 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 3.21.实现无序列表:链表
- 3.21.1.Node 类
- 3.21.2.Unordered List 类
3.21.实现无序列表:链表
为了实现无序列表,我们将构造通常所知的链表。回想一下,我们需要确保我们可以保持项的相对定位。然而,没有要求我们维持在连续存储器中的定位。例如,考虑 Figure 1 中所示的项的集合。看来这些值已被随机放置。如果我们可以在每个项中保持一些明确的信息,即下一个项的位置(参见 Figure 2),则每个项的相对位置可以通过简单地从一个项到下一个项的链接来表示。

Figure 1
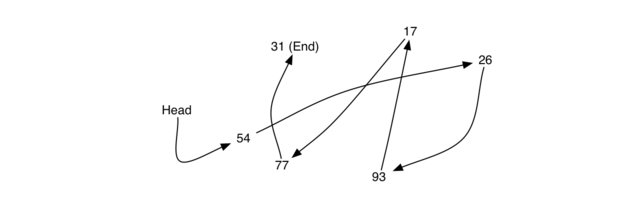
Figure 2
要注意,必须明确地指定链表的第一项的位置。一旦我们知道第一个项在哪里,第一个项目可以告诉我们第二个是什么,等等。外部引用通常被称为链表的头。类似地,最后一个项需要知道没有下一个项。
3.21.1.Node 类
链表实现的基本构造块是节点。每个节点对象必须至少保存两个信息。首先,节点必须包含列表项本身。我们将这个称为节点的数据字段。此外,每个节点必须保存对下一个节点的引用。 Listing 1 展示了 Python 实现。要构造一个节点,需要提供该节点的初始数据值。下面的赋值语句将产生一个包含值 93 的节点对象(见 Figure 3)。应该注意,我们通常会如 Figure 4 所示表示一个节点对象。Node 类还包括访问,修改数据和访问下一个引用的常用方法。
class Node:def __init__(self,initdata):self.data = initdataself.next = Nonedef getData(self):return self.datadef getNext(self):return self.nextdef setData(self,newdata):self.data = newdatadef setNext(self,newnext):self.next = newnext
Listing 1
我们创建一个 Node 对象
>>> temp = Node(93)>>> temp.getData()93
Python 引用值 None 将在 Node 类和链表本身发挥重要作用。引用 None 代表没有下一个节点。请注意在构造函数中,最初创建的节点 next 被设置为 None。有时这被称为 接地节点,因此我们使用标准接地符号表示对 None 的引用。将 None 显式的分配给初始下一个引用值是个好主意。
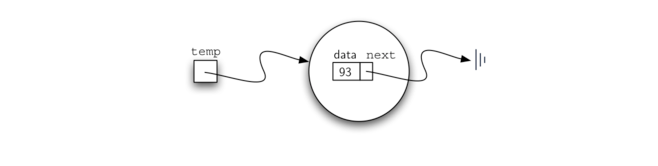
Figure 3

Figure 4
3.21.2.Unordered List 类
如上所述,无序列表将从一组节点构建,每个节点通过显式引用链接到下一个节点。只要我们知道在哪里找到第一个节点(包含第一个项),之后的每个项可以通过连续跟随下一个链接找到。考虑到这一点,UnorderedList 类必须保持对第一个节点的引用。Listing 2 显示了构造函数。注意,每个链表对象将维护对链表头部的单个引用。
class UnorderedList:def __init__(self):self.head = None
Listing 2
我们构建一个空的链表。赋值语句
>>> mylist = UnorderedList()
