 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 4.7 算法设计
- 递归
- 权衡空间与时间
- 动态规划
- NetworkX
- csv
- NumPy
- 其他 Python 库
4.7 算法设计
本节将讨论更高级的概念,你在第一次阅读本章时可能更愿意跳过本节。
解决算法问题的一个重要部分是为手头的问题选择或改造一个合适的算法。有时会有几种选择,能否选择最好的一个取决于对每个选择随数据增长如何执行的知识。关于这个话题的书很多,我们只介绍一些关键概念和精心描述在自然语言处理中最普遍的做法。
最有名的策略被称为分而治之。我们解决一个大小为 n 的问题通过将其分成两个大小为 n/2 的问题,解决这些问题,组合它们的结果成为原问题的结果。例如,假设我们有一堆卡片,每张卡片上写了一个词。我们可以排序这一堆卡片,通过将它分成两半分别给另外两个人来排序(他们又可以做同样的事情)。然后,得到两个排好序的卡片堆,将它们并成一个单一的排序堆就是一项容易的任务了。参见4.8这个过程的说明。
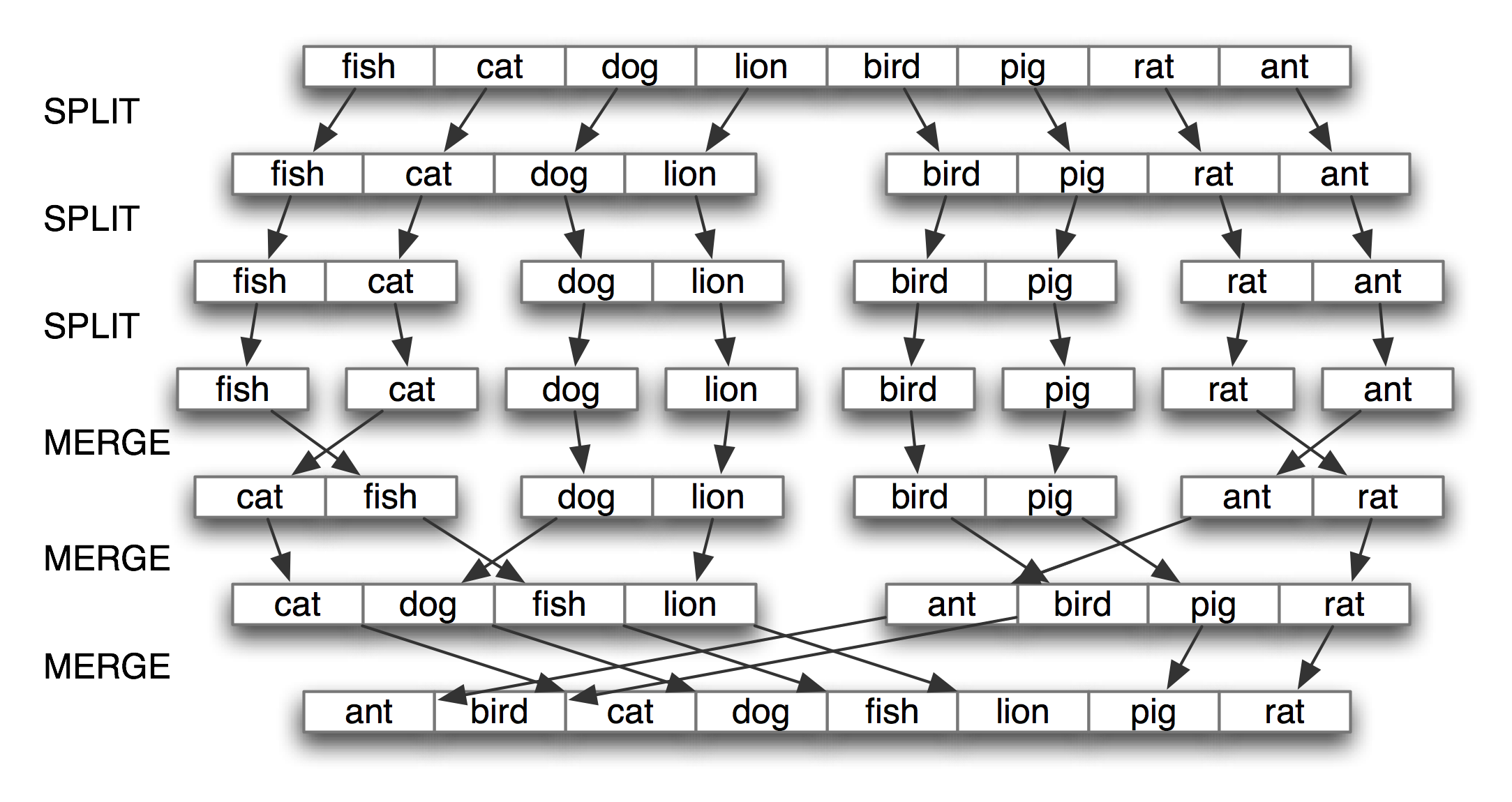
图 4.8:通过分而治之排序:对一个数组排序,我们将其分成两半并对每一半进行排序(递归);将每个排好序的一半合并成一个完整的链表(再次递归);这个算法被称为“归并排序“。
另一个例子是在词典中查找一个词的过程。我们打开在书的中部附近的一个地方,比较我们的词与当前页面上的词。如果它在词典中的词前面,我们就在词典的前一半重复上面的过程;如果它在后面,我们就使用词典的后一半。这种搜索方法被称为二分查找,因为它的每一步都将问题分裂成一半。
算法设计的另一种方法,我们解决问题通过将它转化为一个我们已经知道如何解决的问题的一个实例。例如,为了检测列表中的重复项,我们可以预排序这个列表,然后通过一次扫描检查是否有相邻的两个元素是相同的。
递归
上面的关于排序和搜索的例子有一个引人注目的特征:解决一个大小为 n 的问题,可以将其分成两半,然后处理一个或多个大小为 n/2 的问题。实现这种方法的一种常见方式是使用递归。我们定义一个函数 f,从而简化了问题,并调用自身来解决一个或多个同样问题的更简单的实例。然后组合它们的结果成为原问题的解答。
例如,假设我们有 n 个词,要计算出它们结合在一起有多少不同的方式能组成一个词序列。如果我们只有一个词(n=1),只是一种方式组成一个序列。如果我们有 2 个词,就有 2 种方式将它们组成一个序列。3 个词有 6 种可能性。一般的,n 个词有 n × n-1 × … × 2 × 1 种方式(即 n 的阶乘)。我们可以将这些编写成如下代码:
>>> def factorial1(n):... result = 1... for i in range(n):... result *= (i+1)... return result
但是,也可以使用一种递归算法来解决这个问题,该算法基于以下观察。假设我们有办法为 n-1 不同的词构建所有的排列。然后对于每个这样的排列,有 n 个地方我们可以插入一个新词:开始、结束或任意两个词之间的 n-2 个空隙。因此,我们简单的将 n-1 个词的解决方案数乘以 n 的值。我们还需要基础案例,也就是说,如果我们有一个词,只有一个顺序。我们可以将这些编写成如下代码:
