 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 7.8.构建字梯图
7.8.构建字梯图
我们的第一个问题是弄清楚如何将大量的单词集合转换为图。 如果两个词只有一个字母不同,我们就创建从一个词到另一个词的边。如果我们可以创建这样的图,则从一个词到另一个词的任意路径就是词梯子拼图的解决方案。 Figure 1展示了一些解决 FOOL 到 SAGE 字梯问题的单词的小图。 请注意,图是无向图,边未加权。
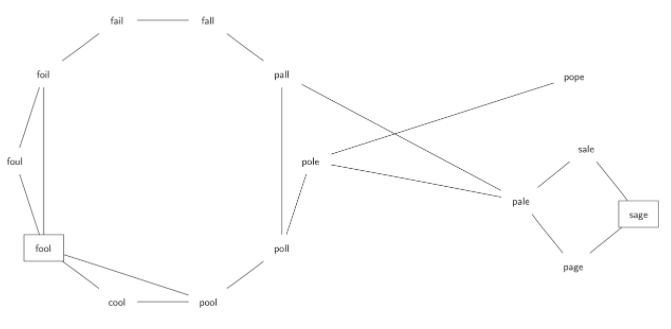
Figure 1
我们可以使用几种不同的方法来创建解决这个问题的图。假设我们有一个长度相同的单词列表。作为起点,我们可以在图中为列表中的每个单词创建一个顶点。为了弄清楚如何连接单词,我们可以比较列表中的每个单词。比较时我们看有多少字母是不同的。如果所讨论的两个字只有一个字母不同,我们可以在图中创建它们之间的边。对于小的列表,这种方法会正常工作;然而假设我们有一个 5,110 词的列表。粗略地说,将一个字与列表上的每个其他词进行比较是
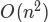 。对于5110 个词,
。对于5110 个词,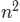 是超过2600万的比较。
是超过2600万的比较。
我们可以通过以下方法做得更好。假设我们有大量的桶,每个桶在外面有一个四个字母的单词,除了标签中的一个字母已经被下划线替代。例如,看 Figure 2,我们可能有一个标记为 “pop” 的桶。当我们处理列表中的每个单词时,我们使用 “\” 作为通配符比较每个桶的单词,所以 “pope” 和 “pops “ 将匹配 ”pop_“。每次我们找到一个匹配的桶,我们就把单词放在那个桶。一旦我们把所有单词放到适当的桶中,就知道桶中的所有单词必须连接。
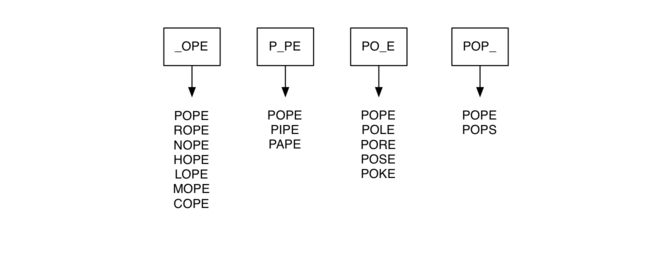
Figure 2
在 Python 中,我们使用字典来实现我们刚才描述的方案。我们刚才描述的桶上的标签是我们字典中的键。该键存储的值是单词列表。 一旦我们建立了字典,我们可以创建图。 我们通过为图中的每个单词创建一个顶点来开始图。 然后,我们在字典中的相同键下找到的所有顶点创建边。 Listing 1 展示了构建图所需的 Python 代码。
from pythonds.graphs import Graphdef buildGraph(wordFile):d = {}g = Graph()wfile = open(wordFile,'r')# create buckets of words that differ by one letterfor line in wfile:word = line[:-1]for i in range(len(word)):bucket = word[:i] + '_' + word[i+1:]if bucket in d:d[bucket].append(word)else:d[bucket] = [word]# add vertices and edges for words in the same bucketfor bucket in d.keys():for word1 in d[bucket]:for word2 in d[bucket]:if word1 != word2:g.addEdge(word1,word2)return g
Listing 1
因为这是我们的第一个真实世界图问题,你可能想知道图是如何稀疏?这个问题的四个字母的单词列表是 5,110 字长。 如果我们使用邻接矩阵,则矩阵将具有5,110 * 5,110 = 26,112,100 个格。 由 buildGraph 函数构造的图正好有 53,286 个边,所以矩阵只有 0.20% 的单元格填充! 这是一个非常稀疏的矩阵。
