 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 1.3 搜索文本
1.3 搜索文本
除了阅读文本之外,还有很多方法可以用来研究文本内容。词语索引视角显示一个指定单词的每一次出现,连同一些上下文一起显示。下面我们输入text1 后面跟一个点,再输入函数名concordance,然后将"monstrous" 放在括号里,来查一下 Moby Dick 《白鲸记》中的词 monstrous:
>>> text1.concordance("monstrous")Displaying 11 of 11 matches:ong the former , one was of a most monstrous size . ... This came towards us ,ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have rll over with a heathenish array of monstrous clubs and spears . Some were thickd as you gazed , and wondered what monstrous cannibal and savage could ever havthat has survived the flood ; most monstrous and most mountainous ! That Himmalthey might scout at Moby Dick as a monstrous fable , or still worse and more deth of Radney .'" CHAPTER 55 Of the monstrous Pictures of Whales . I shall ere ling Scenes . In connexion with the monstrous pictures of whales , I am stronglyere to enter upon those still more monstrous stories of them which are to be foght have been rummaged out of this monstrous cabinet there is no telling . Butof Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u>>>
在一段特定的文本上第一次使用 concordance 会花费一点时间来构建索引,因此接下来的搜索会很快。
注意
轮到你来: 尝试搜索其他词;为了方便重复输入,你也许会用到上箭头,Ctrl-上箭头或者 Alt-p 获取之前输入的命令,然后修改要搜索的词。你也可以在我们包含的其他文本上搜索。例如, 使用text2.concordance("affection"),搜索 Sense and Sensibility《理智与情感》中的 affection。使用text3.concordance("lived") 搜索 Genesis《创世纪》找出某人活了多久。你也可以看看text4,Inaugural Address Corpus《就职演说语料》,回到 1789 年看看那时英语的例子,搜索如 nation, terror,god 这样的词,看看随着时间推移这些词的使用如何不同。我们也包括了text5,NPS Chat Corpus《NPS 聊天语料库》:你可以在里面搜索一些网络词,如 im ur,lol。(注意这个语料库未经审查!)
在你花了一小会儿研究这些文本之后,我们希望你对语言的丰富性和多样性有一个新的认识。在下一章中,你将学习获取更广泛的文本,包括英语以外其他语言的文本。
词语索引使我们看到词的上下文。例如,我们看到 monstrous 出现的上下文, the pictures 和 a size。还有哪些词出现在相似的上下文中?我们可以通过在被查询的文本名后添加函数名similar,然后在括号中插入相关的词来查找到:
>>> text1.similar("monstrous")mean part maddens doleful gamesome subtly uncommon careful untowardexasperate loving passing mouldy christian few true mystifyingimperial modifies contemptible>>> text2.similar("monstrous")very heartily so exceedingly remarkably as vast a great amazinglyextremely good sweet>>>
观察我们从不同的文本中得到的不同结果。Austen 使用这些词与 Melville 完全不同;在她那里,monstrous 是正面的意思,有时它的功能像词 very 一样作强调成分。
函数common_contexts允许我们研究两个或两个以上的词共同的上下文,如 monstrous 和 very。我们必须用方括号和圆括号把这些词括起来,中间用逗号分割:
>>> text2.common_contexts(["monstrous", "very"])a_pretty is_pretty am_glad be_glad a_lucky>>>
注意
轮到你来: 挑选另一对词,使用similar() 和common_contexts() 函数比较它们在两个不同文本中的用法。
自动检测出现在文本中的特定的词,并显示同样上下文中出现的一些词,这只是一个方面。我们也可以判断词在文本中的 位置 :从文本开头算起在它前面有多少词。这个位置信息可以用离散图表示。每一个竖线代表一个单词,每一行代表整个文本。在1.2 中,我们看到在过去 220 年中的一些显著的词语用法模式(在一个由就职演说语料首尾相连的人为组合的文本中)。可以用下面的方法画出这幅图。你也许会想尝试更多的词(如,liberty,constitution)和不同的文本。你能在看到这幅图之前预测一个词的分布吗?跟以前一样,请保证引号、逗号、中括号及小括号的使用完全正确。
>>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])>>>
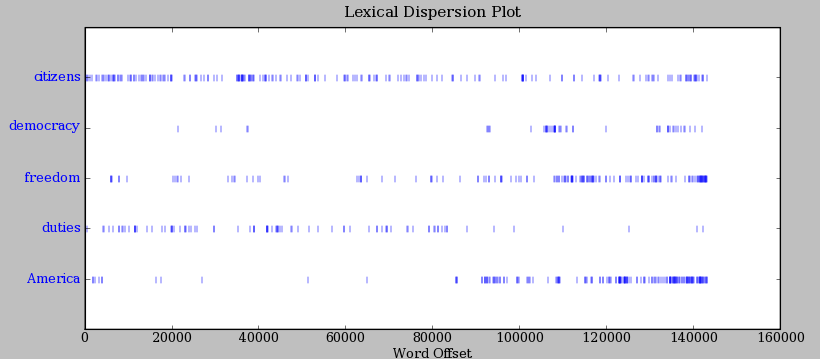
图 1.2:美国总统就职演说词汇分布图:可以用来研究随时间推移语言使用上的变化。
注意
重要事项: 为了画出这本书中用到的图形,你需要安装 Python 的 NumPy 和 Matplotlib 包。请参阅http://nltk.org/ 上的安装说明。
注意
你还可以使用https://books.google.com/ngrams 画出词汇随着时间的使用频率。
现在轻松一下,让我们尝试产生一些刚才看到的不同风格的随机文本。要做到这一点,我们需要输入文本的名字后面跟函数名generate。(需要带括号,但括号里没有也什么。)
>>> text3.generate()In the beginning of his brother is a hairy man , whose top may reachunto heaven ; and ye shall sow the land of Egypt there was no bread inall that he was taken out of the month , upon the earth . So shall thywages be ? And they made their father ; and Isaac was old , and kissedhim : and Laban with his cattle in the midst of the hands of Esau thyfirst born , and Phichol the chief butler unto his son Isaac , she>>>
Note
generate() 方法在 NLTK 3.0 中不可用,但会在后续版本中恢复。