>>> def factorial2(n):... if n == 1:... return 1... else:... return n * factorial2(n-1)
这两种算法解决同样的问题。一个使用迭代,而另一个使用递归。我们可以用递归处理深层嵌套的对象,例如 WordNet 的上位词层次。让我们计数给定同义词集 s 为根的上位词层次的大小。我们会找到 s 的每个下位词的大小,然后将它们加到一起(我们也将加 1 表示同义词集本身)。下面的函数size1()做这项工作;注意函数体中包括size1()的递归调用:
>>> def size1(s):... return 1 + sum(size1(child) for child in s.hyponyms())
我们也可以设计一种这个问题的迭代解决方案处理层的层次结构。第一层是同义词集本身![[1]](/uploads/projects/1594/65862.jpg) ,然后是同义词集所有的下位词,之后是所有下位词的下位词。每次循环通过查找上一层的所有下位词计算下一层
,然后是同义词集所有的下位词,之后是所有下位词的下位词。每次循环通过查找上一层的所有下位词计算下一层![[3]](/uploads/projects/1594/65863.jpg) 。它也保存了到目前为止遇到的同义词集的总数
。它也保存了到目前为止遇到的同义词集的总数![[2]](/uploads/projects/1594/65864.jpg) 。
。
>>> def size2(s):... layer = [s] ![[1]](/projects/nlp-py-2e-zh/Images/ffa808c97c7034af1bc2806ed7224203.jpg)... total = 0... while layer:... total += len(layer) ![[2]](/projects/nlp-py-2e-zh/Images/aa68e0e8f4d58caa31e5542dabe4ddc2.jpg)... layer = [h for c in layer for h in c.hyponyms()] ![[3]](/projects/nlp-py-2e-zh/Images/496754d8cdb6262f8f72e1f066bab359.jpg)... return total
迭代解决方案不仅代码更长而且更难理解。它迫使我们程序式的思考问题,并跟踪layer和total随时间变化发生了什么。让我们满意的是两种解决方案均给出了相同的结果。我们将使用 import 语句的一个新的形式,允许我们缩写名称wordnet为wn:
>>> from nltk.corpus import wordnet as wn>>> dog = wn.synset('dog.n.01')>>> size1(dog)190>>> size2(dog)190
作为递归的最后一个例子,让我们用它来构建一个深嵌套的对象。一个字母查找树是一种可以用来索引词汇的数据结构,一次一个字母。(这个名字来自于单词 retrieval)。例如,如果trie包含一个字母的查找树,那么trie['c']是一个较小的查找树,包含所有以 c 开头的词。4.9演示了使用 Python 字典(3)构建查找树的递归过程。若要插入词 chien(dog 的法语),我们将 c 分类,递归的掺入 hien 到trie['c']子查找树中。递归继续直到词中没有剩余的字母,于是我们存储的了预期值(本例中是词 dog)。
