 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签AdaGrad
再次考虑细长碗的问题:梯度下降从最陡峭的斜坡快速下降,然后缓慢地下到谷底。 如果算法能够早期检测到这个问题并且纠正它的方向来指向全局最优点,那将是非常好的。
AdaGrad 算法通过沿着最陡的维度缩小梯度向量来实现这一点(见公式 11-6):

第一步将梯度的平方累加到矢量s中(⊗符号表示单元乘法)。 这个向量化形式相当于向量s的每个元素si计算 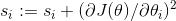 。换一种说法,每个
。换一种说法,每个 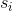 累加损失函数对参数
累加损失函数对参数 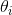 的偏导数的平方。 如果损失函数沿着第
的偏导数的平方。 如果损失函数沿着第i维陡峭,则在每次迭代时, 将变得越来越大。
第二步几乎与梯度下降相同,但有一个很大的不同:梯度矢量按比例缩小 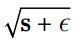 (
(⊘符号表示元素分割,ε是避免被零除的平滑项,通常设置为 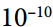 。 这个矢量化的形式相当于计算
。 这个矢量化的形式相当于计算 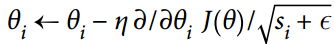 对于所有参数 (同时)。
对于所有参数 (同时)。
简而言之,这种算法会降低学习速度,但对于陡峭的尺寸,其速度要快于具有温和的斜率的尺寸。 这被称为自适应学习率。 它有助于将更新的结果更直接地指向全局最优(见图 11-7)。 另一个好处是它不需要那么多的去调整学习率超参数η。
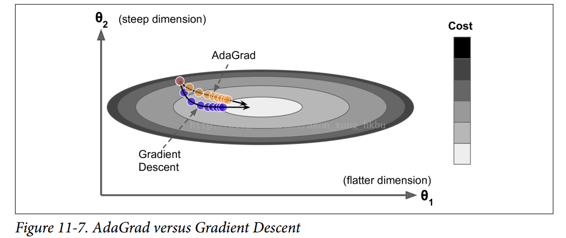
对于简单的二次问题,AdaGrad 经常表现良好,但不幸的是,在训练神经网络时,它经常停止得太早。 学习率被缩减得太多,以至于在达到全局最优之前,算法完全停止。 所以,即使 TensorFlow 有一个AdagradOptimizer,你也不应该用它来训练深度神经网络(虽然对线性回归这样简单的任务可能是有效的)。
