 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签使用真实数据
学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的地方:
- 流行的开源数据仓库:
- UC Irvine Machine Learning Repository
- Kaggle datasets
- Amazon’s AWS datasets
- 准入口(提供开源数据列表)
- http://dataportals.org/
- http://opendatamonitor.eu/
- http://quandl.com/
- 其它列出流行开源数据仓库的网页:
- Wikipedia’s list of Machine Learning datasets
- Quora.com question
- Datasets subreddit
本章,我们选择的是 StatLib 的加州房产价格数据集(见图 2-1)。这个数据集是基于 1990 年加州普查的数据。数据已经有点老(1990 年还能买一个湾区不错的房子),但是它有许多优点,利于学习,所以假设这个数据为最近的。为了便于教学,我们添加了一个类别属性,并除去了一些。
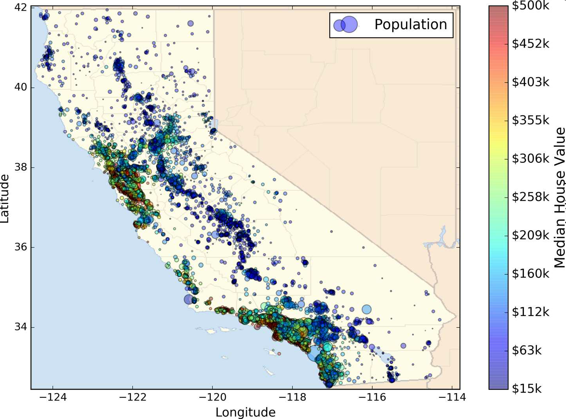
图 2-1 加州房产价格
