 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签项目概览
欢迎来到机器学习房地产公司!你的第一个任务是利用加州普查数据,建立一个加州房价模型。这个数据包含每个街区组的人口、收入中位数、房价中位数等指标。
街区组是美国调查局发布样本数据的最小地理单位(一个街区通常有 600 到 3000 人)。我们将其简称为“街区”。
你的模型要利用这个数据进行学习,然后根据其它指标,预测任何街区的的房价中位数。
提示:你是一个有条理的数据科学家,你要做的第一件事是拿出你的机器学习项目清单。你可以使用附录 B 中的清单;这个清单适用于大多数的机器学习项目,但是你还是要确认它是否满足需求。在本章中,我们会检查许多清单上的项目,但是也会跳过一些简单的,有些会在后面的章节再讨论。
划定问题
问老板的第一个问题应该是商业目标是什么?建立模型可能不是最终目标。公司要如何使用、并从模型受益?这非常重要,因为它决定了如何划定问题,要选择什么算法,评估模型性能的指标是什么,要花多少精力进行微调。
老板告诉你你的模型的输出(一个区的房价中位数)会传给另一个机器学习系统(见图 2-2),也有其它信号会传入后面的系统。这一整套系统可以确定某个区进行投资值不值。确定值不值得投资非常重要,它直接影响利润。
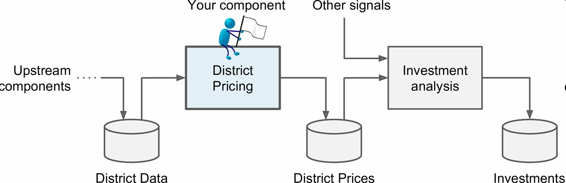
图 2-2 房地产投资的机器学习流水线
流水线
一系列的数据处理组件被称为数据流水线。流水线在机器学习系统中很常见,因为有许多数据要处理和转换。
组件通常是异步运行的。每个组件吸纳进大量数据,进行处理,然后将数据传输到另一个数据容器中,而后流水线中的另一个组件收入这个数据,然后输出,这个过程依次进行下去。每个组件都是独立的:组件间的接口只是数据容器。这样可以让系统更便于理解(记住数据流的图),不同的项目组可以关注于不同的组件。进而,如果一个组件失效了,下游的组件使用失效组件最后生产的数据,通常可以正常运行(一段时间)。这样就使整个架构相当健壮。
另一方面,如果没有监控,失效的组件会在不被注意的情况下运行一段时间。数据会受到污染,整个系统的性能就会下降。
下一个要问的问题是,现在的解决方案效果如何。老板通常会给一个参考性能,以及如何解决问题。老板说,现在街区的房价是靠专家手工估计的,专家队伍收集最新的关于一个区的信息(不包括房价中位数),他们使用复杂的规则进行估计。这种方法费钱费时间,而且估计结果不理想,误差率大概有 15%。
OK,有了这些信息,你就可以开始设计系统了。首先,你需要划定问题:监督或非监督,还是强化学习?这是个分类任务、回归任务,还是其它的?要使用批量学习还是线上学习?继续阅读之前,请暂停一下,尝试自己回答下这些问题。
你能回答出来吗?一起看下答案:很明显,这是一个典型的监督学习任务,因为你要使用的是有标签的训练样本(每个实例都有预定的产出,即街区的房价中位数)。并且,这是一个典型的回归任务,因为你要预测一个值。讲的更细些,这是一个多变量回归问题,因为系统要使用多个变量进行预测(要使用街区的人口,收入中位数等等)。在第一章中,你只是根据人均 GDP 来预测生活满意度,因此这是一个单变量回归问题。最后,没有连续的数据流进入系统,没有特别需求需要对数据变动作出快速适应。数据量不大可以放到内存中,因此批量学习就够了。
提示:如果数据量很大,你可以要么在多个服务器上对批量学习做拆分(使用 MapReduce 技术,后面会看到),或是使用线上学习。
选择性能指标
下一步是选择性能指标。回归问题的典型指标是均方根误差(RMSE)。均方根误差测量的是系统预测误差的标准差。例如,RMSE 等于 50000,意味着,68% 的系统预测值位于实际值的 50000 美元以内,95% 的预测值位于实际值的 100000 美元以内(一个特征通常都符合高斯分布,即满足 “68-95-99.7”规则:大约68%的值落在1σ内,95% 的值落在2σ内,99.7%的值落在3σ内,这里的σ等于50000)。公式 2-1 展示了计算 RMSE 的方法。
