 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 4.1 词汇列表语料库
4.1 词汇列表语料库
NLTK 包括一些仅仅包含词汇列表的语料库。词汇语料库是 Unix 中的/usr/share/dict/words文件,被一些拼写检查程序使用。我们可以用它来寻找文本语料中不寻常的或拼写错误的词汇,如4.2所示。
def unusual_words(text):text_vocab = set(w.lower() for w in text if w.isalpha())english_vocab = set(w.lower() for w in nltk.corpus.words.words())unusual = text_vocab - english_vocabreturn sorted(unusual)>>> unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt'))['abbeyland', 'abhorred', 'abilities', 'abounded', 'abridgement', 'abused', 'abuses','accents', 'accepting', 'accommodations', 'accompanied', 'accounted', 'accounts','accustomary', 'aches', 'acknowledging', 'acknowledgment', 'acknowledgments', ...]>>> unusual_words(nltk.corpus.nps_chat.words())['aaaaaaaaaaaaaaaaa', 'aaahhhh', 'abortions', 'abou', 'abourted', 'abs', 'ack','acros', 'actualy', 'adams', 'adds', 'adduser', 'adjusts', 'adoted', 'adreniline','ads', 'adults', 'afe', 'affairs', 'affari', 'affects', 'afk', 'agaibn', 'ages', ...]
还有一个停用词语料库,就是那些高频词汇,如 the,to 和 also,我们有时在进一步的处理之前想要将它们从文档中过滤。停用词通常几乎没有什么词汇内容,而它们的出现会使区分文本变困难。
>>> from nltk.corpus import stopwords>>> stopwords.words('english')['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours','yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers','herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves','what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are','was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does','did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until','while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into','through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down','in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here','there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more','most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so','than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now']
让我们定义一个函数来计算文本中 没有 在停用词列表中的词的比例:
>>> def content_fraction(text):... stopwords = nltk.corpus.stopwords.words('english')... content = [w for w in text if w.lower() not in stopwords]... return len(content) / len(text)...>>> content_fraction(nltk.corpus.reuters.words())0.7364374824583169
因此,在停用词的帮助下,我们筛选掉文本中四分之一的词。请注意,我们在这里结合了两种不同类型的语料库,使用词典资源来过滤文本语料的内容。

图 4.3:一个字母拼词谜题::在由随机选择的字母组成的网格中,选择里面的字母组成词;这个谜题叫做“目标”。
一个词汇列表对解决如图4.3中这样的词的谜题很有用。我们的程序遍历每一个词,对于每一个词检查是否符合条件。检查必须出现的字母![[2]](/uploads/projects/1594/65818.jpg) 和长度限制
和长度限制![[1]](/uploads/projects/1594/65819.jpg) 是很容易的(这里我们只查找 6 个或 6 个以上字母的词)。只使用指定的字母组合作为候选方案,尤其是一些指定的字母出现了两次(这里如字母 v)这样的检查是很棘手的。
是很容易的(这里我们只查找 6 个或 6 个以上字母的词)。只使用指定的字母组合作为候选方案,尤其是一些指定的字母出现了两次(这里如字母 v)这样的检查是很棘手的。FreqDist比较法![[3]](/uploads/projects/1594/65820.jpg) 允许我们检查每个 字母 在候选词中的频率是否小于或等于相应的字母在拼词谜题中的频率。
允许我们检查每个 字母 在候选词中的频率是否小于或等于相应的字母在拼词谜题中的频率。
>>> puzzle_letters = nltk.FreqDist('egivrvonl')>>> obligatory = 'r'>>> wordlist = nltk.corpus.words.words()>>> [w for w in wordlist if len(w) >= 6 ![[1]](/projects/nlp-py-2e-zh/Images/eeff7ed83be48bf40aeeb3bf9db5550e.jpg)... and obligatory in w ![[2]](/projects/nlp-py-2e-zh/Images/6efeadf518b11a6441906b93844c2b19.jpg)... and nltk.FreqDist(w) <= puzzle_letters] ![[3]](/projects/nlp-py-2e-zh/Images/e941b64ed778967dd0170d25492e42df.jpg)['glover', 'gorlin', 'govern', 'grovel', 'ignore', 'involver', 'lienor','linger', 'longer', 'lovering', 'noiler', 'overling', 'region', 'renvoi','revolving', 'ringle', 'roving', 'violer', 'virole']
另一个词汇列表是名字语料库,包括 8000 个按性别分类的名字。男性和女性的名字存储在单独的文件中。让我们找出同时出现在两个文件中的名字,即性别暧昧的名字:
>>> names = nltk.corpus.names>>> names.fileids()['female.txt', 'male.txt']>>> male_names = names.words('male.txt')>>> female_names = names.words('female.txt')>>> [w for w in male_names if w in female_names]['Abbey', 'Abbie', 'Abby', 'Addie', 'Adrian', 'Adrien', 'Ajay', 'Alex', 'Alexis','Alfie', 'Ali', 'Alix', 'Allie', 'Allyn', 'Andie', 'Andrea', 'Andy', 'Angel','Angie', 'Ariel', 'Ashley', 'Aubrey', 'Augustine', 'Austin', 'Averil', ...]