def insert(trie, key, value):if key:first, rest = key[0], key[1:]if first not in trie:trie[first] = {}insert(trie[first], rest, value)else:trie['value'] = value
小心!
尽管递归编程结构简单,但它是有代价的。每次函数调用时,一些状态信息需要推入堆栈,这样一旦函数执行完成可以从离开的地方继续执行。出于这个原因,迭代的解决方案往往比递归解决方案的更高效。
权衡空间与时间
我们有时可以显著的加快程序的执行,通过建设一个辅助的数据结构,例如索引。4.10实现一个简单的电影评论语料库的全文检索系统。通过索引文档集合,它提供更快的查找。
def raw(file):contents = open(file).read()contents = re.sub(r'<.*?>', ' ', contents)contents = re.sub('\s+', ' ', contents)return contentsdef snippet(doc, term):text = ' '*30 + raw(doc) + ' '*30pos = text.index(term)return text[pos-30:pos+30]print("Building Index...")files = nltk.corpus.movie_reviews.abspaths()idx = nltk.Index((w, f) for f in files for w in raw(f).split())query = ''while query != "quit":query = input("query> ") # use raw_input() in Python 2if query in idx:for doc in idx[query]:print(snippet(doc, query))else:print("Not found")
一个更微妙的空间与时间折中的例子涉及使用整数标识符替换一个语料库的词符。我们为语料库创建一个词汇表,每个词都被存储一次的列表,然后转化这个列表以便我们能通过查找任意词来找到它的标识符。每个文档都进行预处理,使一个词列表变成一个整数列表。现在所有的语言模型都可以使用整数。见4.11中的内容,如何为一个已标注的语料库做这个的例子的列表。
def preprocess(tagged_corpus):words = set()tags = set()for sent in tagged_corpus:for word, tag in sent:words.add(word)tags.add(tag)wm = dict((w, i) for (i, w) in enumerate(words))tm = dict((t, i) for (i, t) in enumerate(tags))return [[(wm[w], tm[t]) for (w, t) in sent] for sent in tagged_corpus]
空间时间权衡的另一个例子是维护一个词汇表。如果你需要处理一段输入文本检查所有的词是否在现有的词汇表中,词汇表应存储为一个集合,而不是一个列表。集合中的元素会自动索引,所以测试一个大的集合的成员将远远快于测试相应的列表的成员。
