 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签最大范数正则化
另一种在神经网络中非常流行的正则化技术被称为最大范数正则化:对于每个神经元,它约束输入连接的权重w,使得 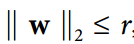 ,其中
,其中r是最大范数超参数,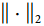 是 l2 范数。
是 l2 范数。
我们通常通过在每个训练步骤之后计算 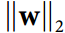 来实现这个约束,并且如果需要的话可以剪切
来实现这个约束,并且如果需要的话可以剪切W 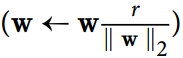 。
。
减少r增加了正则化的数量,并有助于减少过拟合。 最大范数正则化还可以帮助减轻梯度消失/爆炸问题(如果您不使用批量标准化)。
让我们回到 MNIST 的简单而简单的神经网络,只有两个隐藏层:
n_inputs = 28 * 28n_hidden1 = 300n_hidden2 = 50n_outputs = 10learning_rate = 0.01momentum = 0.9X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y = tf.placeholder(tf.int64, shape=(None), name="y")with tf.name_scope("dnn"):hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")logits = tf.layers.dense(hidden2, n_outputs, name="outputs")with tf.name_scope("loss"):xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)loss = tf.reduce_mean(xentropy, name="loss")with tf.name_scope("train"):optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)training_op = optimizer.minimize(loss)with tf.name_scope("eval"):correct = tf.nn.in_top_k(logits, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
接下来,让我们来处理第一个隐藏层的权重,并创建一个操作,使用clip_by_norm()函数计算剪切后的权重。 然后我们创建一个赋值操作来将权值赋给权值变量:
threshold = 1.0weights = tf.get_default_graph().get_tensor_by_name("hidden1/kernel:0")clipped_weights = tf.clip_by_norm(weights, clip_norm=threshold, axes=1)clip_weights = tf.assign(weights, clipped_weights)
我们也可以为第二个隐藏层做到这一点:
weights2 = tf.get_default_graph().get_tensor_by_name("hidden2/kernel:0")clipped_weights2 = tf.clip_by_norm(weights2, clip_norm=threshold, axes=1)clip_weights2 = tf.assign(weights2, clipped_weights2)
让我们添加一个初始化器和一个保存器:
init = tf.global_variables_initializer()saver = tf.train.Saver()
现在我们可以训练模型。 与往常一样,除了在运行training_op之后,我们运行clip_weights和clip_weights2操作:
n_epochs = 20batch_size = 50
with tf.Session() as sess: # not shown in the bookinit.run() # not shownfor epoch in range(n_epochs): # not shownfor iteration in range(mnist.train.num_examples // batch_size): # not shownX_batch, y_batch = mnist.train.next_batch(batch_size) # not shownsess.run(training_op, feed_dict={X: X_batch, y: y_batch})clip_weights.eval()clip_weights2.eval() # not shownacc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not showny: mnist.test.labels}) # not shownprint(epoch, "Test accuracy:", acc_test) # not shownsave_path = saver.save(sess, "./my_model_final.ckpt") # not shown
上面的实现很简单,工作正常,但有点麻烦。 更好的方法是定义一个max_norm_regularizer()函数:
def max_norm_regularizer(threshold, axes=1, name="max_norm",collection="max_norm"):def max_norm(weights):clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)clip_weights = tf.assign(weights, clipped, name=name)tf.add_to_collection(collection, clip_weights)return None # there is no regularization loss termreturn max_norm
然后你可以调用这个函数来得到一个最大范数调节器(与你想要的阈值)。 当你创建一个隐藏层时,你可以将这个正则化器传递给kernel_regularizer参数:
n_inputs = 28 * 28n_hidden1 = 300n_hidden2 = 50n_outputs = 10learning_rate = 0.01momentum = 0.9X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y = tf.placeholder(tf.int64, shape=(None), name="y")
max_norm_reg = max_norm_regularizer(threshold=1.0)with tf.name_scope("dnn"):hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,kernel_regularizer=max_norm_reg, name="hidden1")hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,kernel_regularizer=max_norm_reg, name="hidden2")logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)loss = tf.reduce_mean(xentropy, name="loss")with tf.name_scope("train"):optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)training_op = optimizer.minimize(loss)with tf.name_scope("eval"):correct = tf.nn.in_top_k(logits, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))init = tf.global_variables_initializer()saver = tf.train.Saver()
训练与往常一样,除了每次训练后必须运行重量裁剪操作:
请注意,最大范数正则化不需要在整体损失函数中添加正则化损失项,所以max_norm()函数返回None。 但是,在每个训练步骤之后,仍需要运行clip_weights操作,因此您需要能够掌握它。 这就是为什么max_norm()函数将clip_weights节点添加到最大范数剪裁操作的集合中的原因。您需要获取这些裁剪操作并在每个训练步骤后运行它们:
n_epochs = 20batch_size = 50
clip_all_weights = tf.get_collection("max_norm")with tf.Session() as sess:init.run()for epoch in range(n_epochs):for iteration in range(mnist.train.num_examples // batch_size):X_batch, y_batch = mnist.train.next_batch(batch_size)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})sess.run(clip_all_weights)acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown in the booky: mnist.test.labels}) # not shownprint(epoch, "Test accuracy:", acc_test) # not shownsave_path = saver.save(sess, "./my_model_final.ckpt") # not shown
