 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签基于实例 vs 基于模型学习
另一种分类机器学习的方法是判断它们是如何进行归纳推广的。大多机器学习任务是关于预测的。这意味着给定一定数量的训练样本,系统需要能推广到之前没见到过的样本。对训练数据集有很好的性能还不够,真正的目标是对新实例预测的性能。
有两种主要的归纳方法:基于实例学习和基于模型学习。
基于实例学习
也许最简单的学习形式就是用记忆学习。如果用这种方法做一个垃圾邮件检测器,只需标记所有和用户标记的垃圾邮件相同的邮件 —— 这个方法不差,但肯定不是最好的。
不仅能标记和已知的垃圾邮件相同的邮件,你的垃圾邮件过滤器也要能标记类似垃圾邮件的邮件。这就需要测量两封邮件的相似性。一个(简单的)相似度测量方法是统计两封邮件包含的相同单词的数量。如果一封邮件含有许多垃圾邮件中的词,就会被标记为垃圾邮件。
这被称作基于实例学习:系统先用记忆学习案例,然后使用相似度测量推广到新的例子(图 1-15)。
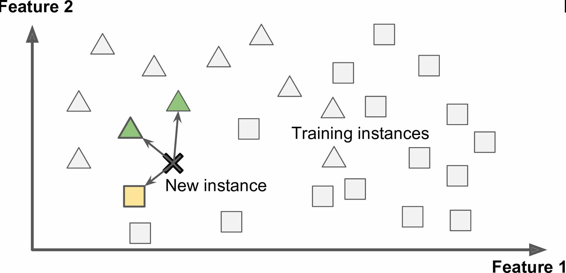
图 1-15 基于实例学习
基于模型学习
另一种从样本集进行归纳的方法是建立这些样本的模型,然后使用这个模型进行预测。这称作基于模型学习(图 1-16)。
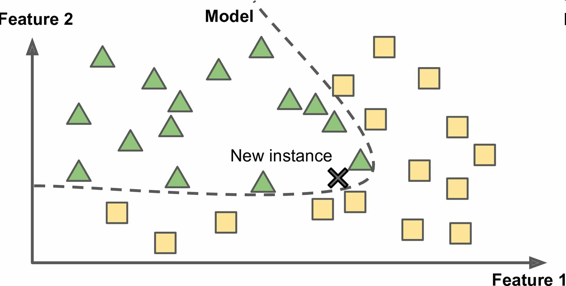
图 1-16 基于模型学习
例如,你想知道钱是否能让人快乐,你从 OECD 网站下载了 Better Life Index 指数数据,还从 IMF 下载了人均 GDP 数据。表 1-1 展示了摘要。
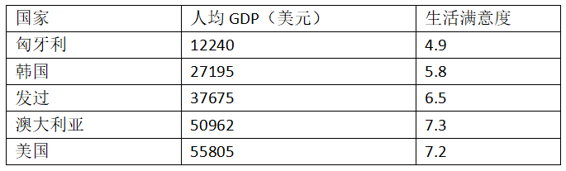
表 1-1 钱会使人幸福吗?
用一些国家的数据画图(图 1-17)。
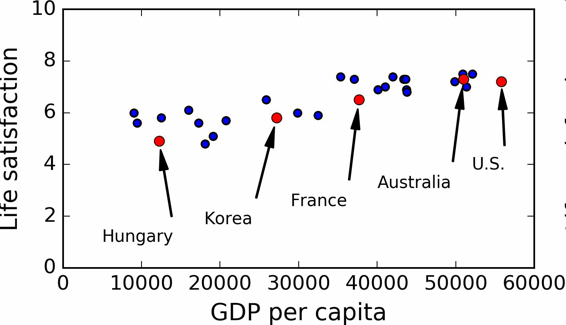
图 1-17 你看到趋势了吗?
