 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 4.2 移进-归约分析
4.2 移进-归约分析
一种简单的自下而上分析器是移进-归约分析器。与所有自下而上的分析器一样,移进-归约分析器尝试找到对应文法生产式 右侧 的词和短语的序列,用左侧的替换它们,直到整个句子归约为一个S。
移位-规约分析器反复将下一个输入词推到堆栈(4.1);这是移位操作。如果堆栈上的前 n 项,匹配一些产生式的右侧的 n 个项目,那么就把它们弹出栈,并把产生式左边的项目压入栈。这种替换前 n 项为一项的操作就是规约操作。此操作只适用于堆栈的顶部;规约栈中的项目必须在后面的项目被压入栈之前做。当所有的输入都使用过,堆栈中只剩余一个项目,也就是一颗分析树作为它的根的S节点时,分析器完成。移位-规约分析器通过上述过程建立一颗分析树。每次弹出堆栈 n 个项目,它就将它们组合成部分的分析树,然后将这压回推栈。我们可以使用图形化示范nltk.app.srparser()看到移位-规约分析算法步骤。执行此分析器的六个阶段,如4.2所示。
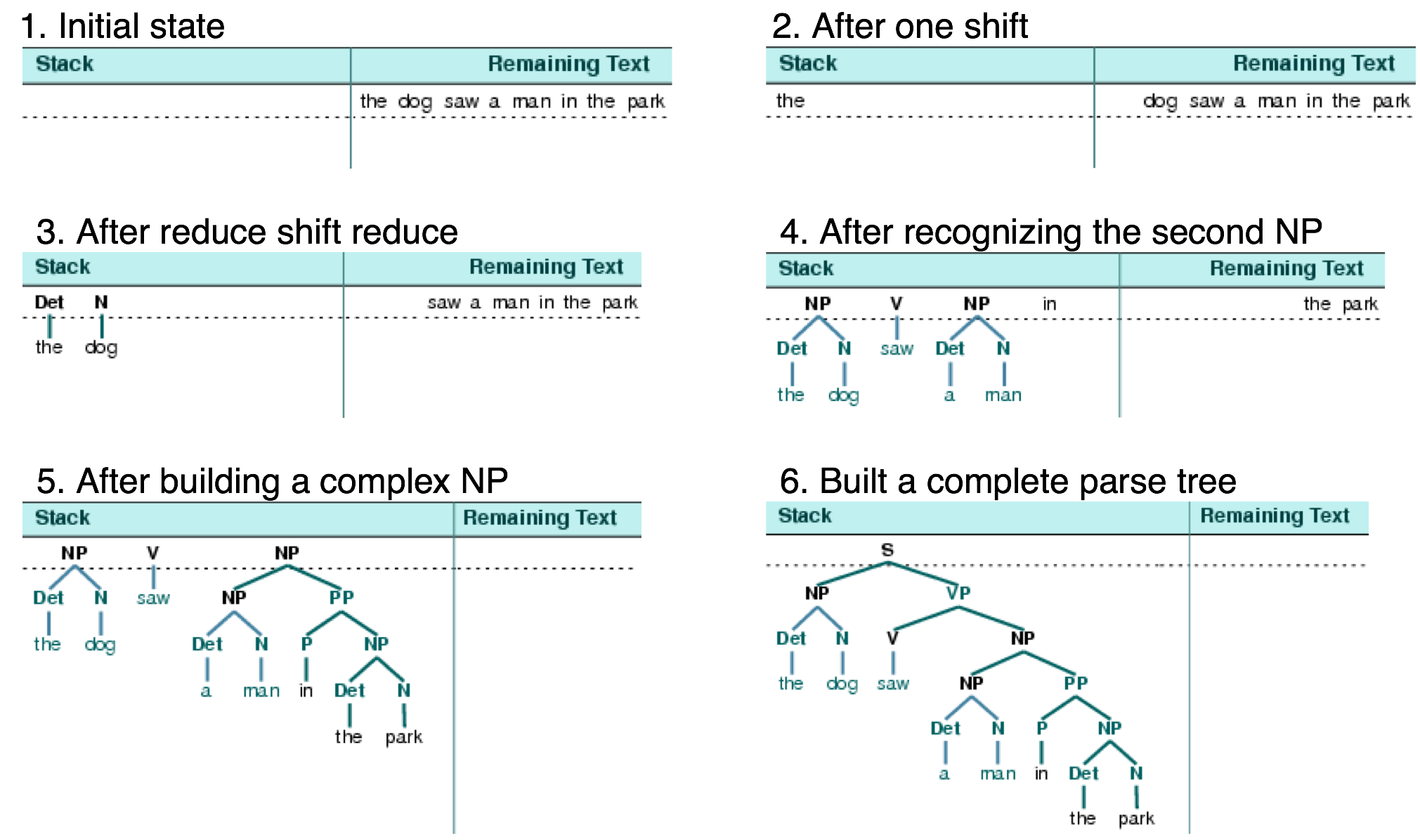
图 4.2:移进-归约分析器的六个阶段:分析器一开始把输入的第一个词转移到堆栈;一旦堆栈顶端的项目与一个文法产生式的右侧匹配,就可以将它们用那个产生式的左侧替换;当所有输入都被使用过且堆栈中只有剩余一个项目S时,分析成功。
NLTK 中提供ShiftReduceParser(),移进-归约分析器的一个简单的实现。这个分析器不执行任何回溯,所以它不能保证一定能找到一个文本的解析,即使确实存在一个这样的解析。此外,它最多只会找到一个解析,即使有多个解析存在。我们可以提供一个可选的trace参数,控制分析器报告它分析一个文本的步骤的繁琐程度。
>>> sr_parser = nltk.ShiftReduceParser(grammar1)>>> sent = 'Mary saw a dog'.split()>>> for tree in sr_parser.parse(sent):... print(tree)(S (NP Mary) (VP (V saw) (NP (Det a) (N dog))))
注意
轮到你来: 以跟踪模式运行上述分析器,看看序列的移进和规约操作,使用sr_parse = nltk.ShiftReduceParser(grammar1, trace=2)。
移进-规约分析器可能会到达一个死胡同,而不能找到任何解析,即使输入的句子是符合语法的。这种情况发生时,没有剩余的输入,而堆栈包含不能被规约到一个S的项目。问题出现的原因是较早前做出的选择不能被分析器撤销(虽然图形演示中用户可以撤消它们的选择)。分析器可以做两种选择:(a)当有多种规约可能时选择哪个规约(b)当移进和规约都可以时选择哪个动作。
移进-规约分析器可以改进执行策略来解决这些冲突。例如,它可以通过只有在不能规约时才移进,解决移进-规约冲突;它可以通过优先执行规约操作,解决规约-规约冲突;它可以从堆栈移除更多的项目。(一个通用的移进-规约分析器,是一个“超前 LR 分析器”,普遍使用在编程语言编译器中。)
移进-规约分析器相比递归下降分析器的好处是,它们只建立与输入中的词对应的结构。此外,每个结构它们只建立一次,例如NP(Det(the), N(man))只建立和压入栈一次,不管以后VP -> V NP PP规约或者NP -> NP PP规约会不会用到。
