 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签Dropout
深度神经网络最流行的正则化技术可以说是 dropout。 它由 GE Hinton 于 2012 年提出,并在 Nitish Srivastava 等人的论文中进一步详细描述,并且已被证明是非常成功的:即使是最先进的神经网络,仅仅通过增加丢失就可以提高1-2%的准确度。 这听起来可能不是很多,但是当一个模型已经具有 95% 的准确率时,获得 2% 的准确度提升意味着将误差率降低近 40%(从 5% 误差降至大约 3%)。
这是一个相当简单的算法:在每个训练步骤中,每个神经元(包括输入神经元,但不包括输出神经元)都有一个暂时“丢弃”的概率p,这意味着在这个训练步骤中它将被完全忽略, 在下一步可能会激活(见图 11-9)。 超参数p称为丢失率,通常设为 50%。 训练后,神经元不会再下降。 这就是全部(除了我们将要讨论的技术细节)。
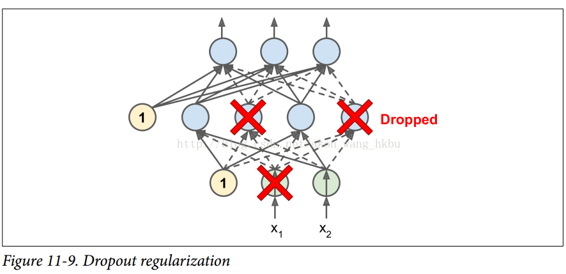
一开始这个技术是相当粗鲁,这是相当令人惊讶的。如果一个公司的员工每天早上被告知要掷硬币来决定是否上班,公司的表现会不会更好呢?那么,谁知道;也许会!公司显然将被迫适应这样的组织构架;它不能依靠任何一个人填写咖啡机或执行任何其他关键任务,所以这个专业知识将不得不分散在几个人身上。员工必须学会与其他的许多同事合作,而不仅仅是其中的一小部分。该公司将变得更有弹性。如果一个人离开了,并没有什么区别。目前还不清楚这个想法是否真的可以在公司实行,但它确实对于神经网络是可以的。神经元被dropout训练不能与其相邻的神经元共适应;他们必须尽可能让自己变得有用。他们也不能过分依赖一些输入神经元;他们必须注意他们的每个输入神经元。他们最终对输入的微小变化会不太敏感。最后,你会得到一个更强大的网络,更好地推广。
了解 dropout 的另一种方法是认识到每个训练步骤都会产生一个独特的神经网络。 由于每个神经元可以存在或不存在,总共有2 ^ N个可能的网络(其中 N 是可丢弃神经元的总数)。 这是一个巨大的数字,实际上不可能对同一个神经网络进行两次采样。 一旦你运行了 10,000 个训练步骤,你基本上已经训练了 10,000 个不同的神经网络(每个神经网络只有一个训练实例)。 这些神经网络显然不是独立的,因为它们共享许多权重,但是它们都是不同的。 由此产生的神经网络可以看作是所有这些较小的神经网络的平均集成。
有一个小而重要的技术细节。 假设p = 50%,在这种情况下,在测试期间,在训练期间神经元将被连接到两倍于(平均)的输入神经元。 为了弥补这个事实,我们需要在训练之后将每个神经元的输入连接权重乘以 0.5。 如果我们不这样做,每个神经元的总输入信号大概是网络训练的两倍,这不太可能表现良好。 更一般地说,我们需要将每个输入连接权重乘以训练后的保持概率(1-p)。 或者,我们可以在训练过程中将每个神经元的输出除以保持概率(这些替代方案并不完全等价,但它们工作得同样好)。
要使用 TensorFlow 实现dropout,可以简单地将dropout()函数应用于输入层和每个隐藏层的输出。 在训练过程中,这个功能随机丢弃一些节点(将它们设置为 0),并用保留概率来划分剩余项目。 训练结束后,这个函数什么都不做。下面的代码将dropout正则化应用于我们的三层神经网络:
注意:本书使用tf.contrib.layers.dropout()而不是tf.layers.dropout()(本章写作时不存在)。 现在最好使用tf.layers.dropout(),因为contrib模块中的任何内容都可能会改变或被删除,恕不另行通知。tf.layers.dropout()函数几乎与tf.contrib.layers.dropout()函数相同,只是有一些细微差别。 最重要的是:
- 您必须指定丢失率(率)而不是保持概率(
keep_prob),其中rate简单地等于1 - keep_prob is_training参数被重命名为training。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y = tf.placeholder(tf.int64, shape=(None), name="y")
training = tf.placeholder_with_default(False, shape=(), name='training')dropout_rate = 0.5 # == 1 - keep_probX_drop = tf.layers.dropout(X, dropout_rate, training=training)with tf.name_scope("dnn"):hidden1 = tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu,name="hidden1")hidden1_drop = tf.layers.dropout(hidden1, dropout_rate, training=training)hidden2 = tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu,name="hidden2")hidden2_drop = tf.layers.dropout(hidden2, dropout_rate, training=training)logits = tf.layers.dense(hidden2_drop, n_outputs, name="outputs")
with tf.name_scope("loss"):xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)loss = tf.reduce_mean(xentropy, name="loss")with tf.name_scope("train"):optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)training_op = optimizer.minimize(loss)with tf.name_scope("eval"):correct = tf.nn.in_top_k(logits, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))init = tf.global_variables_initializer()saver = tf.train.Saver()
n_epochs = 20batch_size = 50with tf.Session() as sess:init.run()for epoch in range(n_epochs):for iteration in range(mnist.train.num_examples // batch_size):X_batch, y_batch = mnist.train.next_batch(batch_size)sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels})print(epoch, "Test accuracy:", acc_test)save_path = saver.save(sess, "./my_model_final.ckpt")
你想在tensorflow.contrib.layers中使用dropout()函数,而不是tensorflow.nn中的那个。 第一个在不训练的时候关掉(没有操作),这是你想要的,而第二个不是。
如果观察到模型过拟合,则可以增加 dropout 率(即,减少keep_prob超参数)。 相反,如果模型欠拟合训练集,则应尝试降低 dropout 率(即增加keep_prob)。 它也可以帮助增加大层的 dropout 率,并减少小层的 dropout 率。
dropout 似乎减缓了收敛速度,但通常会在调整得当时使模型更好。 所以,这通常值得花费额外的时间和精力。
Dropconnect是dropout的变体,其中单个连接随机丢弃而不是整个神经元。 一般而言,dropout表现会更好。