我们可以使用timeit模块测试这种说法。Timer类有两个参数:一个是多次执行的语句,一个是只在开始执行一次的设置代码。我们将分别使用一个整数的列表和一个整数的集合模拟 10 万个项目的词汇表。测试语句将产生一个随机项,它有 50%的机会在词汇表中。
>>> from timeit import Timer>>> vocab_size = 100000>>> setup_list = "import random; vocab = range(%d)" % vocab_size ![[1]](/projects/nlp-py-2e-zh/Images/ffa808c97c7034af1bc2806ed7224203.jpg)>>> setup_set = "import random; vocab = set(range(%d))" % vocab_size ![[2]](/projects/nlp-py-2e-zh/Images/aa68e0e8f4d58caa31e5542dabe4ddc2.jpg)>>> statement = "random.randint(0, %d) in vocab" % (vocab_size * 2) ![[3]](/projects/nlp-py-2e-zh/Images/496754d8cdb6262f8f72e1f066bab359.jpg)>>> print(Timer(statement, setup_list).timeit(1000))2.78092288971>>> print(Timer(statement, setup_set).timeit(1000))0.0037260055542
执行 1000 次链表成员资格测试总共需要 2.8 秒,而在集合上的等效试验仅需 0.0037 秒,也就是说快了三个数量级!
动态规划
动态规划是一种自然语言处理中被广泛使用的算法设计的一般方法。“programming”一词的用法与你可能想到的感觉不同,是规划或调度的意思。动态规划用于解决包含多个重叠的子问题的问题。不是反复计算这些子问题,而是简单的将它们的计算结果存储在一个查找表中。在本节的余下部分,我们将介绍动态规划,在一个相当不同的背景下来句法分析。
Pingala 是大约生活在公元前 5 世纪的印度作家,作品有被称为 《Chandas Shastra》 的梵文韵律专著。Virahanka 大约在公元 6 世纪延续了这项工作,研究短音节和长音节组合产生一个长度为 n 的旋律的组合数。短音节,标记为 S,占一个长度单位,而长音节,标记为 L,占 2 个长度单位。例如,Pingala 发现,有 5 种方式构造一个长度为 4 的旋律:V<sub>4</sub> = {LL, SSL, SLS, LSS, SSSS}。请看,我们可以将 V<sub>4</sub>分成两个子集,以 L 开始的子集和以 S 开始的子集,如(1)所示。
V4 =LL, LSSi.e. L prefixed to each item of V2 = {L, SS}SSL, SLS, SSSSi.e. S prefixed to each item of V3 = {SL, LS, SSS}
