 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 1.6 标注文本语料库
1.6 标注文本语料库
许多文本语料库都包含语言学标注,有词性标注、命名实体、句法结构、语义角色等。NLTK 中提供了很方便的方式来访问这些语料库中的几个,还有一个包含语料库和语料样本的数据包,用于教学和科研的话可以免费下载。表1.2列出了其中一些语料库。有关下载信息请参阅http://nltk.org/data。关于如何访问 NLTK 语料库的其它例子,请在http://nltk.org/howto查阅语料库的 HOWTO。
表 1.2:
NLTK 中的一些语料库和语料库样本:关于下载和使用它们,请参阅 NLTK 网站的信息。
>>> nltk.corpus.cess_esp.words()['El', 'grupo', 'estatal', 'Electricit\xe9_de_France', ...]>>> nltk.corpus.floresta.words()['Um', 'revivalismo', 'refrescante', 'O', '7_e_Meio', ...]>>> nltk.corpus.indian.words('hindi.pos')['पूर्ण', 'प्रतिबंध', 'हटाओ', ':', 'इराक', 'संयुक्त', ...]>>> nltk.corpus.udhr.fileids()['Abkhaz-Cyrillic+Abkh', 'Abkhaz-UTF8', 'Achehnese-Latin1', 'Achuar-Shiwiar-Latin1','Adja-UTF8', 'Afaan_Oromo_Oromiffa-Latin1', 'Afrikaans-Latin1', 'Aguaruna-Latin1','Akuapem_Twi-UTF8', 'Albanian_Shqip-Latin1', 'Amahuaca', 'Amahuaca-Latin1', ...]>>> nltk.corpus.udhr.words('Javanese-Latin1')[11:]['Saben', 'umat', 'manungsa', 'lair', 'kanthi', 'hak', ...]
这些语料库的最后,udhr,是超过 300 种语言的世界人权宣言。这个语料库的 fileids 包括有关文件所使用的字符编码,如UTF8或者Latin1。让我们用条件频率分布来研究udhr语料库中不同语言版本中的字长差异。图1.2 中所示的输出(自己运行程序可以看到一个彩色图)。注意,True和False是 Python 内置的布尔值。
>>> from nltk.corpus import udhr>>> languages = ['Chickasaw', 'English', 'German_Deutsch',... 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']>>> cfd = nltk.ConditionalFreqDist(... (lang, len(word))... for lang in languages... for word in udhr.words(lang + '-Latin1'))>>> cfd.plot(cumulative=True)
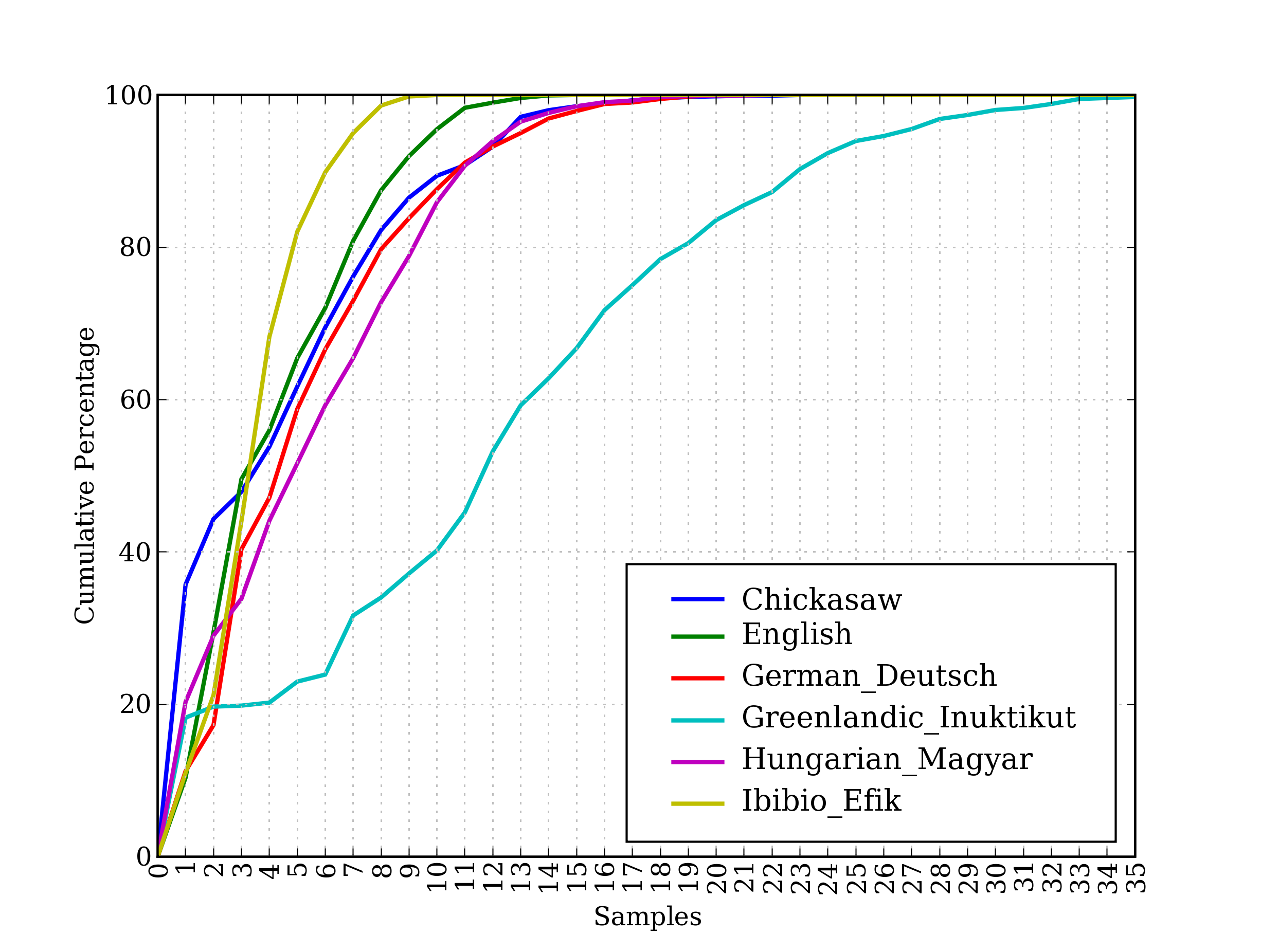
图 1.2:累积字长分布:世界人权宣言的 6 个翻译版本;此图显示,5 个或 5 个以下字母组成的词在 Ibibio 语言的文本中占约 80%,在德语文本中占 60%,在 Inuktitut 文本中占 25%。
注意
轮到你来:在udhr.fileids()中选择一种感兴趣的语言,定义一个变量raw_text = udhr.raw(Language-Latin1)。使用nltk.FreqDist(raw_text).plot()画出此文本的字母频率分布图。
不幸的是,许多语言没有大量的语料库。通常是政府或工业对发展语言资源的支持不够,个人的努力是零碎的,难以发现或重用。有些语言没有既定的书写系统,或濒临灭绝。(见第7节有关如何寻找语言资源的建议。)
