 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签学习率调整
找到一个好的学习速度可能会非常棘手。 如果设置太高,训练实际上可能偏离(如我们在第 4 章)。 如果设置得太低,训练最终会收敛到最佳状态,但这需要很长时间。 如果将其设置得太高,开始的进度会非常快,但最终会在最优解周围跳动,永远不会安顿下来(除非您使用自适应学习率优化算法,如 AdaGrad,RMSProp 或 Adam,但是 即使这样可能需要时间来解决)。 如果您的计算预算有限,那么您可能必须在正确收敛之前中断训练,产生次优解决方案(参见图 11-8)。
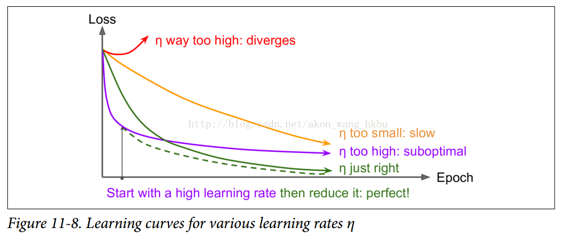
通过使用各种学习率和比较学习曲线,在几个迭代内对您的网络进行多次训练,您也许能够找到相当好的学习率。 理想的学习率将会快速学习并收敛到良好的解决方案。
然而,你可以做得比不断的学习率更好:如果你从一个高的学习率开始,然后一旦它停止快速的进步就减少它,你可以比最佳的恒定学习率更快地达到一个好的解决方案。 有许多不同的策略,以减少训练期间的学习率。 这些策略被称为学习率调整(我们在第 4 章中简要介绍了这个概念),其中最常见的是:
预定的分段恒定学习率:
例如,首先将学习率设置为 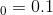 ,然后在 50 个迭代之后将学习率设置为
,然后在 50 个迭代之后将学习率设置为 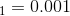 。虽然这个解决方案可以很好地工作,但是通常需要弄清楚正确的学习速度以及何时使用它们。
。虽然这个解决方案可以很好地工作,但是通常需要弄清楚正确的学习速度以及何时使用它们。
性能调度:
每 N 步测量验证误差(就像提前停止一样),当误差下降时,将学习率降低一个因子λ。
指数调度:
将学习率设置为迭代次数t的函数: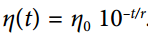 。 这很好,但它需要调整
。 这很好,但它需要调整η0和r。 学习率将由每r步下降 10 倍。
幂调度:
设学习率为 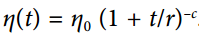 。 超参数
。 超参数c通常被设置为 1。这与指数调度类似,但是学习率下降要慢得多。
Andrew Senior 等2013年的论文。 比较了使用动量优化训练深度神经网络进行语音识别时一些最流行的学习率调整的性能。 作者得出结论:在这种情况下,性能调度和指数调度都表现良好,但他们更喜欢指数调度,因为它实现起来比较简单,容易调整,收敛速度略快于最佳解决方案。
使用 TensorFlow 实现学习率调整非常简单:
initial_learning_rate = 0.1decay_steps = 10000decay_rate = 1/10global_step = tf.Variable(0, trainable=False, name="global_step")learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,decay_steps, decay_rate)optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)training_op = optimizer.minimize(loss, global_step=global_step)
设置超参数值后,我们创建一个不可训练的变量global_step(初始化为 0)以跟踪当前的训练迭代次数。 然后我们使用 TensorFlow 的exponential_decay()函数来定义指数衰减的学习率(η0= 0.1和r = 10,000)。 接下来,我们使用这个衰减的学习率创建一个优化器(在这个例子中是一个MomentumOptimizer)。 最后,我们通过调用优化器的minimize()方法来创建训练操作;因为我们将global_step变量传递给它,所以请注意增加它。 就是这样!
由于 AdaGrad,RMSProp 和 Adam 优化自动降低了训练期间的学习率,因此不需要添加额外的学习率调整。 对于其他优化算法,使用指数衰减或性能调度可显著加速收敛。
完整代码:
n_inputs = 28 * 28 # MNISTn_hidden1 = 300n_hidden2 = 50n_outputs = 10X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y = tf.placeholder(tf.int64, shape=(None), name="y")with tf.name_scope("dnn"):hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")logits = tf.layers.dense(hidden2, n_outputs, name="outputs")with tf.name_scope("loss"):xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)loss = tf.reduce_mean(xentropy, name="loss")with tf.name_scope("eval"):correct = tf.nn.in_top_k(logits, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"): # not shown in the bookinitial_learning_rate = 0.1decay_steps = 10000decay_rate = 1/10global_step = tf.Variable(0, trainable=False, name="global_step")learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,decay_steps, decay_rate)optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)training_op = optimizer.minimize(loss, global_step=global_step)
init = tf.global_variables_initializer()saver = tf.train.Saver()
n_epochs = 5batch_size = 50with tf.Session() as sess:init.run()for epoch in range(n_epochs):for iteration in range(mnist.train.num_examples // batch_size):X_batch, y_batch = mnist.train.next_batch(batch_size)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,y: mnist.test.labels})print(epoch, "Test accuracy:", accuracy_val)save_path = saver.save(sess, "./my_model_final.ckpt")
