 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签训练序列分类器
我们训练一个 RNN 来分类 MNIST 图像。 卷积神经网络将更适合于图像分类(见第 13 章),但这是一个你已经熟悉的简单例子。 我们将把每个图像视为 28 行 28 像素的序列(因为每个MNIST图像是28×28像素)。 我们将使用 150 个循环神经元的单元,再加上一个全连接层,其中包含连接到上一个时间步的输出的 10 个神经元(每个类一个),然后是一个 softmax 层(见图 14-6)。
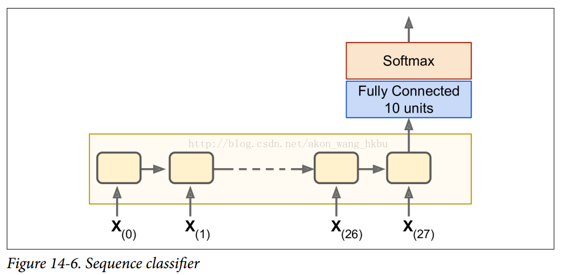
建模阶段非常简单, 它和我们在第 10 章中建立的 MNIST 分类器几乎是一样的,只是展开的 RNN 替换了隐层。 注意,全连接层连接到状态张量,其仅包含 RNN 的最终状态(即,第 28 个输出)。 另请注意,y是目标类的占位符。
n_steps = 28n_inputs = 28n_neurons = 150n_outputs = 10learning_rate = 0.001X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])y = tf.placeholder(tf.int32, [None])basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)outputs, states = tf.nn.dynamic_rnn(basic_cell, X, dtype=tf.float32)logits = tf.layers.dense(states, n_outputs)xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=logits)loss = tf.reduce_mean(xentropy)optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)training_op = optimizer.minimize(loss)correct = tf.nn.in_top_k(logits, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))init = tf.global_variables_initializer()
现在让我们加载 MNIST 数据,并按照网络的预期方式将测试数据重塑为[batch_size, n_steps, n_inputs]。 我们之后会关注训练数据的重塑。
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("/tmp/data/")X_test = mnist.test.images.reshape((-1, n_steps, n_inputs))y_test = mnist.test.labels
现在我们准备训练 RNN 了。 执行阶段与第 10 章中 MNIST 分类器的执行阶段完全相同,不同之处在于我们在将每个训练的批量提供给网络之前要重新调整。
batch_size = 150with tf.Session() as sess:init.run()for epoch in range(n_epochs):for iteration in range(mnist.train.num_examples // batch_size):X_batch, y_batch = mnist.train.next_batch(batch_size)X_batch = X_batch.reshape((-1, n_steps, n_inputs))sess.run(training_op, feed_dict={X: X_batch, y: y_batch})acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch})acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
输出应该是这样的:

我们获得了超过 98% 的准确性 - 不错! 另外,通过调整超参数,使用 He 初始化初始化 RNN 权重,更长时间训练或添加一些正则化(例如,droupout),你肯定会获得更好的结果。
你可以通过将其构造代码包装在一个变量作用域内(例如,使用variable_scope("rnn", initializer = variance_scaling_initializer())来使用 He 初始化)来为 RNN 指定初始化器。
