 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签批量标准化
尽管使用 He初始化和 ELU(或任何 ReLU 变体)可以显著减少训练开始阶段的梯度消失/爆炸问题,但不保证在训练期间问题不会回来。
在 2015 年的一篇论文中,Sergey Ioffe 和 Christian Szegedy 提出了一种称为批量标准化(Batch Normalization,BN)的技术来解决梯度消失/爆炸问题,每层输入的分布在训练期间改变的问题,更普遍的问题是当前一层的参数改变,每层输入的分布会在训练过程中发生变化(他们称之为内部协变量偏移问题)。
该技术包括在每层的激活函数之前在模型中添加操作,简单地对输入进行zero-centering和规范化,然后每层使用两个新参数(一个用于尺度变换,另一个用于偏移)对结果进行尺度变换和偏移。 换句话说,这个操作可以让模型学习到每层输入值的最佳尺度,均值。为了对输入进行归零和归一化,算法需要估计输入的均值和标准差。 它通过评估当前小批量输入的均值和标准差(因此命名为“批量标准化”)来实现。 整个操作在方程 11-3 中。

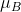 是整个小批量B的经验均值
是整个小批量B的经验均值
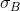 是经验性的标准差,也是来评估整个小批量的。
是经验性的标准差,也是来评估整个小批量的。
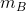 是小批量中的实例数量。
是小批量中的实例数量。
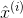 是以为零中心和标准化的输入。
是以为零中心和标准化的输入。
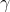 是层的缩放参数。
是层的缩放参数。
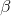 是层的移动参数(偏移量)
是层的移动参数(偏移量)
 是一个很小的数字,以避免被零除(通常为
是一个很小的数字,以避免被零除(通常为10 ^ -3)。 这被称为平滑项(拉布拉斯平滑,Laplace Smoothing)。
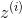 是BN操作的输出:它是输入的缩放和移位版本。
是BN操作的输出:它是输入的缩放和移位版本。
在测试时,没有小批量计算经验均值和标准差,所以您只需使用整个训练集的均值和标准差。 这些通常在训练期间使用移动平均值进行有效计算。 因此,总的来说,每个批次标准化的层次都学习了四个参数:γ(标度),β(偏移),μ(平均值)和σ(标准差)。
作者证明,这项技术大大改善了他们试验的所有深度神经网络。梯度消失问题大大减少了,他们可以使用饱和激活函数,如 tanh 甚至 sigmoid 激活函数。网络对权重初始化也不那么敏感。他们能够使用更大的学习率,显著加快了学习过程。具体地,他们指出,“应用于最先进的图像分类模型,批标准化用少了 14 倍的训练步骤实现了相同的精度,以显著的优势击败了原始模型。[…] 使用批量标准化的网络集合,我们改进了 ImageNet 分类上的最佳公布结果:达到4.9% 的前5个验证错误(和 4.8% 的测试错误),超出了人类评估者的准确性。批量标准化也像一个正则化项一样,减少了对其他正则化技术的需求(如本章稍后描述的 dropout).
然而,批量标准化的确会增加模型的复杂性(尽管它不需要对输入数据进行标准化,因为第一个隐藏层会照顾到这一点,只要它是批量标准化的)。 此外,还存在运行时间的损失:由于每层所需的额外计算,神经网络的预测速度较慢。 所以,如果你需要预测闪电般快速,你可能想要检查普通ELU + He初始化执行之前如何执行批量标准化。
您可能会发现,训练起初相当缓慢,而渐变下降正在寻找每层的最佳尺度和偏移量,但一旦找到合理的好值,它就会加速。
使用 TensorFlow 实现批量标准化
TensorFlow 提供了一个batch_normalization()函数,它简单地对输入进行居中和标准化,但是您必须自己计算平均值和标准差(基于训练期间的小批量数据或测试过程中的完整数据集) 作为这个函数的参数,并且还必须处理缩放和偏移量参数的创建(并将它们传递给此函数)。 这是可行的,但不是最方便的方法。 相反,你应该使用batch_norm()函数,它为你处理所有这些。 您可以直接调用它,或者告诉fully_connected()函数使用它,如下面的代码所示:
注意:本书使用tensorflow.contrib.layers.batch_norm()而不是tf.layers.batch_normalization()(本章写作时不存在)。 现在最好使用tf.layers.batch_normalization(),因为contrib模块中的任何内容都可能会改变或被删除,恕不另行通知。 我们现在不使用batch_norm()函数作为fully_connected()函数的正则化参数,而是使用batch_normalization(),并明确地创建一个不同的层。 参数有些不同,特别是:
decay更名为momentumis_training被重命名为trainingupdates_collections被删除:批量标准化所需的更新操作被添加到UPDATE_OPS集合中,并且您需要在训练期间明确地运行这些操作(请参阅下面的执行阶段)- 我们不需要指定
scale = True,因为这是默认值。
还要注意,为了在每个隐藏层激活函数之前运行批量标准化,我们手动应用 RELU 激活函数,在批量规范层之后。注意:由于tf.layers.dense()函数与本书中使用的tf.contrib.layers.arg_scope()不兼容,我们现在使用 python 的functools.partial()函数。 它可以很容易地创建一个my_dense_layer()函数,只需调用tf.layers.dense(),并自动设置所需的参数(除非在调用my_dense_layer()时覆盖它们)。 如您所见,代码保持非常相似。
import tensorflow as tfn_inputs = 28 * 28n_hidden1 = 300n_hidden2 = 100n_outputs = 10X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")training = tf.placeholder_with_default(False, shape=(), name='training')hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")bn1 = tf.layers.batch_normalization(hidden1, training=training, momentum=0.9)bn1_act = tf.nn.elu(bn1)hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")bn2 = tf.layers.batch_normalization(hidden2, training=training, momentum=0.9)bn2_act = tf.nn.elu(bn2)logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")logits = tf.layers.batch_normalization(logits_before_bn, training=training,momentum=0.9)