有了这个观察结果,我们可以写一个小的递归函数称为virahanka1()来计算这些旋律,如4.12所示。请注意,要计算 V<sub>4</sub>,我们先要计算 V<sub>3</sub>和 V<sub>2</sub>。但要计算 V<sub>3</sub>,我们先要计算 V<sub>2</sub>和 V<sub>1</sub>。在(2)中描述了这种调用结构。
from numpy import arangefrom matplotlib import pyplotcolors = 'rgbcmyk' # red, green, blue, cyan, magenta, yellow, blackdef bar_chart(categories, words, counts):"Plot a bar chart showing counts for each word by category"ind = arange(len(words))width = 1 / (len(categories) + 1)bar_groups = []for c in range(len(categories)):bars = pyplot.bar(ind+c*width, counts[categories[c]], width,color=colors[c % len(colors)])bar_groups.append(bars)pyplot.xticks(ind+width, words)pyplot.legend([b[0] for b in bar_groups], categories, loc='upper left')pyplot.ylabel('Frequency')pyplot.title('Frequency of Six Modal Verbs by Genre')pyplot.show()
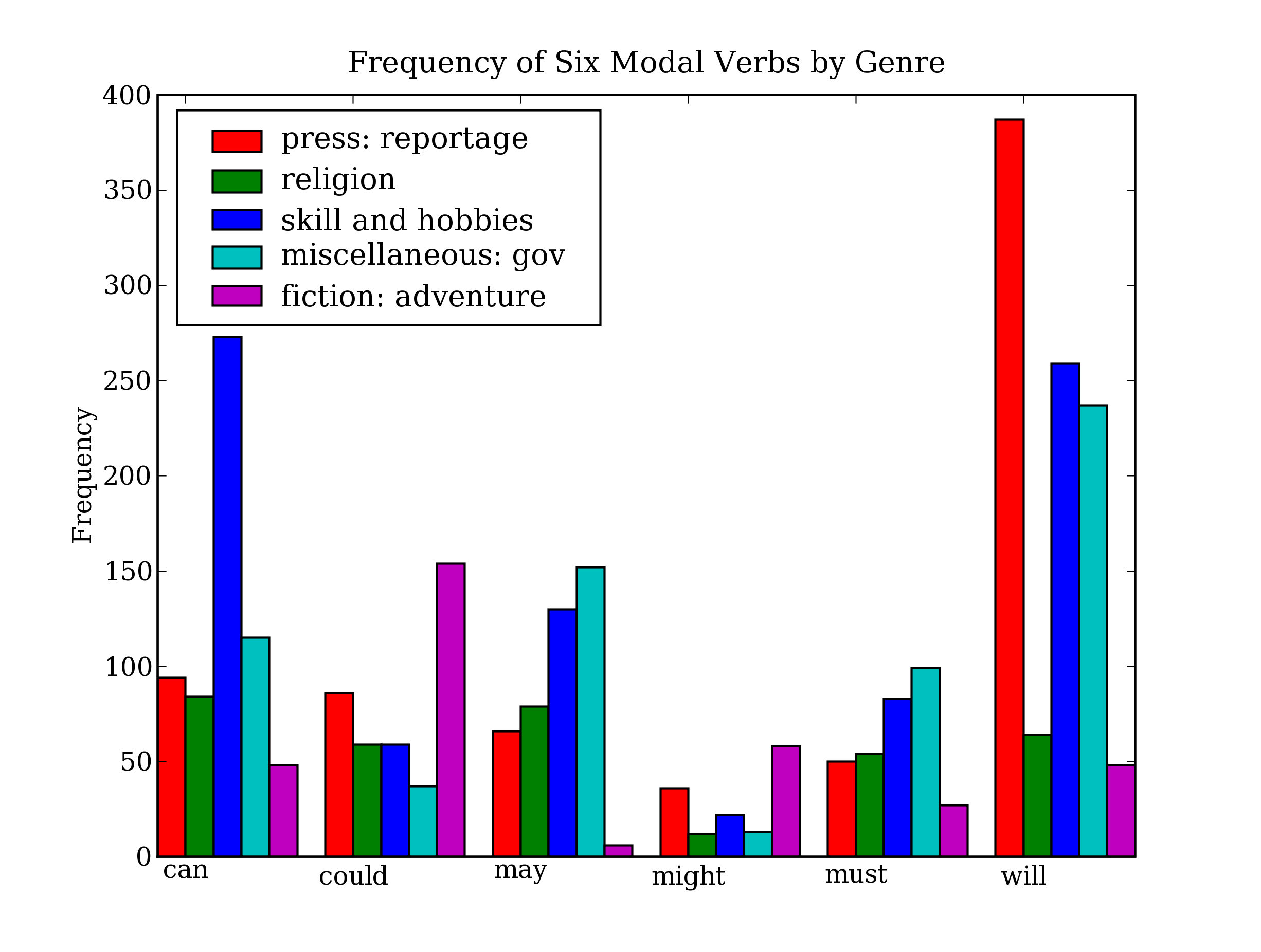
图 4.14:条形图显示布朗语料库中不同部分的情态动词频率:这个可视化图形由4.13中的程序产生。
从该柱状图可以立即看出 may 和 must 有几乎相同的相对频率。could 和 might 也一样。
也可以动态的产生这些数据的可视化图形。例如,一个使用表单输入的网页可以允许访问者指定搜索参数,提交表单,看到一个动态生成的可视化图形。要做到这一点,我们必须为matplotlib指定Agg后台,它是一个产生栅格(像素)图像的库。下一步,我们像以前一样使用相同的 Matplotlib 方法,但不是用pyplot.show()显示结果在图形终端,而是使用pyplot.savefig()把它保存到一个文件。我们指定文件名,然后输出一些 HTML 标记指示网页浏览器来加载该文件。
>>> from matplotlib import use, pyplot>>> use('Agg') ![[1]](/projects/nlp-py-2e-zh/Images/ffa808c97c7034af1bc2806ed7224203.jpg)>>> pyplot.savefig('modals.png') ![[2]](/projects/nlp-py-2e-zh/Images/aa68e0e8f4d58caa31e5542dabe4ddc2.jpg)>>> print('Content-Type: text/html')>>> print()>>> print('<html><body>')>>> print('<img src="modals.png"/>')>>> print('</body></html>')
