 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 1.2 NLTK 入门
1.2 NLTK 入门
在进一步深入之前,应先安装 NLTK 3.0,可以从http://nltk.org/ 免费下载。按照说明下载适合你的操作系统的版本。
安装完 NLTK 之后,像前面那样启动 Python 解释器,在 Python 提示符后面输入下面两个命令来安装本书所需的数据,然后选择book集合,如1.1所示。
>>> import nltk>>> nltk.download()
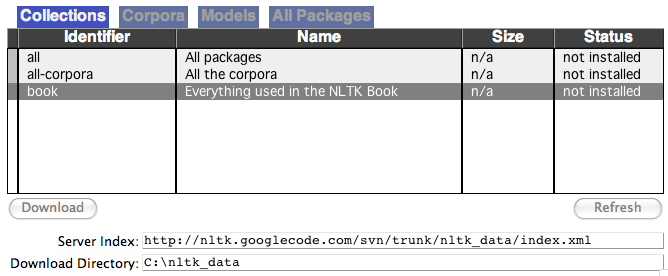
图 1.1:下载 NLTK Book 集:使用nltk.download() 浏览可用的软件包.下载器上Collections 选项卡显示软件包如何被打包分组,选择book 标记所在行,可以获取本书的例子和练习所需的全部数据。这些数据包括约 30 个压缩文件,需要 100MB 硬盘空间。完整的数据集(即下载器中的all)在本书写作期间大约是这个大小的 10 倍,还在不断扩充。
一旦数据被下载到你的机器,你就可以使用 Python 解释器加载其中一些。第一步是在 Python 提示符后输入一个特殊的命令,告诉解释器去加载一些我们要用的文本:from nltk.book import * 。这条语句是说“从 NLTK 的book 模块加载所有的东西”。这个book 模块包含你阅读本章所需的所有数据。。在输出欢迎信息之后,将会加载几本书的文本(这将需要几秒钟)。下面连同你将看到的输出一起再次列出这条命令。注意拼写和标点符号的正确性,记住不要输入>>>。
>>> from nltk.book import **** Introductory Examples for the NLTK Book ***Loading text1, ..., text9 and sent1, ..., sent9Type the name of the text or sentence to view it.Type: 'texts()' or 'sents()' to list the materials.text1: Moby Dick by Herman Melville 1851text2: Sense and Sensibility by Jane Austen 1811text3: The Book of Genesistext4: Inaugural Address Corpustext5: Chat Corpustext6: Monty Python and the Holy Grailtext7: Wall Street Journaltext8: Personals Corpustext9: The Man Who Was Thursday by G . K . Chesterton 1908>>>
任何时候我们想要找到这些文本,只需要在 Python 提示符后输入它们的名字:
>>> text1<Text: Moby Dick by Herman Melville 1851>>>> text2<Text: Sense and Sensibility by Jane Austen 1811>>>>
现在我们可以和这些数据一起来使用 Python 解释器,我们已经准备好上手了。
