 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 4 决策树
4 决策树
接下来的三节中,我们将仔细看看可用于自动生成分类模型的三种机器学习方法:决策树、朴素贝叶斯分类器和最大熵分类器。正如我们所看到的,可以把这些学习方法看作黑盒子,直接训练模式,使用它们进行预测而不需要理解它们是如何工作的。但是,仔细看看这些学习方法如何基于一个训练集上的数据选择模型,会学到很多。了解这些方法可以帮助指导我们选择相应的特征,尤其是我们关于那些特征如何编码的决定。理解生成的模型可以让我们更好的提取信息,哪些特征对有信息量,那些特征之间如何相互关联。
决策树是一个简单的为输入值选择标签的流程图。这个流程图由检查特征值的决策节点和分配标签的叶节点组成。为输入值选择标签,我们以流程图的初始决策节点开始,称为其根节点。此节点包含一个条件,检查输入值的特征之一,基于该特征的值选择一个分支。沿着这个描述我们输入值的分支,我们到达了一个新的决策节点,有一个关于输入值的特征的新的条件。我们继续沿着每个节点的条件选择的分支,直到到达叶节点,它为输入值提供了一个标签。4.1显示名字性别任务的决策树模型的例子。
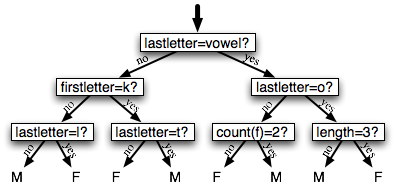
图 4.1:名字性别任务的决策树模型。请注意树图按照习惯画出“颠倒的”,根在上面,叶子在下面。
一旦我们有了一个决策树,就可以直接用它来分配标签给新的输入值。不那么直接的是我们如何能够建立一个模拟给定的训练集的决策树。但在此之前,我们看一下建立决策树的学习算法,思考一个简单的任务:为语料库选择最好的“决策树桩”。决策树桩是只有一个节点的决策树,基于一个特征决定如何为输入分类。每个可能的特征值一个叶子,为特征有那个值的输入指定类标签。要建立决策树桩,我们首先必须决定哪些特征应该使用。最简单的方法是为每个可能的特征建立一个决策树桩,看哪一个在训练数据上得到最高的准确度,也有其他的替代方案,我们将在下面讨论。一旦我们选择了一个特征,就可以通过分配一个标签给每个叶子,基于在训练集中所选的例子的最频繁的标签,建立决策树桩(即选择特征具有那个值的例子)。
给出了选择决策树桩的算法,生长出较大的决策树的算法就很简单了。首先,我们选择分类任务的整体最佳的决策树桩。然后,我们在训练集上检查每个叶子的准确度。没有达到足够的准确度的叶片被新的决策树桩替换,新决策树桩是在根据到叶子的路径选择的训练语料的子集上训练的。例如,我们可以使4.1中的决策树生长,通过替换最左边的叶子为新的决策树桩,这个新的决策树桩是在名字不以”k”开始或以一个元音或”l”结尾的训练集的子集上训练的。