确实能看到趋势!尽管数据有噪声(即,部分随机),看起来生活满意度是随着人均 GDP 的增长线性提高的。所以,你决定生活满意度建模为人均 GDP 的线性函数。这一步称作模型选择:你选一个生活满意度的线性模型,只有一个属性,人均 GDP(公式 1-1)。
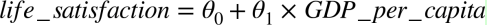
公式 1-1 一个简单的线性模型
这个模型有两个参数θ0和θ1。通过调整这两个参数,你可以使你的模型表示任何线性函数,见图 1-18。
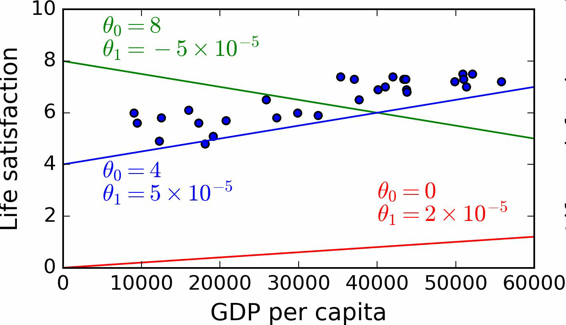
图 1-18 几个可能的线性模型
在使用模型之前,你需要确定θ0和θ1。如何能知道哪个值可以使模型的性能最佳呢?要回答这个问题,你需要指定性能的量度。你可以定义一个实用函数(或拟合函数)用来测量模型是否够好,或者你可以定义一个代价函数来测量模型有多差。对于线性回归问题,人们一般是用代价函数测量线性模型的预测值和训练样本的距离差,目标是使距离差最小。
接下来就是线性回归算法,你用训练样本训练算法,算法找到使线性模型最拟合数据的参数。这称作模型训练。在我们的例子中,算法得到的参数值是θ0=4.85和θ1=4.91×10–5。
现在模型已经最紧密地拟合到训练数据了,见图 1-19。
图 1-19 最佳拟合训练数据的线性模型
最后,可以准备运行模型进行预测了。例如,假如你想知道塞浦路斯人有多幸福,但 OECD 没有它的数据。幸运的是,你可以用模型进行预测:查询塞浦路斯的人均 GDP,为 22587 美元,然后应用模型得到生活满意度,后者的值在4.85 + 22,587 × 4.91 × 10-5 = 5.96左右。
为了激起你的兴趣,案例 1-1 展示了加载数据、准备、创建散点图的 Python 代码,然后训练线性模型并进行预测。
案例 1-1,使用 Scikit-Learn 训练并运行线性模型。
import matplotlibimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport sklearn# 加载数据oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',encoding='latin1', na_values="n/a")# 准备数据country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)X = np.c_[country_stats["GDP per capita"]]y = np.c_[country_stats["Life satisfaction"]]# 可视化数据country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')plt.show()# 选择线性模型lin_reg_model = sklearn.linear_model.LinearRegression()# 训练模型lin_reg_model.fit(X, y)# 对塞浦路斯进行预测X_new = [[22587]] # 塞浦路斯的人均GDPprint(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]
注解:如果你之前接触过基于实例学习算法,你会发现斯洛文尼亚的人均 GDP(20732 美元)和塞浦路斯差距很小,OECD 数据上斯洛文尼亚的生活满意度是 5.7,就可以预测塞浦路斯的生活满意度也是 5.7。如果放大一下范围,看一下接下来两个临近的国家,你会发现葡萄牙和西班牙的生活满意度分别是 5.1 和 6.5。对这三个值进行平均得到 5.77,就和基于模型的预测值很接近。这个简单的算法叫做k近邻回归(这个例子中,
k=3)。在前面的代码中替换线性回归模型为 K 近邻模型,只需更换下面一行:
clf = sklearn.linear_model.LinearRegression()为:
clf = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
如果一切顺利,你的模型就可以作出好的预测。如果不能,你可能需要使用更多的属性(就业率、健康、空气污染等等),获取更多更好的训练数据,或选择一个更好的模型(比如,多项式回归模型)。
总结一下:
- 研究数据
- 选择模型
- 用训练数据进行训练(即,学习算法搜寻模型参数值,使代价函数最小)
- 最后,使用模型对新案例进行预测(这称作推断),但愿这个模型推广效果不差
这就是一个典型的机器学习项目。在第 2 章中,你会第一手地接触一个完整的项目。
我们已经学习了许多关于基础的内容:你现在知道了机器学习是关于什么的,为什么它这么有用,最常见的机器学习的分类,典型的项目工作流程。现在,让我们看一看学习中会发生什么错误,导致不能做出准确的预测。
