 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 3.8 分割
- 断句
- 分词
3.8 分割
本节将讨论更高级的概念,你在第一次阅读本章时可能更愿意跳过本节。
分词是一个更普遍的分割问题的一个实例。在本节中,我们将看到这个问题的另外两个实例,它们使用与到目前为止我们已经在本章看到的完全不同的技术。
断句
在词级水平处理文本通常假定能够将文本划分成单个句子。正如我们已经看到,一些语料库已经提供句子级别的访问。在下面的例子中,我们计算布朗语料库中每个句子的平均词数:
>>> len(nltk.corpus.brown.words()) / len(nltk.corpus.brown.sents())20.250994070456922
在其他情况下,文本可能只是作为一个字符流。在将文本分词之前,我们需要将它分割成句子。NLTK 通过包含 Punkt 句子分割器(Kiss & Strunk, 2006)使得这个功能便于使用。这里是使用它为一篇小说文本断句的例子。(请注意,如果在你读到这篇文章时分割器内部数据已经更新过,你会看到不同的输出):
>>> text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')>>> sents = nltk.sent_tokenize(text)>>> pprint.pprint(sents[79:89])['"Nonsense!"', 'said Gregory, who was very rational when anyone else\nattempted paradox.', '"Why do all the clerks and navvies in the\n' 'railway trains look so sad and tired, so very sad and tired?', 'I will\ntell you.', 'It is because they know that the train is going right.', 'It\n' 'is because they know that whatever place they have taken a ticket\n' 'for that place they will reach.', 'It is because after they have\n' 'passed Sloane Square they know that the next station must be\n' 'Victoria, and nothing but Victoria.', 'Oh, their wild rapture!', 'oh,\n' 'their eyes like stars and their souls again in Eden, if the next\n' 'station were unaccountably Baker Street!"', '"It is you who are unpoetical," replied the poet Syme.']
请注意,这个例子其实是一个单独的句子,报道 Lucian Gregory 先生的演讲。然而,引用的演讲包含几个句子,这些已经被分割成几个单独的字符串。这对于大多数应用程序是合理的行为。
断句是困难的,因为句号会被用来标记缩写而另一些句号同时标记缩写和句子结束,就像发生在缩写如 U.S.A.上的那样。
断句的另一种方法见2节。
分词
对于一些书写系统,由于没有词的可视边界表示这一事实,文本分词变得更加困难。例如,在中文中,三个字符的字符串:爱国人(ai4 “love” [verb], guo3 “country”,ren2 “person”) 可以被分词为“爱国/人”,“country-loving person”,或者“爱/国人”,“love country-person”。
类似的问题在口语语言处理中也会出现,听者必须将连续的语音流分割成单个的词汇。当我们事先不认识这些词时,这个问题就演变成一个特别具有挑战性的版本。语言学习者会面对这个问题,例如小孩听父母说话。考虑下面的人为构造的例子,单词的边界已被去除:
