 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签学习曲线
如果你使用一个高阶的多项式回归,你可能发现它的拟合程度要比普通的线性回归要好的多。例如,图 4-14 使用一个 300 阶的多项式模型去拟合之前的数据集,并同简单线性回归、2 阶的多项式回归进行比较。注意 300 阶的多项式模型如何摆动以尽可能接近训练实例。
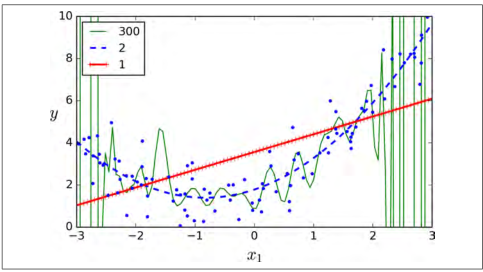
图 4-14:高阶多项式回归
当然,这种高阶多项式回归模型在这个训练集上严重过拟合了,线性模型则欠拟合。在这个训练集上,二次模型有着较好的泛化能力。那是因为在生成数据时使用了二次模型,但是一般我们不知道这个数据生成函数是什么,那我们该如何决定我们模型的复杂度呢?你如何告诉我你的模型是过拟合还是欠拟合?
在第二章,你可以使用交叉验证来估计一个模型的泛化能力。如果一个模型在训练集上表现良好,通过交叉验证指标却得出其泛化能力很差,那么你的模型就是过拟合了。如果在这两方面都表现不好,那么它就是欠拟合了。这种方法可以告诉我们,你的模型是太复杂还是太简单了。
另一种方法是观察学习曲线:画出模型在训练集上的表现,同时画出以训练集规模为自变量的训练集函数。为了得到图像,需要在训练集的不同规模子集上进行多次训练。下面的代码定义了一个函数,用来画出给定训练集后的模型学习曲线:
from sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import train_test_splitdef plot_learning_curves(model, X, y):X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)train_errors, val_errors = [], []for m in range(1, len(X_train)):model.fit(X_train[:m], y_train[:m])y_train_predict = model.predict(X_train[:m])y_val_predict = model.predict(X_val)train_errors.append(mean_squared_error(y_train_predict, y_train[:m]))val_errors.append(mean_squared_error(y_val_predict, y_val))plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
我们一起看一下简单线性回归模型的学习曲线(图 4-15):
lin_reg = LinearRegression()plot_learning_curves(lin_reg, X, y)
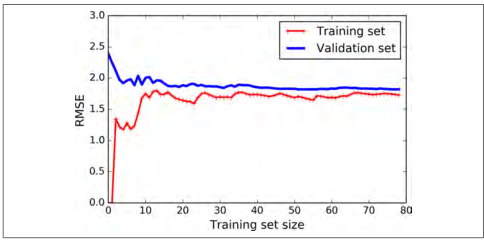
图 4-15:学习曲线
这幅图值得我们深究。首先,我们观察训练集的表现:当训练集只有一两个样本的时候,模型能够非常好的拟合它们,这也是为什么曲线是从零开始的原因。但是当加入了一些新的样本的时候,训练集上的拟合程度变得难以接受,出现这种情况有两个原因,一是因为数据中含有噪声,另一个是数据根本不是线性的。因此随着数据规模的增大,误差也会一直增大,直到达到高原地带并趋于稳定,在之后,继续加入新的样本,模型的平均误差不会变得更好或者更差。我们继续来看模型在验证集上的表现,当以非常少的样本去训练时,模型不能恰当的泛化,也就是为什么验证误差一开始是非常大的。当训练样本变多的到时候,模型学习的东西变多,验证误差开始缓慢的下降。但是一条直线不可能很好的拟合这些数据,因此最后误差会到达在一个高原地带并趋于稳定,最后和训练集的曲线非常接近。
上面的曲线表现了一个典型的欠拟合模型,两条曲线都到达高原地带并趋于稳定,并且最后两条曲线非常接近,同时误差值非常大。
提示
如果你的模型在训练集上是欠拟合的,添加更多的样本是没用的。你需要使用一个更复杂的模型或者找到更好的特征。
现在让我们看一个在相同数据上10阶多项式模型拟合的学习曲线(图 4-16):
from sklearn.pipeline import Pipelinepolynomial_regression = Pipeline((("poly_features", PolynomialFeatures(degree=10, include_bias=False)),("sgd_reg", LinearRegression()),))plot_learning_curves(polynomial_regression, X, y)
这幅图像和之前的有一点点像,但是其有两个非常重要的不同点:
- 在训练集上,误差要比线性回归模型低的多。
- 图中的两条曲线之间有间隔,这意味模型在训练集上的表现要比验证集上好的多,这也是模型过拟合的显著特点。当然,如果你使用了更大的训练数据,这两条曲线最后会非常的接近。
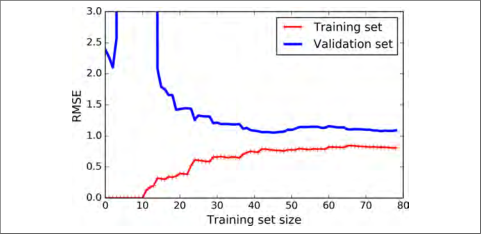
图4-16:多项式模型的学习曲线
提示
改善模型过拟合的一种方法是提供更多的训练数据,直到训练误差和验证误差相等。
偏差和方差的权衡
在统计和机器学习领域有个重要的理论:一个模型的泛化误差由三个不同误差的和决定:
- 偏差:泛化误差的这部分误差是由于错误的假设决定的。例如实际是一个二次模型,你却假设了一个线性模型。一个高偏差的模型最容易出现欠拟合。
- 方差:这部分误差是由于模型对训练数据的微小变化较为敏感,一个多自由度的模型更容易有高的方差(例如一个高阶多项式模型),因此会导致模型过拟合。
- 不可约误差:这部分误差是由于数据本身的噪声决定的。降低这部分误差的唯一方法就是进行数据清洗(例如:修复数据源,修复坏的传感器,识别和剔除异常值)。