创建如 Figure 5 所示的链表。正如我们在 Node 类中讨论的,特殊引用 None 将再次用于表示链表的头部不引用任何内容。最终,先前给出的示例列表如 Figure 6 所示的链接列表表示。链表的头指代列表的第一项的第一节点。反过来,该节点保存对下一个节点(下一个项)的引用,等等。重要的是注意链表类本身不包含任何节点对象。相反,它只包含对链接结构中第一个节点的单个引用。

Figure 5
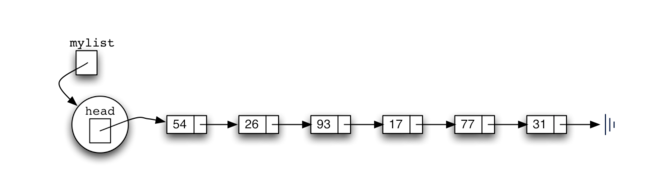
Figure 6
Listing 3 中所示的 isEmpty 方法只是检查链表头是否是 None 的引用。 布尔表达式 self.head == None 的结果只有在链表中没有节点时才为真。由于新链表为空,因此构造函数和空检查必须彼此一致。这显示了使用引用 None 来表示链接结构的 end 的优点。在 Python 中,None 可以与任何引用进行比较。如果它们都指向相同的对象,则两个引用是相等的。我们将在其他方法中经常使用它。
def isEmpty(self):return self.head == None
Listing 3
那么,我们如何将项加入我们的链表?我们需要实现 add 方法。然而,在我们做这一点之前,我们需要解决在链表中哪个位置放置新项的重要问题。由于该链表是无序的,所以新项相对于已经在列表中的其他项的特定位置并不重要。 新项可以在任何位置。考虑到这一点,将新项放在最简单的位置是有意义的。
回想一下,链表结构只为我们提供了一个入口点,即链表的头部。所有其他节点只能通过访问第一个节点,然后跟随下一个链接到达。这意味着添加新节点的最简单的地方就在链表的头部。 换句话说,我们将新项作为链表的第一项,现有项将需要链接到这个新项后。
Figure 6 展示了链表调用多次 add 函数的操作
>>> mylist.add(31)>>> mylist.add(77)>>> mylist.add(17)>>> mylist.add(93)>>> mylist.add(26)>>> mylist.add(54)
Figure 6
因为 31 是添加到链表的第一个项,它最终将是链表中的最后一个节点,因为每个其他项在其前面添加。此外,由于 54 是添加的最后一项,它将成为链表的第一个节点中的数据值。
add 方法如 Listing 4 所示。链表的每项必须驻留在节点对象中。第 2 行创建一个新节点并将该项作为其数据。现在我们必须通过将新节点链接到现有结构中来完成该过程。这需要两个步骤,如 Figure 7 所示。步骤1(行3)更改新节点的下一个引用以引用旧链表的第一个节点。现在,链表的其余部分已经正确地附加到新节点,我们可以修改链表的头以引用新节点。第 4 行中的赋值语句设置列表的头。
上述两个步骤的顺序非常重要。如果第 3 行和第 4 行的顺序颠倒,会发生什么?如果链表头部的修改首先发生,则结果可以在 Figure 8 中看到。由于 head 是链表节点的唯一外部引用,所有原始节点都将丢失并且不能再被访问。
def add(self,item):temp = Node(item)temp.setNext(self.head)self.head = temp
Listing 4
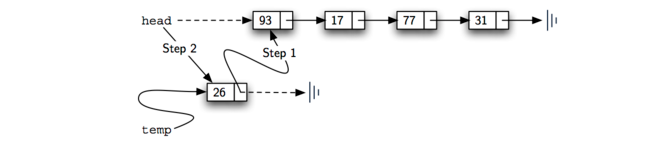
Figure 7
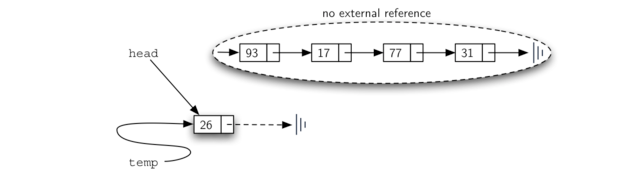
Figure 8
我们将实现的下面的方法 - size,search 和 remove - 都基于一种称为链表遍历的技术。遍历是指系统地访问每个节点的过程。为此,我们使用从链表中第一个节点开始的外部引用。当我们访问每个节点时,我们通过“遍历”下一个引用来移动到对下一个节点的引用。
