 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签梯度下降
梯度下降是一种非常通用的优化算法,它能够很好地解决一系列问题。梯度下降的整体思路是通过的迭代来逐渐调整参数使得损失函数达到最小值。
假设浓雾下,你迷失在了大山中,你只能感受到自己脚下的坡度。为了最快到达山底,一个最好的方法就是沿着坡度最陡的地方下山。这其实就是梯度下降所做的:它计算误差函数关于参数向量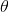 的局部梯度,同时它沿着梯度下降的方向进行下一次迭代。当梯度值为零的时候,就达到了误差函数最小值 。
的局部梯度,同时它沿着梯度下降的方向进行下一次迭代。当梯度值为零的时候,就达到了误差函数最小值 。
具体来说,开始时,需要选定一个随机的(这个值称为随机初始值),然后逐渐去改进它,每一次变化一小步,每一步都试着降低损失函数(例如:均方差损失函数),直到算法收敛到一个最小值(如图:4-3)。
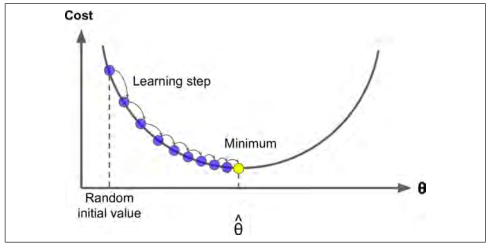
图 4-3:梯度下降
在梯度下降中一个重要的参数是步长,超参数学习率的值决定了步长的大小。如果学习率太小,必须经过多次迭代,算法才能收敛,这是非常耗时的(如图 4-4)。

图 4-4:学习率过小
另一方面,如果学习率太大,你将跳过最低点,到达山谷的另一面,可能下一次的值比上一次还要大。这可能使的算法是发散的,函数值变得越来越大,永远不可能找到一个好的答案(如图 4-5)。
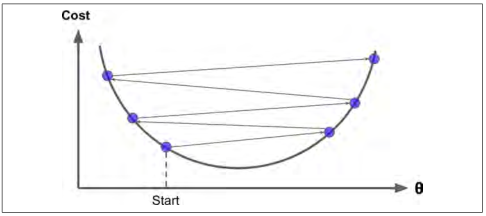
图 4-5:学习率过大
最后,并不是所有的损失函数看起来都像一个规则的碗。它们可能是洞,山脊,高原和各种不规则的地形,使它们收敛到最小值非常的困难。 图 4-6 显示了梯度下降的两个主要挑战:如果随机初始值选在了图像的左侧,则它将收敛到局部最小值,这个值要比全局最小值要大。 如果它从右侧开始,那么跨越高原将需要很长时间,如果你早早地结束训练,你将永远到不了全局最小值。
图 4-6:梯度下降的陷阱
幸运的是线性回归模型的均方差损失函数是一个凸函数,这意味着如果你选择曲线上的任意两点,它们的连线段不会与曲线发生交叉(译者注:该线段不会与曲线有第三个交点)。这意味着这个损失函数没有局部最小值,仅仅只有一个全局最小值。同时它也是一个斜率不能突变的连续函数。这两个因素导致了一个好的结果:梯度下降可以无限接近全局最小值。(只要你训练时间足够长,同时学习率不是太大 )。
事实上,损失函数的图像呈现碗状,但是不同特征的取值范围相差较大的时,这个碗可能是细长的。图 4-7 展示了梯度下降在不同训练集上的表现。在左图中,特征 1 和特征 2 有着相同的数值尺度。在右图中,特征 1 比特征2的取值要小的多,由于特征 1 较小,因此损失函数改变时,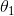 会有较大的变化,于是这个图像会在轴方向变得细长。
会有较大的变化,于是这个图像会在轴方向变得细长。
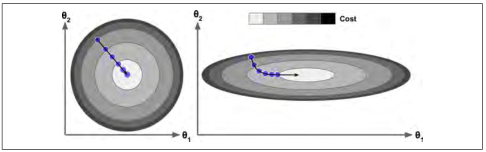
图 4-7:有无特征缩放的梯度下降
正如你看到的,左面的梯度下降可以直接快速地到达最小值,然而在右面的梯度下降第一次前进的方向几乎和全局最小值的方向垂直,并且最后到达一个几乎平坦的山谷,在平坦的山谷走了很长时间。它最终会达到最小值,但它需要很长时间。
提示
当我们使用梯度下降的时候,应该确保所有的特征有着相近的尺度范围(例如:使用 Scikit Learn 的
StandardScaler类),否则它将需要很长的时间才能够收敛。
