 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 5.3 一般的 N-gram 标注
5.3 一般的 N-gram 标注
在基于一元处理一个语言处理任务时,我们使用上下文中的一个项目。标注的时候,我们只考虑当前的词符,与更大的上下文隔离。给定一个模型,我们能做的最好的是为每个词标注其 先验的 最可能的标记。这意味着我们将使用相同的标记标注一个词,如 wind,不论它出现的上下文是 the wind 还是 to wind。
一个 n-gram tagger 标注器是一个一元标注器的一般化,它的上下文是当前词和它前面 n-1 个标识符的词性标记,如图5.1所示。要选择的标记是圆圈里的 t<sub>n</sub>,灰色阴影的是上下文。在5.1所示的 n-gram 标注器的例子中,我们让 n=3;也就是说,我们考虑当前词的前两个词的标记。一个 n-gram 标注器挑选在给定的上下文中最有可能的标记。
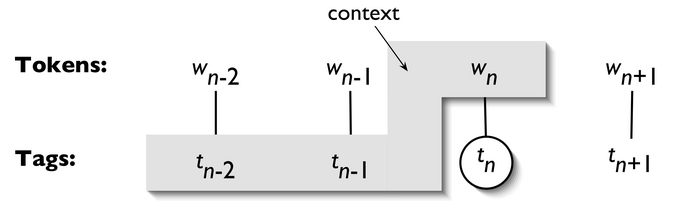
图 5.1:标注器上下文
注意
1-gram 标注器是一元标注器另一个名称:即用于标注一个词符的上下文的只是词符本身。2-gram 标注器也称为 二元标注器 ,3-gram 标注器也称为 三元标注器 。
NgramTagger类使用一个已标注的训练语料库来确定对每个上下文哪个词性标记最有可能。这里我们看 n-gram 标注器的一个特殊情况,二元标注器。首先,我们训练它,然后用它来标注未标注的句子:
>>> bigram_tagger = nltk.BigramTagger(train_sents)>>> bigram_tagger.tag(brown_sents[2007])[('Various', 'JJ'), ('of', 'IN'), ('the', 'AT'), ('apartments', 'NNS'),('are', 'BER'), ('of', 'IN'), ('the', 'AT'), ('terrace', 'NN'),('type', 'NN'), (',', ','), ('being', 'BEG'), ('on', 'IN'), ('the', 'AT'),('ground', 'NN'), ('floor', 'NN'), ('so', 'CS'), ('that', 'CS'),('entrance', 'NN'), ('is', 'BEZ'), ('direct', 'JJ'), ('.', '.')]>>> unseen_sent = brown_sents[4203]>>> bigram_tagger.tag(unseen_sent)[('The', 'AT'), ('population', 'NN'), ('of', 'IN'), ('the', 'AT'), ('Congo', 'NP'),('is', 'BEZ'), ('13.5', None), ('million', None), (',', None), ('divided', None),('into', None), ('at', None), ('least', None), ('seven', None), ('major', None),('``', None), ('culture', None), ('clusters', None), ("''", None), ('and', None),('innumerable', None), ('tribes', None), ('speaking', None), ('400', None),('separate', None), ('dialects', None), ('.', None)]
请注意,二元标注器能够标注训练中它看到过的句子中的所有词,但对一个没见过的句子表现很差。只要遇到一个新词(如 13.5),就无法给它分配标记。它不能标注下面的词(如 million),即使是在训练过程中看到过的,只是因为在训练过程中从来没有见过它前面有一个None标记的词。因此,标注器标注句子的其余部分也失败了。它的整体准确度得分非常低:
>>> bigram_tagger.evaluate(test_sents)0.102063...
当 n 越大,上下文的特异性就会增加,我们要标注的数据中包含训练数据中不存在的上下文的几率也增大。这被称为 数据稀疏 问题,在 NLP 中是相当普遍的。因此,我们的研究结果的精度和覆盖范围之间需要有一个权衡(这与信息检索中的精度/召回权衡有关)。
小心!
N-gram 标注器不应考虑跨越句子边界的上下文。因此,NLTK 的标注器被设计用于句子列表,其中一个句子是一个词列表。在一个句子的开始,t<sub>n-1</sub>和前面的标记被设置为None。
