 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签基尼不纯度或是信息熵
通常,算法使用 Gini 不纯度来进行检测, 但是你也可以通过将标准超参数设置为"entropy"来使用熵不纯度进行检测。这里熵的概念是源于热力学中分子混乱程度的概念,当分子井然有序的时候,熵值接近于 0。
熵这个概念后来逐渐被扩展到了各个领域,其中包括香农的信息理论,这个理论被用于测算一段信息中的平均信息密度 [3]。当所有信息相同的时候熵被定义为零。
在机器学习中,熵经常被用作不纯度的衡量方式,当一个集合内只包含一类实例时, 我们称为数据集的熵为 0。
[3] 熵的减少通常称为信息增益。
公式 6-3 显示了第i个节点的熵的定义,例如,在图 6-1 中, 深度为 2 左节点的熵为 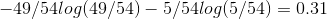 。
。
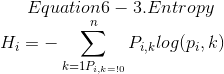
那么我们到底应该使用 Gini 指数还是熵呢? 事实上大部分情况都没有多大的差别:他们会生成类似的决策树。
基尼指数计算稍微快一点,所以这是一个很好的默认值。但是,也有的时候它们会产生不同的树,基尼指数会趋于在树的分支中将最多的类隔离出来,而熵指数趋向于产生略微平衡一些的决策树模型。
