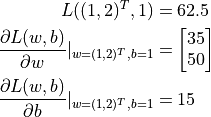我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 自动求导机制
自动求导机制
在机器学习中,我们经常需要计算函数的导数。TensorFlow提供了强大的 自动求导机制 来计算导数。以下代码展示了如何使用 tf.GradientTape() 计算函数 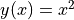 在
在 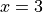 时的导数:
时的导数:
- import tensorflow as tf
- x = tf.Variable(initial_value=3.)
- with tf.GradientTape() as tape: # 在 tf.GradientTape() 的上下文内,所有计算步骤都会被记录以用于求导
- y = tf.square(x)
- y_grad = tape.gradient(y, x) # 计算y关于x的导数
- print([y, y_grad])
输出:
- [array([9.], dtype=float32), array([6.], dtype=float32)]
这里 x 是一个初始化为3的 变量 (Variable),使用 tf.Variable() 声明。与普通张量一样,变量同样具有形状、类型和值三种属性。使用变量需要有一个初始化过程,可以通过在 tf.Variable() 中指定 initial_value 参数来指定初始值。这里将变量 x 初始化为 3. 1。变量与普通张量的一个重要区别是其默认能够被TensorFlow的自动求导机制所求导,因此往往被用于定义机器学习模型的参数。
tf.GradientTape() 是一个自动求导的记录器,在其中的变量和计算步骤都会被自动记录。在上面的示例中,变量 x 和计算步骤 y = tf.square(x) 被自动记录,因此可以通过 y_grad = tape.gradient(y, x) 求张量 y 对变量 x 的导数。
在机器学习中,更加常见的是对多元函数求偏导数,以及对向量或矩阵的求导。这些对于TensorFlow也不在话下。以下代码展示了如何使用 tf.GradientTape() 计算函数 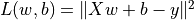 在
在 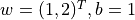 时分别对
时分别对 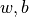 的偏导数。其中
的偏导数。其中 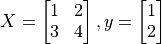 。
。
- X = tf.constant([[1., 2.], [3., 4.]])
- y = tf.constant([[1.], [2.]])
- w = tf.Variable(initial_value=[[1.], [2.]])
- b = tf.Variable(initial_value=1.)
- with tf.GradientTape() as tape:
- L = 0.5 * tf.reduce_sum(tf.square(tf.matmul(X, w) + b - y))
- w_grad, b_grad = tape.gradient(L, [w, b]) # 计算L(w, b)关于w, b的偏导数
- print([L.numpy(), w_grad.numpy(), b_grad.numpy()])
输出:
- [62.5, array([[35.],
- [50.]], dtype=float32), array([15.], dtype=float32)]
这里, tf.square() 操作代表对输入张量的每一个元素求平方,不改变张量形状。 tf.reduce_sum() 操作代表对输入张量的所有元素求和,输出一个形状为空的纯量张量(可以通过 axis 参数来指定求和的维度,不指定则默认对所有元素求和)。TensorFlow中有大量的张量操作API,包括数学运算、张量形状操作(如 tf.reshape())、切片和连接(如 tf.concat())等多种类型,可以通过查阅TensorFlow的官方API文档 2 来进一步了解。
从输出可见,TensorFlow帮助我们计算出了