>>> classifier = nltk.NaiveBayesClassifier.train(train_set)>>> print(nltk.classify.accuracy(classifier, test_set))0.768
一旦初始特征集被选定,完善特征集的一个非常有成效的方法是错误分析。首先,我们选择一个开发集,包含用于创建模型的语料数据。然后将这种开发集分为训练集和开发测试集。
>>> train_names = labeled_names[1500:]>>> devtest_names = labeled_names[500:1500]>>> test_names = labeled_names[:500]
训练集用于训练模型,开发测试集用于进行错误分析。测试集用于系统的最终评估。由于下面讨论的原因,我们将一个单独的开发测试集用于错误分析而不是使用测试集是很重要的。在1.3中显示了将语料数据划分成不同的子集。
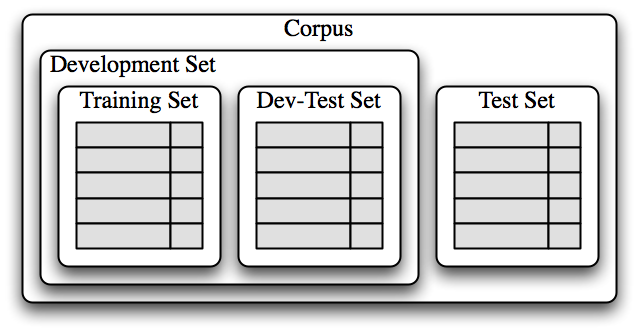
图 1.3:用于训练有监督分类器的语料数据组织图。语料数据分为两类:开发集和测试集。开发集通常被进一步分为训练集和开发测试集。
已经将语料分为适当的数据集,我们使用训练集训练一个模型![[1]](/uploads/projects/1594/65896.jpg) ,然后在开发测试集上运行
,然后在开发测试集上运行![[2]](/uploads/projects/1594/65897.jpg) 。
。
>>> train_set = [(gender_features(n), gender) for (n, gender) in train_names]>>> devtest_set = [(gender_features(n), gender) for (n, gender) in devtest_names]>>> test_set = [(gender_features(n), gender) for (n, gender) in test_names]>>> classifier = nltk.NaiveBayesClassifier.train(train_set) ![[1]](/projects/nlp-py-2e-zh/Images/78bc6ca8410394dcf6910484bc97e2b6.jpg)>>> print(nltk.classify.accuracy(classifier, devtest_set)) ![[2]](/projects/nlp-py-2e-zh/Images/854532b0c5c8869f9012833955e75b20.jpg)0.75
使用开发测试集,我们可以生成一个分类器预测名字性别时的错误列表:
>>> errors = []>>> for (name, tag) in devtest_names:... guess = classifier.classify(gender_features(name))... if guess != tag:... errors.append( (tag, guess, name) )
然后,可以检查个别错误案例,在那里该模型预测了错误的标签,尝试确定什么额外信息将使其能够作出正确的决定(或者现有的哪部分信息导致其做出错误的决定)。然后可以相应的调整特征集。我们已经建立的名字分类器在开发测试语料上产生约 100 个错误:
>>> for (tag, guess, name) in sorted(errors):... print('correct={:<8} guess={:<8s} name={:<30}'.format(tag, guess, name))correct=female guess=male name=Abigail...correct=female guess=male name=Cindelyn...correct=female guess=male name=Katheryncorrect=female guess=male name=Kathryn...correct=male guess=female name=Aldrich...correct=male guess=female name=Mitch...correct=male guess=female name=Rich...
浏览这个错误列表,它明确指出一些多个字母的后缀可以指示名字性别。例如,yn 结尾的名字显示以女性为主,尽管事实上,n 结尾的名字往往是男性;以 ch 结尾的名字通常是男性,尽管以 h 结尾的名字倾向于是女性。因此,调整我们的特征提取器包括两个字母后缀的特征:
>>> def gender_features(word):... return {'suffix1': word[-1:],... 'suffix2': word[-2:]}
使用新的特征提取器重建分类器,我们看到测试数据集上的性能提高了近 3 个百分点(从 76.5%到 78.2%):
>>> train_set = [(gender_features(n), gender) for (n, gender) in train_names]>>> devtest_set = [(gender_features(n), gender) for (n, gender) in devtest_names]>>> classifier = nltk.NaiveBayesClassifier.train(train_set)>>> print(nltk.classify.accuracy(classifier, devtest_set))0.782
这个错误分析过程可以不断重复,检查存在于由新改进的分类器产生的错误中的模式。每一次错误分析过程被重复,我们应该选择一个不同的开发测试/训练分割,以确保该分类器不会开始反映开发测试集的特质。
但是,一旦我们已经使用了开发测试集帮助我们开发模型,关于这个模型在新数据会表现多好,我们将不能再相信它会给我们一个准确地结果。因此,保持测试集分离、未使用过,直到我们的模型开发完毕是很重要的。在这一点上,我们可以使用测试集评估模型在新的输入值上执行的有多好。
