 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- TensorBoard:训练过程可视化
TensorBoard:训练过程可视化
有时,你希望查看模型训练过程中各个参数的变化情况(例如损失函数loss的值)。虽然可以通过命令行输出来查看,但有时显得不够直观。而TensorBoard就是一个能够帮助我们将训练过程可视化的工具。
首先在代码目录下建立一个文件夹(如 ./tensorboard )存放TensorBoard的记录文件,并在代码中实例化一个记录器:
- summary_writer = tf.summary.create_file_writer('./tensorboard') # 参数为记录文件所保存的目录
接下来,当需要记录训练过程中的参数时,通过with语句指定希望使用的记录器,并对需要记录的参数(一般是scalar)运行 tf.summary.scalar(name, tensor, step=batch_index) ,即可将训练过程中参数在step时候的值记录下来。这里的step参数可根据自己的需要自行制定,一般可设置为当前训练过程中的batch序号。整体框架如下:
- summary_writer = tf.summary.create_file_writer('./tensorboard')
- # 开始模型训练
- for batch_index in range(num_batches):
- # ...(训练代码,当前batch的损失值放入变量loss中)
- with summary_writer.as_default(): # 希望使用的记录器
- tf.summary.scalar("loss", loss, step=batch_index)
- tf.summary.scalar("MyScalar", my_scalar, step=batch_index) # 还可以添加其他自定义的变量
每运行一次 tf.summary.scalar() ,记录器就会向记录文件中写入一条记录。除了最简单的标量(scalar)以外,TensorBoard还可以对其他类型的数据(如图像,音频等)进行可视化,详见 TensorBoard文档 。
当我们要对训练过程可视化时,在代码目录打开终端(如需要的话进入TensorFlow的conda环境),运行:
- tensorboard --logdir=./tensorboard
然后使用浏览器访问命令行程序所输出的网址(一般是http://计算机名称:6006),即可访问TensorBoard的可视界面,如下图所示:
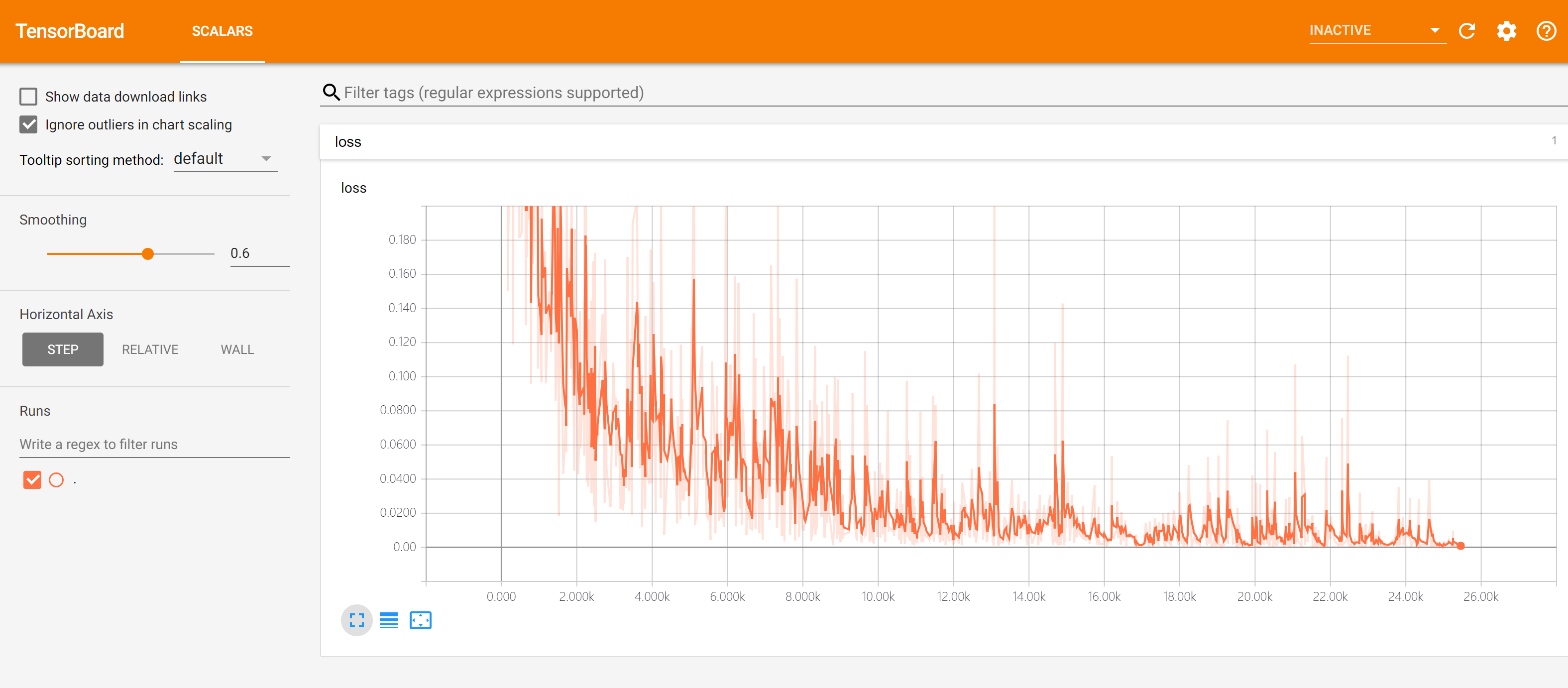
默认情况下,TensorBoard每30秒更新一次数据。不过也可以点击右上角的刷新按钮手动刷新。
TensorBoard的使用有以下注意事项:
如果需要重新训练,需要删除掉记录文件夹内的信息并重启TensorBoard(或者建立一个新的记录文件夹并开启TensorBoard,
—logdir参数设置为新建立的文件夹);记录文件夹目录保持全英文。
最后提供一个实例,以前章的 多层感知机模型 为例展示TensorBoard的使用:
- import tensorflow as tf
- from zh.model.mnist.mlp import MLP
- from zh.model.utils import MNISTLoader
- num_batches = 10000
- batch_size = 50
- learning_rate = 0.001
- model = MLP()
- data_loader = MNISTLoader()
- optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
- summary_writer = tf.summary.create_file_writer('./tensorboard') # 实例化记录器
- for batch_index in range(num_batches):
- X, y = data_loader.get_batch(batch_size)
- with tf.GradientTape() as tape:
- y_pred = model(X)
- loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
- loss = tf.reduce_mean(loss)
- print("batch %d: loss %f" % (batch_index, loss.numpy()))
- with summary_writer.as_default(): # 指定记录器
- tf.summary.scalar("loss", loss, step=batch_index) # 将当前损失函数的值写入记录器
- grads = tape.gradient(loss, model.variables)
- optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