这幅图也表明了一个事实:训练模型意味着找到一组模型参数,这组参数可以在训练集上使得损失函数最小。这是对于模型参数空间的搜索,模型的参数越多,参数空间的维度越多,找到合适的参数越困难。例如在300维的空间找到一枚针要比在三维空间里找到一枚针复杂的多。幸运的是线性回归模型的损失函数是凸函数,这个最优参数一定在碗的底部。
批量梯度下降
使用梯度下降的过程中,你需要计算每一个 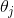 下损失函数的梯度。换句话说,你需要计算当变化一点点时,损失函数改变了多少。这称为偏导数,它就像当你面对东方的时候问:”我脚下的坡度是多少?”。然后面向北方的时候问同样的问题(如果你能想象一个超过三维的宇宙,可以对所有的方向都这样做)。公式 4-5 计算关于 的损失函数的偏导数,记为
下损失函数的梯度。换句话说,你需要计算当变化一点点时,损失函数改变了多少。这称为偏导数,它就像当你面对东方的时候问:”我脚下的坡度是多少?”。然后面向北方的时候问同样的问题(如果你能想象一个超过三维的宇宙,可以对所有的方向都这样做)。公式 4-5 计算关于 的损失函数的偏导数,记为 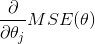 。
。
公式 4-5: 损失函数的偏导数
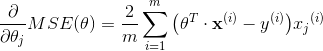
为了避免单独计算每一个梯度,你也可以使用公式 4-6 来一起计算它们。梯度向量记为 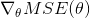 ,其包含了损失函数所有的偏导数(每个模型参数只出现一次)。
,其包含了损失函数所有的偏导数(每个模型参数只出现一次)。
公式 4-6:损失函数的梯度向量
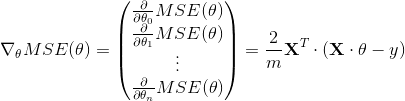
提示
在这个方程中每一步计算时都包含了整个训练集
,这也是为什么这个算法称为批量梯度下降:每一次训练过程都使用所有的的训练数据。因此,在大数据集上,其会变得相当的慢(但是我们接下来将会介绍更快的梯度下降算法)。然而,梯度下降的运算规模和特征的数量成正比。训练一个数千数量特征的线性回归模型使用*梯度下降要比使用正态方程快的多。
一旦求得了方向是上山的梯度向量,你就可以向着相反的方向去下山。这意味着从 中减去 。学习率 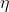 和梯度向量的积决定了下山时每一步的大小,如公式 4-7。
和梯度向量的积决定了下山时每一步的大小,如公式 4-7。
公式 4-7:梯度下降步长
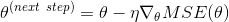
让我们看一下这个算法的应用:
eta = 0.1 # 学习率n_iterations = 1000m = 100theta = np.random.randn(2,1) # 随机初始值for iteration in range(n_iterations):gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)theta = theta - eta * gradiens
这不是太难,让我们看一下最后的结果 :
>>> thetaarray([[4.21509616],[2.77011339]])
看!正态方程的表现非常好。完美地求出了梯度下降的参数。但是当你换一个学习率会发生什么?图 4-8 展示了使用了三个不同的学习率进行梯度下降的前 10 步运算(虚线代表起始位置)。
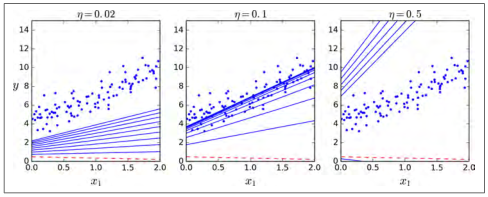
图 4-8:不同学习率的梯度下降
