 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签GoogLeNet
GoogLeNet 架构是由 Christian Szegedy 等人开发的。 来自 Google Research,通过低于 7% 的 top-5 错误率,赢得了 ILSVRC 2014 的挑战赛。 这个伟大的表现很大程度上因为它比以前的 CNN 网络更深(见图 13-11)。 这是通过称为初始模块(inception modules)的子网络实现的,这使得 GoogLeNet 比以前的架构更有效地使用参数:实际上,GoogLeNet 的参数比 AlexNet 少了 10 倍(约 600 万而不是 6000 万)。
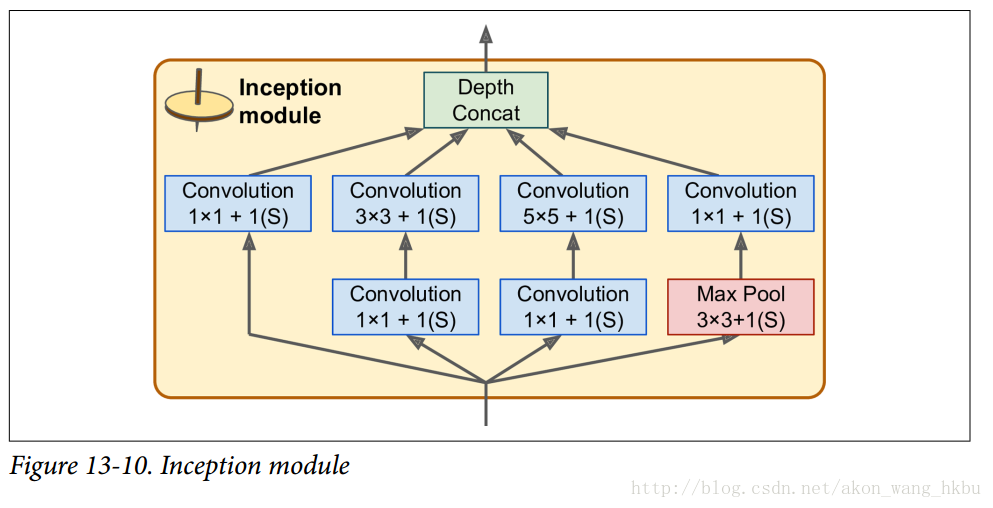
初始模块的架构如图 13-10 所示。 符号3×3 + 2(S)表示该层使用3×3内核,步幅 2 和SAME填充。 输入信号首先被复制并馈送到四个不同的层。 所有卷积层都使用 ReLU 激活功能。 请注意,第二组卷积层使用不同的内核大小(1×1,3×3和5×5),允许它们以不同的比例捕获图案。 还要注意,每一层都使用了跨度为1和SAME填充的(即使是最大的池化层),所以它们的输出全都具有与其输入相同的高度和宽度。这使得将所有输出在最后的深度连接层(depth concat layer)上沿着深度方向堆叠成为可能(即,堆叠来自所有四个顶部卷积层的特征映射)。 这个连接层可以在 TensorFlow 中使用concat()操作实现,其中axis = 3(轴 3 是深度)。
您可能想知道为什么初始模块具有1×1内核的卷积层。 当然这些图层不能捕获任何功能,因为他们一次只能看一个像素? 实际上,这些层次有两个目的:
首先,它们被配置为输出比输入少得多的特征映射,所以它们作为瓶颈层,意味着它们降低了维度。 在3×3和5×5卷积之前,这是特别有用的,因为这些在计算上是非常耗费内存的层。
其次,每一个卷积层对([1 × 1, 3 × 3]和[1 × 1, 5 × 5]表现地像一个强大的卷积层,可以捕捉到更多的复杂的模式。事实上,这一对卷积层不是在图像上扫过一个简单的线性分类器(就像单个卷积层一样),而是在图像上扫描一个双层神经网络。