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")training = tf.placeholder_with_default(False, shape=(), name='training')
为了避免一遍又一遍重复相同的参数,我们可以使用 Python 的partial()函数:
from functools import partialmy_batch_norm_layer = partial(tf.layers.batch_normalization,training=training, momentum=0.9)hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")bn1 = my_batch_norm_layer(hidden1)bn1_act = tf.nn.elu(bn1)hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")bn2 = my_batch_norm_layer(hidden2)bn2_act = tf.nn.elu(bn2)logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")logits = my_batch_norm_layer(logits_before_bn)
完整代码
from functools import partialfrom tensorflow.examples.tutorials.mnist import input_dataimport tensorflow as tfif __name__ == '__main__':n_inputs = 28 * 28n_hidden1 = 300n_hidden2 = 100n_outputs = 10mnist = input_data.read_data_sets("/tmp/data/")batch_norm_momentum = 0.9learning_rate = 0.01X = tf.placeholder(tf.float32, shape=(None, n_inputs), name = 'X')y = tf.placeholder(tf.int64, shape=None, name = 'y')training = tf.placeholder_with_default(False, shape=(), name = 'training')# 给Batch norm加一个placeholderwith tf.name_scope("dnn"):he_init = tf.contrib.layers.variance_scaling_initializer()# 对权重的初始化my_batch_norm_layer = partial(tf.layers.batch_normalization,training = training,momentum = batch_norm_momentum)my_dense_layer = partial(tf.layers.dense,kernel_initializer = he_init)hidden1 = my_dense_layer(X ,n_hidden1 ,name = 'hidden1')bn1 = tf.nn.elu(my_batch_norm_layer(hidden1))hidden2 = my_dense_layer(bn1, n_hidden2, name = 'hidden2')bn2 = tf.nn.elu(my_batch_norm_layer(hidden2))logists_before_bn = my_dense_layer(bn2, n_outputs, name = 'outputs')logists = my_batch_norm_layer(logists_before_bn)with tf.name_scope('loss'):xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits= logists)loss = tf.reduce_mean(xentropy, name = 'loss')with tf.name_scope('train'):optimizer = tf.train.GradientDescentOptimizer(learning_rate)training_op = optimizer.minimize(loss)with tf.name_scope("eval"):correct = tf.nn.in_top_k(logists, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))init = tf.global_variables_initializer()saver = tf.train.Saver()n_epoches = 20batch_size = 200# 注意:由于我们使用的是 tf.layers.batch_normalization() 而不是 tf.contrib.layers.batch_norm()(如本书所述),# 所以我们需要明确运行批量规范化所需的额外更新操作(sess.run([ training_op,extra_update_ops], ...)。extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)with tf.Session() as sess:init.run()for epoch in range(n_epoches):for iteraton in range(mnist.train.num_examples//batch_size):X_batch, y_batch = mnist.train.next_batch(batch_size)sess.run([training_op,extra_update_ops],feed_dict={training:True, X:X_batch, y:y_batch})accuracy_val = accuracy.eval(feed_dict= {X:mnist.test.images,y:mnist.test.labels})print(epoch, 'Test accuracy:', accuracy_val)
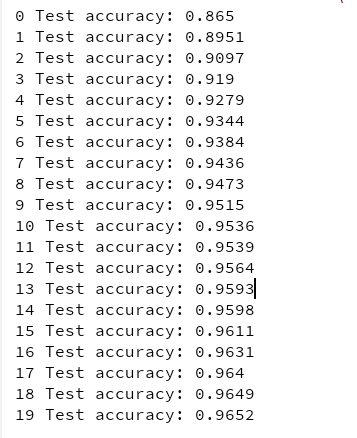
什么!? 这对 MNIST 来说不是一个很好的准确性。 当然,如果你训练的时间越长,准确性就越好,但是由于这样一个浅的网络,批量范数和 ELU 不太可能产生非常积极的影响:它们大部分都是为了更深的网络而发光。请注意,您还可以训练操作取决于更新操作:
with tf.name_scope("train"):optimizer = tf.train.GradientDescentOptimizer(learning_rate)extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)with tf.control_dependencies(extra_update_ops):training_op = optimizer.minimize(loss)
这样,你只需要在训练过程中评估training_op,TensorFlow也会自动运行更新操作:
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