要实现 size 方法,我们需要遍历链表并对节点数计数。Listing 5 展示了用于计算列表中节点数的 Python 代码。外部引用称为 current,并在第二行被初始化到链表的头部。开始的时候,我们没有看到任何节点,所以计数设置为 0 。第 4-6 行实际上实现了遍历。只要当前引用没到链表的结束位置(None),我们通过第 6 行中的赋值语句将当前元素移动到下一个节点。再次,将引用与 None 进行比较的能力是非常有用的。每当 current 移动到一个新的节点,我们加 1 以计数。最后,count 在迭代停止后返回。Figure 9 展示了处理这个链表的过程。
def size(self):current = self.headcount = 0while current != None:count = count + 1current = current.getNext()return count
Listing 5
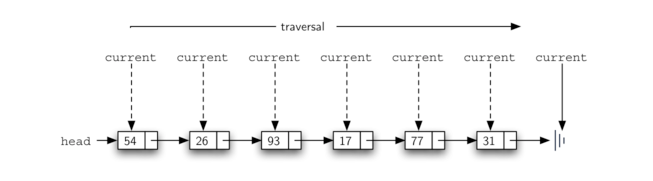
Figure 9
在链表中搜索也使用遍历技术。当我们访问链表中的每个节点时,我们将询问存储在其中的数据是否与我们正在寻找的项匹配。然而,在这种情况下,我们不必一直遍历到列表的末尾。事实上,如果我们到达链表的末尾,这意味着我们正在寻找的项不存在。此外,如果我们找到项,没有必要继续。
Listing 6 展示了搜索方法的实现。和在 size 方法中一样,遍历从列表的头部开始初始化(行2)。我们还使用一个布尔变量叫 found,标记我们是否找到了正在寻找的项。因为我们还没有在遍历开始时找到该项,found 设置为 False(第3行)。第4行中的迭代考虑了上述两个条件。只要有更多的节点访问,而且我们没有找到正在寻找的项,我们就继续检查下一个节点。第 5 行检查数据项是否存在于当前节点中。如果存在,found 设置为 True。
def search(self,item):current = self.headfound = Falsewhile current != None and not found:if current.getData() == item:found = Trueelse:current = current.getNext()return found
Listing 6
作为一个例子,试试调用 search 方法来查找 item 17
>>> mylist.search(17)True
因为 17 在列表中,所以遍历过程需要移动到包含 17 的节点。此时,found 变量设置为 True,while 条件将失败,返回值。 这个过程可以在 Figure 10中看到。
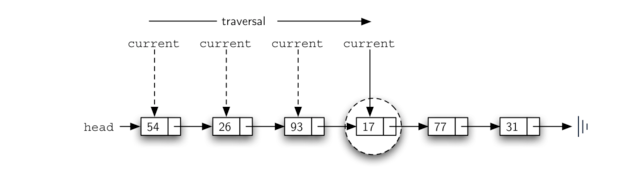
Figure 10
remove 方法需要两个逻辑步骤。首先,我们需要遍历列表寻找我们要删除的项。一旦我们找到该项(我们假设它存在),删除它。第一步非常类似于搜索。从设置到链表头部的外部引用开始,我们遍历链接,直到我们发现正在寻找的项。因为我们假设项存在,我们知道迭代将在 current 变为 None 之前停止。这意味着我们可以简单地使用 found 布尔值。
当 found 变为 True 时,current 将是对包含要删除的项的节点的引用。但是我们如何删除呢?一种方法是用标示该项目不再存在的某个标记来替换项目的值。这种方法的问题是节点数量将不再匹配项数量。最好通过删除整个节点来删除该项。
为了删除包含项的节点,我们需要修改上一个节点中的链接,以便它指向当前之后的节点。不幸的是,链表遍历没法回退。因为 current 指我们想要进行改变的节点之前的节点,所以进行修改太迟了。
