 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签学习优化奖励
在强化学习中,智能体在环境(environment)中观察(observation)并且做出决策(action),随后它会得到奖励(reward)。它的目标是去学习如何行动能最大化期望奖励。如果你不在意去拟人化的话,你可以认为正奖励是愉快,负奖励是痛苦(这样的话奖励一词就有点误导了)。简单来说,智能体在环境中行动,并且在实验和错误中去学习最大化它的愉快,最小化它的痛苦。
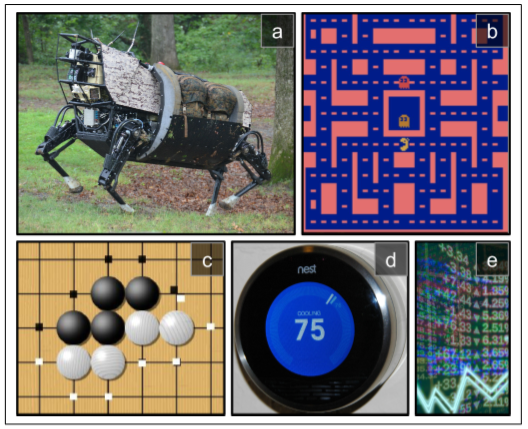
这是一个相当广泛的设置,可以适用于各种各样的任务。以下是几个例子(详见图 16-1):
- 智能体可以是控制一个机械狗的程序。在此例中,环境就是真实的世界,智能体通过许多的传感器例如摄像机或者传感器来观察,它可以通过给电机发送信号来行动。它可以被编程设置为如果到达了目的地就得到正奖励,如果浪费时间,或者走错方向,或摔倒了就得到负奖励。
- 智能体可以是控制 MS.Pac-Man 的程序。在此例中,环境是 Atari 游戏的仿真,行为是 9 个操纵杆位(上下左右中间等等),观察是屏幕,回报就是游戏点数。
- 相似地,智能体也可以是棋盘游戏的程序例如:围棋。
- 智能体也可以不用去控制一个实体(或虚拟的)去移动。例如它可以是一个智能程序,当它调整到目标温度以节能时会得到正奖励,当人们需要自己去调节温度时它会得到负奖励,所以智能体必须学会预见人们的需要。
- 智能体也可以去观测股票市场价格以实时决定买卖。奖励的依据显然为挣钱或者赔钱。
其实没有正奖励也是可以的,例如智能体在迷宫内移动,它每分每秒都得到一个负奖励,所以它要尽可能快的找到出口!还有很多适合强化学习的领域,例如自动驾驶汽车,在网页上放广告,或者控制一个图像分类系统让它明白它应该关注于什么。