正如大家都知道的,以字母 a 结尾的名字几乎都是女性。我们可以在4.4中看到这一点以及一些其它的模式,该图是由下面的代码产生的。请记住name[-1]是name的最后一个字母。
>>> cfd = nltk.ConditionalFreqDist(... (fileid, name[-1])... for fileid in names.fileids()... for name in names.words(fileid))>>> cfd.plot()
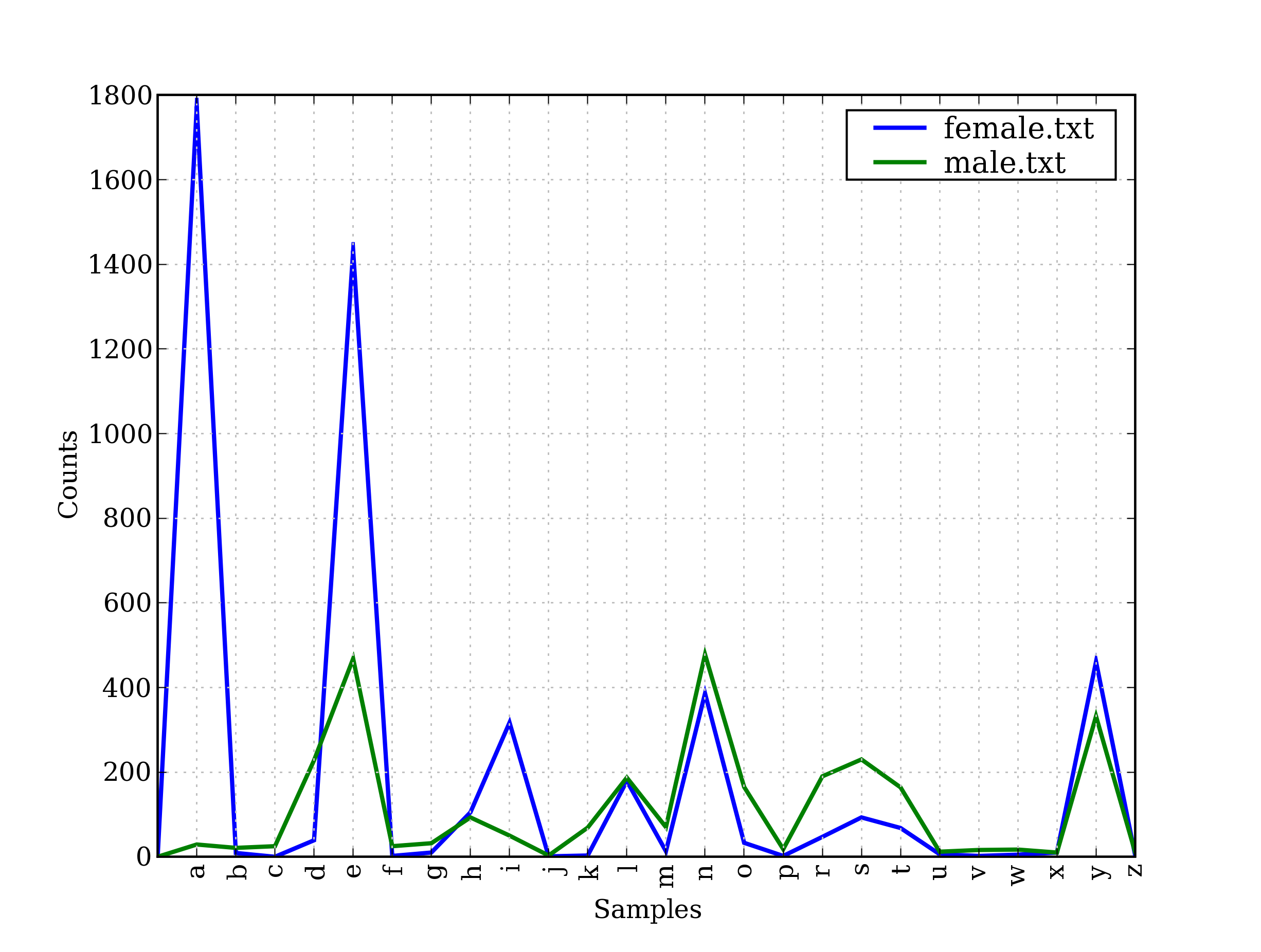
图 4.4:条件频率分布:此图显示男性和女性名字的结尾字母;大多数以 a,e 或 i 结尾的名字是女性;以 h 和 l 结尾的男性和女性同样多;以 k, o, r, s 和 t 结尾的更可能是男性。