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy">>> seg1 = "0000000000000001000000000010000000000000000100000000000">>> seg2 = "0100100100100001001001000010100100010010000100010010000"
观察由 0 和 1 组成的分词表示字符串。它们比源文本短一个字符,因为长度为 n 文本可以在 n-1 个地方被分割。3.7中的segment()函数演示了我们可以从这个表示回到初始分词的文本。
def segment(text, segs): words = [] last = 0 for i in range(len(segs)): if segs[i] == '1': words.append(text[last:i+1]) last = i+1 words.append(text[last:]) return words
现在分词的任务变成了一个搜索问题:找到将文本字符串正确分割成词汇的字位串。我们假定学习者接收词,并将它们存储在一个内部词典中。给定一个合适的词典,是能够由词典中的词的序列来重构源文本的。根据(Brent, 1995),我们可以定义一个目标函数,一个打分函数,我们将基于词典的大小和从词典中重构源文本所需的信息量尽力优化它的值。我们在3.8中说明了这些。
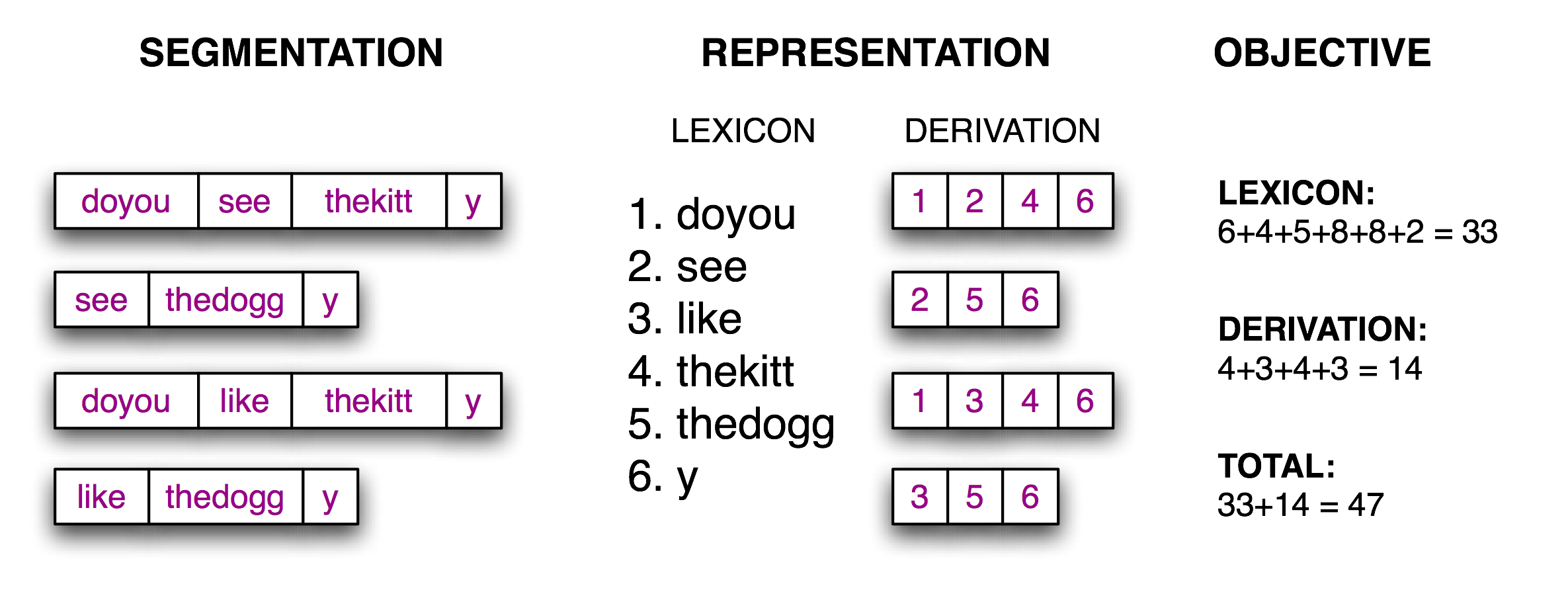
图 3.8:计算目标函数:给定一个假设的源文本的分词(左),推导出一个词典和推导表,它能让源文本重构,然后合计每个词项(包括边界标志)与推导表的字符数,作为分词质量的得分;得分值越小表明分词越好。
实现这个目标函数是很简单的,如例子3.9所示。
def evaluate(text, segs): words = segment(text, segs) text_size = len(words) lexicon_size = sum(len(word) + 1 for word in set(words)) return text_size + lexicon_size
最后一步是寻找最小化目标函数值的 0 和 1 的模式,如3.10所示。请注意,最好的分词包括像 thekitty 这样的“词”,因为数据中没有足够的证据进一步分割这个词。
from random import randintdef flip(segs, pos): return segs[:pos] + str(1-int(segs[pos])) + segs[pos+1:]def flip_n(segs, n): for i in range(n): segs = flip(segs, randint(0, len(segs)-1)) return segsdef anneal(text, segs, iterations, cooling_rate): temperature = float(len(segs)) while temperature > 0.5: best_segs, best = segs, evaluate(text, segs) for i in range(iterations): guess = flip_n(segs, round(temperature)) score = evaluate(text, guess) if score < best: best, best_segs = score, guess score, segs = best, best_segs temperature = temperature / cooling_rate print(evaluate(text, segs), segment(text, segs)) print() return segs
有了足够的数据,就可能以一个合理的准确度自动将文本分割成词汇。这种方法可用于为那些词的边界没有任何视觉表示的书写系统分词。
