 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 5.11.归并排序
5.11.归并排序
我们现在将注意力转向使用分而治之策略作为提高排序算法性能的一种方法。 我们将研究的第一个算法是归并排序。归并排序是一种递归算法,不断将列表拆分为一半。 如果列表为空或有一个项,则按定义(基本情况)进行排序。如果列表有多个项,我们分割列表,并递归调用两个半部分的合并排序。 一旦对这两半排序完成,就执行称为合并的基本操作。合并是获取两个较小的排序列表并将它们组合成单个排序的新列表的过程。 Figure 10 展示了我们熟悉的示例列表,它被mergeSort 分割。 Figure 11 展示了归并后的简单排序列表。
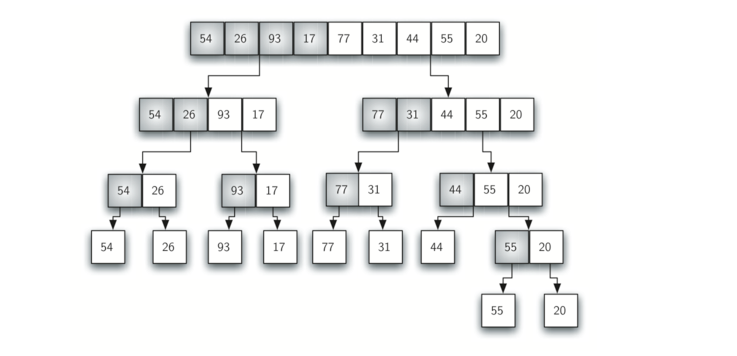
Figure 10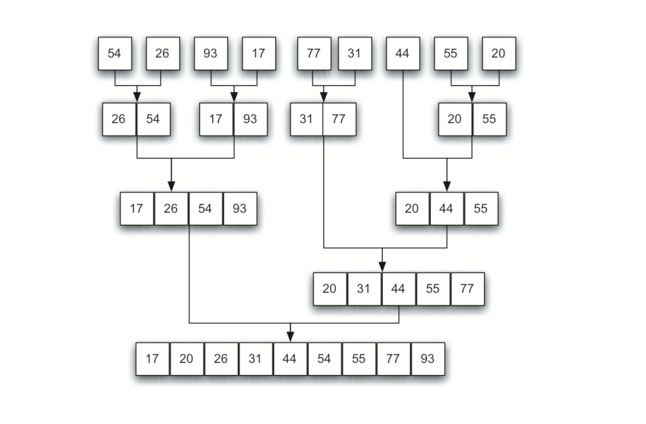
Figure 11
ActiveCode 1 中展示的 mergeSort 函数从询问基本情况开始。 如果列表的长度小于或等于1,则我们已经有有序的列表,并且不需要更多的处理。另一方面,长度大于 1,那么我们使用 Python 切片操作来提取左右两半。 重要的是要注意,列表可能没有偶数个项。这并不重要,因为长度最多相差一个。
def mergeSort(alist):print("Splitting ",alist)if len(alist)>1:mid = len(alist)//2lefthalf = alist[:mid]righthalf = alist[mid:]mergeSort(lefthalf)mergeSort(righthalf)i=0j=0k=0while i < len(lefthalf) and j < len(righthalf):if lefthalf[i] < righthalf[j]:alist[k]=lefthalf[i]i=i+1else:alist[k]=righthalf[j]j=j+1k=k+1while i < len(lefthalf):alist[k]=lefthalf[i]i=i+1k=k+1while j < len(righthalf):alist[k]=righthalf[j]j=j+1k=k+1print("Merging ",alist)alist = [54,26,93,17,77,31,44,55,20]mergeSort(alist)print(alist)
Activecode1
一旦在左半部分和右半部分(行8-9)上调用 mergeSort 函数,就假定它们已被排序。函数的其余部分(行11-31)负责将两个较小的排序列表合并成一个较大的排序列表。请注意,合并操作通过重复从排序列表中取最小的项目,将项目逐个放回原始列表(alist)。
mergeSort 函数已经增加了一个打印语句(行2),以显示在每次调用开始时排序的列表的内容。 还有一个打印语句(第32行)来显示合并过程。 脚本显示了在我们的示例列表中执行函数的结果。 请注意,44,55 和 20的列表不会均匀分配。第一个分割出 [44],第二个 [55,20]。 很容易看到分割过程最终产生可以立即与其他排序列表合并的列表。
为了分析 mergeSort 函数,我们需要考虑组成其实现的两个不同的过程。首先,列表被分成两半。我们已经计算过(在二分查找中)将列表划分为一半需要 log^n 次,其中 n 是列表的长度。第二个过程是合并。列表中的每个项将最终被处理并放置在排序的列表上。因此,大小为 n 的列表的合并操作需要 n 个操作。此分析的结果是
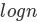 的拆分,其中每个操作花费 n,总共
的拆分,其中每个操作花费 n,总共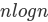 。归并排序是一种
。归并排序是一种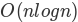 算法。
算法。
回想切片 是
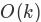 ,其中 k 是切片的大小。为了保证 mergeSort 是
,其中 k 是切片的大小。为了保证 mergeSort 是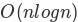 ,我们将需要删除 slice 运算符。这是可能的,如果当我们进行递归调用,我们简单地传递开始和结束索引与列表。我们把这作为一个练习。
,我们将需要删除 slice 运算符。这是可能的,如果当我们进行递归调用,我们简单地传递开始和结束索引与列表。我们把这作为一个练习。
重要的是注意,mergeSort 函数需要额外的空间来保存两个半部分,因为它们是使用切片操作提取的。如果列表很大,这个额外的空间可能是一个关键因素,并且在处理大型数据集时可能会导致此类问题。
