 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 2.3 维护与演变
2.3 维护与演变
随着大型语料库的发布,研究人员立足于均衡的从为完全不同的目的而创建的语料库中派生出的子集进行调查的可能性越来越大。例如,Switchboard 数据库,最初是为识别说话人的研究而收集的,已被用作语音识别、单词发音、口吃、句法、语调和段落结构研究的基础。重用语言语料库的动机包括希望节省时间和精力,希望在别人可以复制的材料上工作,有时希望研究语言行为的更加自然的形式。为这样的研究选择子集的过程本身可视为一个不平凡的贡献。
除了选择语料库的适当的子集,这个新的工作可能包括重新格式化文本文件(如转换为 XML),重命名文件,重新为文本分词,选择数据的一个子集来充实等等。多个研究小组可以独立的做这项工作,如2.2所示。在以后的日子,应该有人想要组合不同的版本的源数据,这项任务可能会非常繁重。
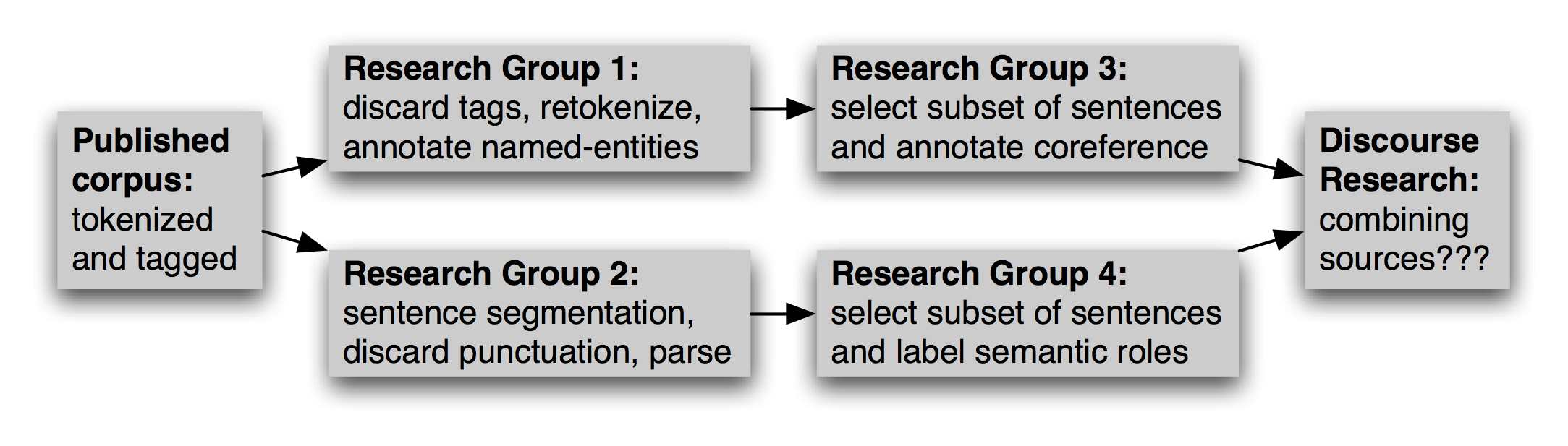
图 2.2:语料库随着时间的推移而演变:语料库发布后,研究小组将独立的使用它,选择和丰富不同的部分;然后研究努力整合单独的标注,面临校准注释的艰巨的挑战。
由于缺乏有关派生的版本如何创建的,哪个版本才是最新的等记录,使用派生的语料库的任务变得更加困难。
这种混乱情况的改进方法是集中维护语料库,专家委员会定期修订和扩充它,考虑第三方的意见,不时发布的新版本。出版字典和国家语料库可能以这种方式集中维护。然而,对于大多数的语料库,这种模式是完全不切实际的。
原始语料库的出版的一个中间过程是要有一个能识别其中任何一部分的规范。每个句子、树、或词条都有一个全局的唯一标识符,每个词符、节点或字段(分别)都有一个相对偏移。标注,包括分割,可以使用规范的标识符(一个被称为对峙注释的方法)引用源材料。这样,新的标注可以与源材料独立分布,同一来源的多个独立标注可以对比和更新而不影响源材料。
如果语料库出版提供了多个版本,版本号或日期可以是识别规范的一部分。整个语料的版本标识符之间的对应表,将使任何对峙的注释更容易被更新。
小心!
有时一个更新的语料包含对一直在外部标注的基本材料的修正。词符可能会被分拆或合并,成分可能已被重新排列。新老标识符之间可能不会一一对应。使对峙标注打破新版本的这些组件比默默允许其标识符指向不正确的位置要好。
