 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签时间上的静态展开
static_rnn()函数通过链接单元来创建一个展开的 RNN 网络。 下面的代码创建了与上一个完全相同的模型:
X0 = tf.placeholder(tf.float32, [None, n_inputs])X1 = tf.placeholder(tf.float32, [None, n_inputs])basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, [X0, X1], dtype=tf.float32)Y0, Y1 = output_seqs
首先,我们像以前一样创建输入占位符。 然后,我们创建一个BasicRNNCell,你可以将其视为一个工厂,创建单元的副本以构建展开的 RNN(每个时间步一个)。 然后我们调用static_rnn(),向它提供单元工厂和输入张量,并告诉它输入的数据类型(用来创建初始状态矩阵,默认情况下是全零)。 static_rnn()函数为每个输入调用单元工厂的__call __()函数,创建单元的两个副本(每个单元包含 5 个循环神经元的循环层),并具有共享的权重和偏置项,像前面一样。static_rnn()函数返回两个对象。 第一个是包含每个时间步的输出张量的 Python 列表。 第二个是包含网络最终状态的张量。 当你使用基本的单元时,最后的状态就等于最后的输出。
如果有 50 个时间步长,则不得不定义 50 个输入占位符和 50 个输出张量。而且,在执行时,你将不得不为 50 个占位符中的每个占位符输入数据并且还要操纵 50 个输出。我们来简化一下。下面的代码再次构建相同的 RNN,但是这次它需要一个形状为[None,n_steps,n_inputs]的单个输入占位符,其中第一个维度是最小批量大小。然后提取每个时间步的输入序列列表。 X_seqs是形状为n_steps的 Python 列表,包含形状为[None,n_inputs]的张量,其中第一个维度同样是最小批量大小。为此,我们首先使用transpose()函数交换前两个维度,以便时间步骤现在是第一维度。然后,我们使 unstack()函数沿第一维(即每个时间步的一个张量)提取张量的 Python 列表。接下来的两行和以前一样。最后,我们使用stack()函数将所有输出张量合并成一个张量,然后我们交换前两个维度得到最终输出张量,形状为[None, n_steps,n_neurons](第一个维度是小批量大小)。
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])X_seqs = tf.unstack(tf.transpose(X, perm=[1, 0, 2]))basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, X_seqs, dtype=tf.float32)outputs = tf.transpose(tf.stack(output_seqs), perm=[1, 0, 2])
现在我们可以通过给它提供一个包含所有小批量序列的张量来运行网络:
X_batch = np.array([ # t = 0 t = 1 [[0, 1, 2], [9, 8, 7]], # instance 1 [[3, 4, 5], [0, 0, 0]], # instance 2 [[6, 7, 8], [6, 5, 4]], # instance 3 [[9, 0, 1], [3, 2, 1]], # instance 4 ])with tf.Session() as sess: init.run() outputs_val = outputs.eval(feed_dict={X: X_batch})
我们得到所有实例,所有时间步长和所有神经元的单一outputs_val张量:
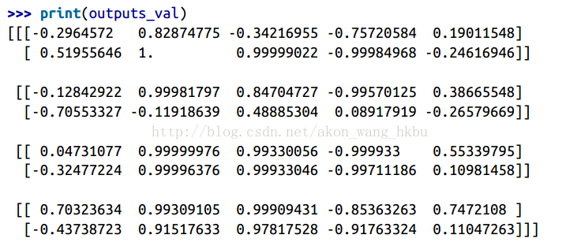
但是,这种方法仍然会建立一个每个时间步包含一个单元的图。 如果有 50 个时间步,这个图看起来会非常难看。 这有点像写一个程序而没有使用循环(例如,Y0 = f(0,X0);Y1 = f(Y0,X1);Y2 = f(Y1,X2);…;Y50 = f(Y49,X50))。 如果使用大图,在反向传播期间(特别是在 GPU 内存有限的情况下),你甚至可能会发生内存不足(OOM)错误,因为它必须在正向传递期间存储所有张量值,以便可以使用它们在反向传播期间计算梯度。
幸运的是,有一个更好的解决方案:dynamic_rnn()函数。