简而言之,您可以将整个初始模块视为类固醇卷积层,能够输出捕捉各种尺度复杂模式的特征映射。
每个卷积层的卷积核的数量是一个超参数。 不幸的是,这意味着你有六个超参数来调整你添加的每个初始层。
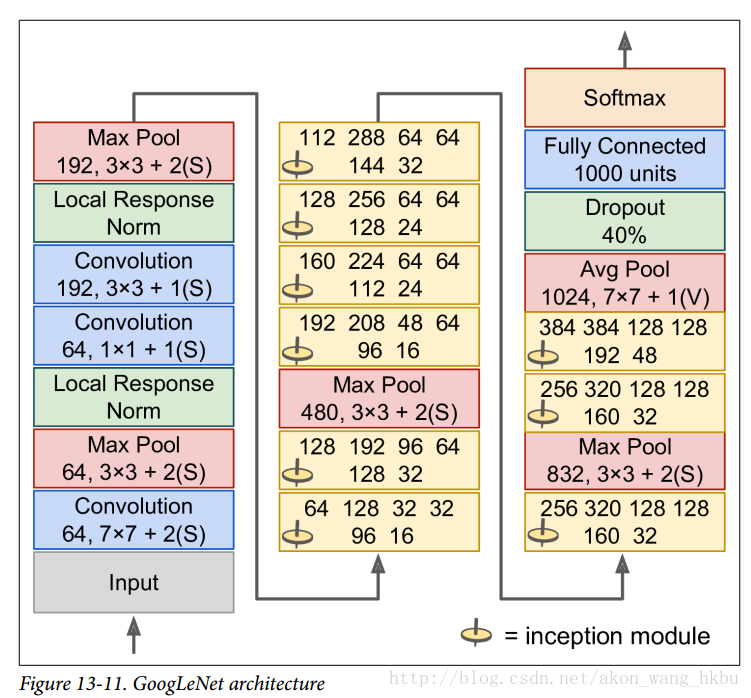
现在让我们来看看 GoogLeNet CNN 的架构(见图 13-11)。 它非常深,我们不得不将它分成三列,但是 GoogLeNet 实际上是一列,包括九个初始模块(带有旋转顶端的框),每个模块实际上包含三层。每个卷积层和池化层输出的特征映射的数量显示在内核大小前。 初始模块中的六个数字表示模块中每个卷积层输出的特征映射的数量(与图 13-10 中的顺序相同)。 请注意,所有的卷积层都使用 ReLU 激活函数。
让我们来过一遍这个网络:
- 前两层将图像的高度和宽度除以 4(使其面积除以 16),以减少计算负担。
- 然后,局部响应标准化层确保前面的层学习各种各样的功能(如前所述)
- 接下来是两个卷积层,其中第一个像瓶颈层一样。 正如前面所解释的,你可以把这一对看作是一个单一的更智能的卷积层。
- 再次,局部响应标准化层确保了先前的层捕捉各种各样的模式。
- 接下来,最大池化层将图像高度和宽度减少 2,再次加快计算速度。
- 然后是九个初始模块的堆叠,与几个最大池层交织,以降低维度并加速网络。
- 接下来,平均池化层使用具有
VALID填充的特征映射的大小的内核,输出1×1特征映射:这种令人惊讶的策略被称为全局平均池化。 它有效地强制以前的图层产生特征映射,这些特征映射实际上是每个目标类的置信图(因为其他类型的功能将被平均步骤破坏)。 这样在 CNN 的顶部就不必有有几个全连接层(如 AlexNet),大大减少了网络中的参数数量,并减少了了过度拟合的风险。 - 最后一层是不言自明的:正则化 drop out,然后是具有 softmax 激活函数的完全连接层来输出估计类的概率。
这个图略有简化:原来的 GoogLeNet 架构还包括两个插在第三和第六个初始模块之上的辅助分类器。 它们都由一个平均池层,一个卷积层,两个全连接层和一个 softmax 激活层组成。 在训练期间,他们的损失(缩小了 70%)加在了整体损失上。 目标是解决消失梯度问题,正则化网络。 但是,结果显示其效果相对小。