这个困境的解决方案是在我们遍历链表时使用两个外部引用。current 将像之前一样工作,标记遍历的当前位置。新的引用,我们叫 previous,将总是传递 current后面的一个节点 。这样,当 current 停止在要被去除的节点时,previous 将引用链表中用于修改的位置。
Listing 7 展示了完整的 remove 方法。第 2-3 行给这两个引用赋初始值。注意,current 在链表头处开始,和在其他遍历示例中一样。然而,previous 假定总是在 current之后一个节点。因此,由于在 previous 之前没有节点,所以之前的值将为 None(见 Figure 11)。found 的布尔变量将再次用于控制迭代。
在第 6-7 行中,我们检查存储在当前节点中的项是否是我们希望删除的项。如果是,found 设置为 True 。如果我们没有找到该项,则 previous 和 current 都必须向前移动一个节点。同样,这两个语句的顺序是至关重要的。previous 必须先将一个节点移动到 current 的位置。此时,才可以移动current。这个过程通常被称为“英寸蠕动”,因为 previous 必须赶上 current,然后 current 前进。Figure 12 展示了 previous 和current 的移动,它们沿着链表向下移动,寻找包含值 17 的节点。
def remove(self,item):current = self.headprevious = Nonefound = Falsewhile not found:if current.getData() == item:found = Trueelse:previous = currentcurrent = current.getNext()if previous == None:self.head = current.getNext()else:previous.setNext(current.getNext())
Listing 7
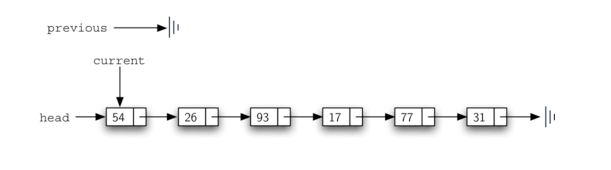
Figure 11
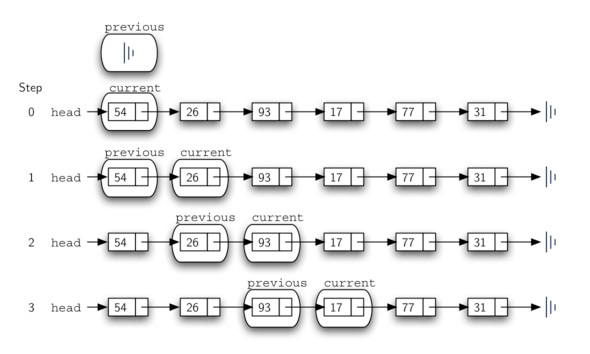
Figure 12
一旦 remove 的搜索步骤已经完成,我们需要从链表中删除该节点。 Figure 13 展示了要修改的链接。但是,有一个特殊情况需要解决。 如果要删除的项目恰好是链表中的第一个项,则 current 将引用链接列表中的第一个节点。这也意味着 previous 是 None。 我们先前说过,previous 是一个节点,它的下一个节点需要修改。在这种情况下,不是 previous ,而是链表的 head 需要改变(见 Figure 14)。

Figure 13
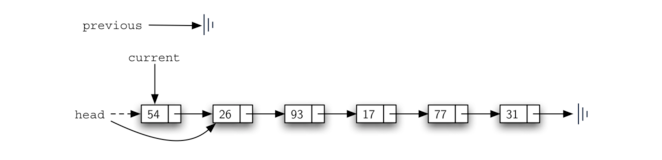
Figure 14
第 12 行检查是否处理上述的特殊情况。如果 previous 没有移动,当 found 的布尔变为 True 时,它仍是 None。 在这种情况下(行13),链表的 head 被修改以指代当前节点之后的节点,实际上是从链表中移除第一节点。 但是,如果 previous 不为 None,则要删除的节点位于链表结构的下方。 在这种情况下,previous 的引用为我们提供了下一个引用更改的节点。第 15 行使用之前的 setNext 方法完成删除。注意,在这两种情况下,引用更改的目标是 current.getNext()。 经常出现的一个问题是,这里给出的两种情况是否也将处理要移除的项在链表的最后节点中的情况。我们留给你思考。