在左面的那副图中,学习率是最小的,算法几乎不能求出最后的结果,而且还会花费大量的时间。在中间的这幅图中,学习率的表现看起来不错,仅仅几次迭代后,它就收敛到了最后的结果。在右面的那副图中,学习率太大了,算法是发散的,跳过了所有的训练样本,同时每一步都离正确的结果越来越远。
为了找到一个好的学习率,你可以使用网格搜索(详见第二章)。当然,你一般会限制迭代的次数,以便网格搜索可以消除模型需要很长时间才能收敛这一个问题。
你可能想知道如何选取迭代的次数。如果它太小了,当算法停止的时候,你依然没有找到最优解。如果它太大了,算法会非常的耗时同时后来的迭代参数也不会发生改变。一个简单的解决方法是:设置一个非常大的迭代次数,但是当梯度向量变得非常小的时候,结束迭代。非常小指的是:梯度向量小于一个值  (称为容差)。这时候可以认为梯度下降几乎已经达到了最小值。
(称为容差)。这时候可以认为梯度下降几乎已经达到了最小值。
收敛速率:
当损失函数是凸函数,同时它的斜率不能突变(就像均方差损失函数那样),那么它的批量梯度下降算法固定学习率之后,它的收敛速率是
。换句话说,如果你将容差
随机梯度下降
批量梯度下降的最要问题是计算每一步的梯度时都需要使用整个训练集,这导致在规模较大的数据集上,其会变得非常的慢。与其完全相反的随机梯度下降,在每一步的梯度计算上只随机选取训练集中的一个样本。很明显,由于每一次的操作都使用了非常少的数据,这样使得算法变得非常快。由于每一次迭代,只需要在内存中有一个实例,这使随机梯度算法可以在大规模训练集上使用。
另一方面,由于它的随机性,与批量梯度下降相比,其呈现出更多的不规律性:它到达最小值不是平缓的下降,损失函数会忽高忽低,只是在大体上呈下降趋势。随着时间的推移,它会非常的靠近最小值,但是它不会停止在一个值上,它会一直在这个值附近摆动(如图 4-9)。因此,当算法停止的时候,最后的参数还不错,但不是最优值。
图4-9:随机梯度下降
当损失函数很不规则时(如图 4-6),随机梯度下降算法能够跳过局部最小值。因此,随机梯度下降在寻找全局最小值上比批量梯度下降表现要好。
虽然随机性可以很好的跳过局部最优值,但同时它却不能达到最小值。解决这个难题的一个办法是逐渐降低学习率。 开始时,走的每一步较大(这有助于快速前进同时跳过局部最小值),然后变得越来越小,从而使算法到达全局最小值。 这个过程被称为模拟退火,因为它类似于熔融金属慢慢冷却的冶金学退火过程。 决定每次迭代的学习率的函数称为learning schedule。 如果学习速度降低得过快,你可能会陷入局部最小值,甚至在到达最小值的半路就停止了。 如果学习速度降低得太慢,你可能在最小值的附近长时间摆动,同时如果过早停止训练,最终只会出现次优解。
下面的代码使用一个简单的learning schedule来实现随机梯度下降:
n_epochs = 50t0, t1 = 5, 50 # learning_schedule的超参数def learning_schedule(t):return t0 / (t + t1)theta = np.random.randn(2,1)for epoch in range(n_epochs):for i in range(m):random_index = np.random.randint(m)xi = X_b[random_index:random_index+1]yi = y[random_index:random_index+1]gradients = 2 * xi.T.dot(xi,dot(theta)-yi)eta = learning_schedule(epoch * m + i)theta = theta - eta * gradiens