NetworkX
NetworkX 包定义和操作被称为图的由节点和边组成的结构。它可以从https://networkx.lanl.gov/得到。NetworkX 可以和 Matplotlib 结合使用可视化如 WordNet 的网络结构(语义网络,我们在5介绍过)。4.15中的程序初始化一个空的图,然后遍历 WordNet 上位词层次为图添加边。请注意,遍历是递归的,使用在4.7讨论的编程技术。结果显示在4.16。
import networkx as nximport matplotlibfrom nltk.corpus import wordnet as wndef traverse(graph, start, node):graph.depth[node.name] = node.shortest_path_distance(start)for child in node.hyponyms():graph.add_edge(node.name, child.name) ![[1]](/projects/nlp-py-2e-zh/Images/ffa808c97c7034af1bc2806ed7224203.jpg)traverse(graph, start, child) ![[2]](/projects/nlp-py-2e-zh/Images/aa68e0e8f4d58caa31e5542dabe4ddc2.jpg)def hyponym_graph(start):G = nx.Graph() ![[3]](/projects/nlp-py-2e-zh/Images/496754d8cdb6262f8f72e1f066bab359.jpg)G.depth = {}traverse(G, start, start)return Gdef graph_draw(graph):nx.draw_graphviz(graph,node_size = [16 * graph.degree(n) for n in graph],node_color = [graph.depth[n] for n in graph],with_labels = False)matplotlib.pyplot.show()
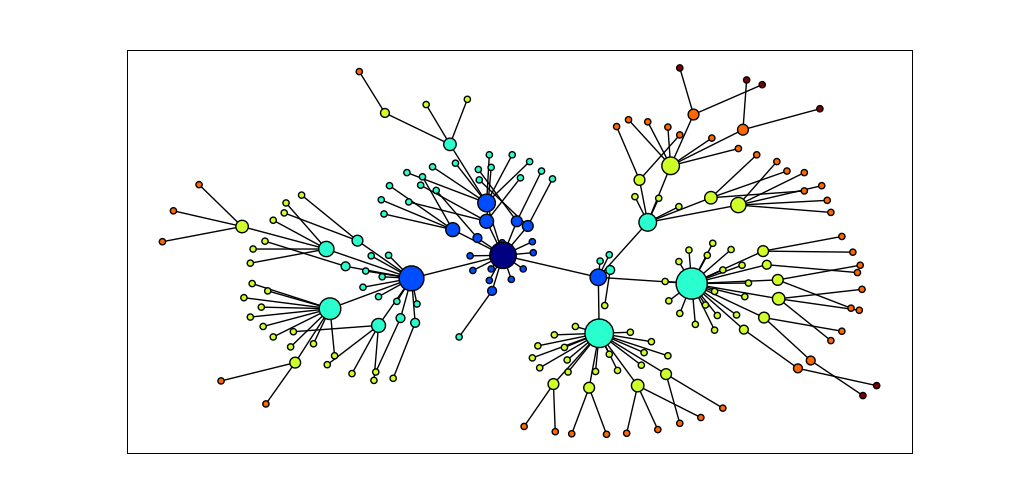
图 4.16:使用 NetworkX 和 Matplotlib 可视化数据:WordNet 的上位词层次的部分显示,开始于dog.n.01(中间最黑的节点);节点的大小对应节点的孩子的数目,颜色对应节点到dog.n.01的距离;此可视化图形由4.15中的程序产生。
csv
语言分析工作往往涉及数据统计表,包括有关词项的信息、试验研究的参与者名单或从语料库提取的语言特征。这里有一个 CSV 格式的简单的词典片段:
sleep, sli:p, v.i, a condition of body and mind …walk, wo:k, v.intr, progress by lifting and setting down each foot …wake, weik, intrans, cease to sleep
我们可以使用 Python 的 CSV 库读写这种格式存储的文件。例如,我们可以打开一个叫做lexicon.csv的 CSV 文件,并遍历它的行:
