我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签模块性
假设您要创建一个图,它的作用是将两个整流线性单元(ReLU)的输出值相加。 ReLU 计算一个输入值的对应线性函数输出值,如果为正,则输出该结值,否则为 0,如等式 9-1 所示。

下面的代码做这个工作,但是它是相当重复的:
n_features = 3X = tf.placeholder(tf.float32, shape=(None, n_features), name="X")w1 = tf.Variable(tf.random_normal((n_features, 1)), name="weights1")w2 = tf.Variable(tf.random_normal((n_features, 1)), name="weights2")b1 = tf.Variable(0.0, name="bias1")b2 = tf.Variable(0.0, name="bias2")z1 = tf.add(tf.matmul(X, w1), b1, name="z1")z2 = tf.add(tf.matmul(X, w2), b2, name="z2")relu1 = tf.maximum(z1, 0., name="relu1")relu2 = tf.maximum(z1, 0., name="relu2")output = tf.add(relu1, relu2, name="output")
这样的重复代码很难维护,容易出错(实际上,这个代码包含了一个剪贴错误,你发现了吗?) 如果你想添加更多的 ReLU,会变得更糟。 幸运的是,TensorFlow 可以让您保持 DRY(不要重复自己):只需创建一个功能来构建 ReLU。 以下代码创建五个 ReLU 并输出其总和(注意,add_n()创建一个计算张量列表之和的操作):
def relu(X):w_shape = (int(X.get_shape()[1]), 1)w = tf.Variable(tf.random_normal(w_shape), name="weights")b = tf.Variable(0.0, name="bias")z = tf.add(tf.matmul(X, w), b, name="z")return tf.maximum(z, 0., name="relu")n_features = 3X = tf.placeholder(tf.float32, shape=(None, n_features), name="X")relus = [relu(X) for i in range(5)]output = tf.add_n(relus, name="output")
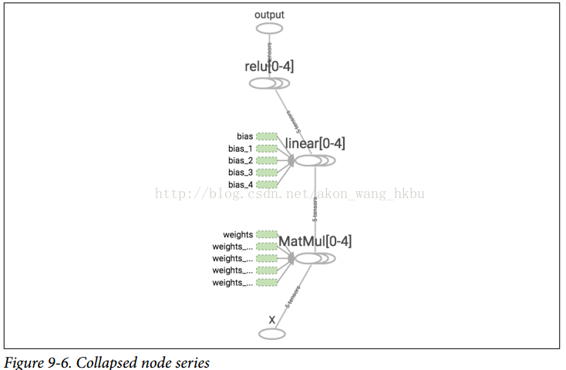
请注意,创建节点时,TensorFlow 将检查其名称是否已存在,如果它已经存在,则会附加一个下划线,后跟一个索引,以使该名称是唯一的。 因此,第一个 ReLU 包含名为weights,bias,z和relu的节点(加上其他默认名称的更多节点,如MatMul); 第二个 ReLU 包含名为weights_1,bias_1等节点的节点; 第三个 ReLU 包含名为 weights_2,bias_2的节点,依此类推。 TensorBoard 识别这样的系列并将它们折叠在一起以减少混乱(如图 9-6 所示)
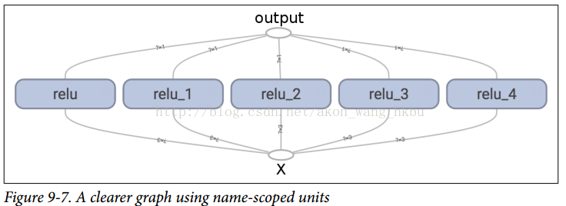
使用名称作用域,您可以使图形更清晰。 简单地将relu()函数的所有内容移动到名称作用域内。 图 9-7 显示了结果图。 请注意,TensorFlow 还通过附加_1,_2等来提供名称作用域的唯一名称。
def relu(X):with tf.name_scope("relu"):w_shape = (int(X.get_shape()[1]), 1) # not shown in the bookw = tf.Variable(tf.random_normal(w_shape), name="weights") # not shownb = tf.Variable(0.0, name="bias") # not shownz = tf.add(tf.matmul(X, w), b, name="z") # not shownreturn tf.maximum(z, 0., name="max") # not shown