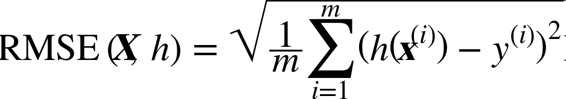
公式 2-1 均方根误差(RMSE)
符号的含义
这个方程引入了一些常见的贯穿本书的机器学习符号:
m是测量 RMSE 的数据集中的实例数量。
例如,如果用一个含有 2000 个街区的验证集求 RMSE,则m = 2000。
是数据集第
i个实例的所有特征值(不包含标签)的向量,是它的标签(这个实例的输出值)。
例如,如果数据集中的第一个街区位于经度 –118.29°,纬度 33.91°,有 1416 名居民,收入中位数是 38372 美元,房价中位数是 156400 美元(忽略掉其它的特征),则有:
和,
X是包含数据集中所有实例的所有特征值(不包含标签)的矩阵。每一行是一个实例,第i行是。
例如,仍然是前面提到的第一区,矩阵
X就是:
h是系统的预测函数,也称为假设(hypothesis)。当系统收到一个实例的特征向量(
读作
y-hat)。例如,如果系统预测第一区的房价中位数是 158400 美元,则
。预测误差是
。
RMSE(X,h)是使用假设h在样本集上测量的损失函数。我们使用小写斜体表示标量值(例如
或
)和函数名(例如
),小写粗体表示向量(例如
),大写粗体表示矩阵(例如
)。
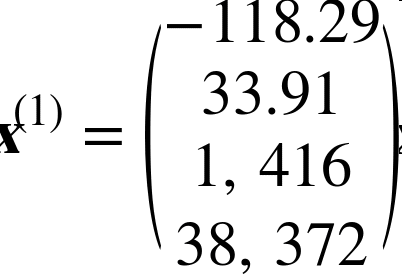
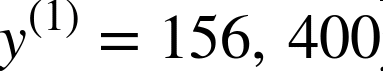

虽然大多数时候 RMSE 是回归任务可靠的性能指标,在有些情况下,你可能需要另外的函数。例如,假设存在许多异常的街区。此时,你可能需要使用平均绝对误差(Mean Absolute Error,也称作平均绝对偏差),见公式 2-2:
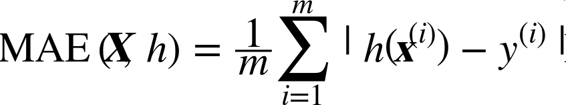
公式2-2 平均绝对误差
RMSE 和 MAE 都是测量预测值和目标值两个向量距离的方法。有多种测量距离的方法,或范数:
计算对应欧几里得范数的平方和的根(RMSE):这个距离介绍过。它也称作
ℓ2范数,标记为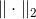 (或只是
(或只是  )。
)。计算对应于
ℓ1(标记为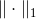 )范数的绝对值和(MAE)。有时,也称其为曼哈顿范数,因为它测量了城市中的两点,沿着矩形的边行走的距离。
)范数的绝对值和(MAE)。有时,也称其为曼哈顿范数,因为它测量了城市中的两点,沿着矩形的边行走的距离。更一般的,包含
n个元素的向量v的ℓk范数(K 阶闵氏范数),定义成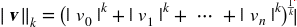
ℓ0(汉明范数)只显示了这个向量的基数(即,非零元素的个数),ℓ∞(切比雪夫范数)是向量中最大的绝对值。范数的指数越高,就越关注大的值而忽略小的值。这就是为什么 RMSE 比 MAE 对异常值更敏感。但是当异常值是指数分布的(类似正态曲线),RMSE 就会表现很好。
核实假设
最后,最好列出并核对迄今(你或其他人)作出的假设,这样可以尽早发现严重的问题。例如,你的系统输出的街区房价,会传入到下游的机器学习系统,我们假设这些价格确实会被当做街区房价使用。但是如果下游系统实际上将价格转化成了分类(例如,便宜、中等、昂贵),然后使用这些分类,而不是使用价格。这样的话,获得准确的价格就不那么重要了,你只需要得到合适的分类。问题相应地就变成了一个分类问题,而不是回归任务。你可不想在一个回归系统上工作了数月,最后才发现真相。
幸运的是,在与下游系统主管探讨之后,你很确信他们需要的就是实际的价格,而不是分类。很好!整装待发,可以开始写代码了。