按习惯来讲,我们进行 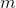 轮的迭代,每一轮迭代被称为一代。在整个训练集上,随机梯度下降迭代了 1000 次时,一般在第 50 次的时候就可以达到一个比较好的结果。
轮的迭代,每一轮迭代被称为一代。在整个训练集上,随机梯度下降迭代了 1000 次时,一般在第 50 次的时候就可以达到一个比较好的结果。
>>> thetaarray([[4.21076011],[2.748560791]])
图 4-10 展示了前 10 次的训练过程(注意每一步的不规则程度)。
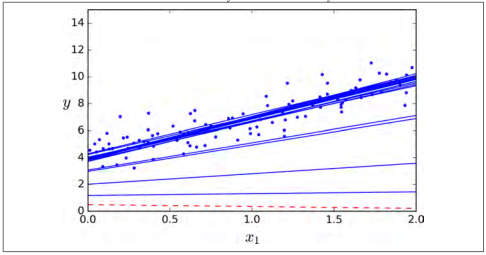
图 4-10:随机梯度下降的前10次迭代
由于每个实例的选择是随机的,有的实例可能在每一代中都被选到,这样其他的实例也可能一直不被选到。如果你想保证每一代迭代过程,算法可以遍历所有实例,一种方法是将训练集打乱重排,然后选择一个实例,之后再继续打乱重排,以此类推一直进行下去。但是这样收敛速度会非常的慢。
通过使用 Scikit-Learn 完成线性回归的随机梯度下降,你需要使用SGDRegressor类,这个类默认优化的是均方差损失函数。下面的代码迭代了 50 代,其学习率 为0.1(eta0=0.1),使用默认的learning schedule(与前面的不一样),同时也没有添加任何正则项(penalty = None):
from sklearn.linear_model import SGDRegressorsgd_reg + SGDRregressor(n_iter=50, penalty=None, eta0=0.1)sgd_reg.fit(X,y.ravel())
你可以再一次发现,这个结果非常的接近正态方程的解:
>>> sgd_reg.intercept_, sgd_reg.coef_(array([4.18380366]),array([2.74205299]))
小批量梯度下降
最后一个梯度下降算法,我们将介绍小批量梯度下降算法。一旦你理解了批量梯度下降和随机梯度下降,再去理解小批量梯度下降是非常简单的。在迭代的每一步,批量梯度使用整个训练集,随机梯度时候用仅仅一个实例,在小批量梯度下降中,它则使用一个随机的小型实例集。它比随机梯度的主要优点在于你可以通过矩阵运算的硬件优化得到一个较好的训练表现,尤其当你使用 GPU 进行运算的时候。
小批量梯度下降在参数空间上的表现比随机梯度下降要好的多,尤其在有大量的小型实例集时。作为结果,小批量梯度下降会比随机梯度更靠近最小值。但是,另一方面,它有可能陷在局部最小值中(在遇到局部最小值问题的情况下,和我们之前看到的线性回归不一样)。 图4-11显示了训练期间三种梯度下降算法在参数空间中所采用的路径。 他们都接近最小值,但批量梯度的路径最后停在了最小值,而随机梯度和小批量梯度最后都在最小值附近摆动。 但是,不要忘记,批次梯度需要花费大量时间来完成每一步,但是,如果你使用了一个较好的learning schedule,随机梯度和小批量梯度也可以得到最小值。
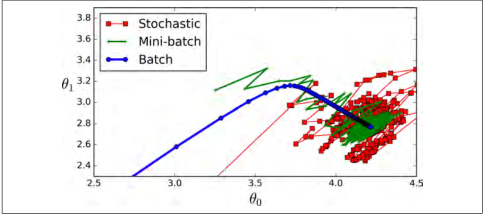
图 4-11:参数空间的梯度下降路径
让我比较一下目前我们已经探讨过的对线性回归的梯度下降算法。如表 4-1 所示,其中 表示训练样本的个数,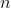 表示特征的个数。
表示特征的个数。
表 4-1:比较线性回归的不同梯度下降算法

提示
上述算法在完成训练后,得到的参数基本没什么不同,它们会得到非常相似的模型,最后会以一样的方式去进行预测。