>>> import csv>>> input_file = open("lexicon.csv", "rb") ![[1]](/projects/nlp-py-2e-zh/Images/ffa808c97c7034af1bc2806ed7224203.jpg)>>> for row in csv.reader(input_file): ![[2]](/projects/nlp-py-2e-zh/Images/aa68e0e8f4d58caa31e5542dabe4ddc2.jpg)... print(row)['sleep', 'sli:p', 'v.i', 'a condition of body and mind ...']['walk', 'wo:k', 'v.intr', 'progress by lifting and setting down each foot ...']['wake', 'weik', 'intrans', 'cease to sleep']
每一行是一个字符串列表。如果字段包含有数值数据,它们将作为字符串出现,所以都必须使用int()或float()转换。
NumPy
NumPy 包对 Python 中的数值处理提供了大量的支持。NumPy 有一个多维数组对象,它可以很容易初始化和访问:
>>> from numpy import array>>> cube = array([ [[0,0,0], [1,1,1], [2,2,2]],... [[3,3,3], [4,4,4], [5,5,5]],... [[6,6,6], [7,7,7], [8,8,8]] ])>>> cube[1,1,1]4>>> cube[2].transpose()array([[6, 7, 8],[6, 7, 8],[6, 7, 8]])>>> cube[2,1:]array([[7, 7, 7],[8, 8, 8]])
NumPy 包括线性代数函数。在这里我们进行矩阵的奇异值分解,潜在语义分析中使用的操作,它能帮助识别一个文档集合中的隐含概念。
>>> from numpy import linalg>>> a=array([[4,0], [3,-5]])>>> u,s,vt = linalg.svd(a)>>> uarray([[-0.4472136 , -0.89442719],[-0.89442719, 0.4472136 ]])>>> sarray([ 6.32455532, 3.16227766])>>> vtarray([[-0.70710678, 0.70710678],[-0.70710678, -0.70710678]])
NLTK 中的聚类包nltk.cluster中广泛使用 NumPy 数组,支持包括 k-means 聚类、高斯 EM 聚类、组平均凝聚聚类以及聚类分析图。有关详细信息,请输入help(nltk.cluster)。
其他 Python 库
还有许多其他的 Python 库,你可以使用http://pypi.python.org/处的 Python 包索引找到它们。许多库提供了外部软件接口,例如关系数据库(如mysql-python)和大数据集合(如PyLucene)。许多其他库能访问各种文件格式,如 PDF、MSWord 和 XML(pypdf, pywin32, xml.etree)、RSS 源(如feedparser)以及电子邮箱(如imaplib, email)。
