 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- fluid.nets
- glu
- img_conv_group
- scaled_dot_product_attention
- sequence_conv_pool
- simple_img_conv_pool
fluid.nets
SourceEnglish
glu
SourceEnglish
paddle.fluid.nets.glu(input, dim=-1)- The Gated Linear Units(GLU)由切分(split),sigmoid激活函数和按元素相乘组成。沿着给定维将input拆分成两个大小相同的部分,a和b,计算如下:
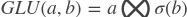
参考论文: Language Modeling with Gated Convolutional Networks
- 参数:
- input (Variable) - 输入变量,张量或者LoDTensor
- dim (int) - 拆分的维度。如果
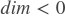 ,拆分的维为
,拆分的维为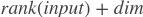 。默认为-1返回:变量 —— 变量的大小为输入的一半
。默认为-1返回:变量 —— 变量的大小为输入的一半
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name="words", shape=[-1, 6, 3, 9], dtype="float32")
- # 输出的形状为[-1, 3, 3, 9]
- output = fluid.nets.glu(input=data, dim=1)
img_conv_group
SourceEnglish
paddle.fluid.nets.imgconv_group(_input, conv_num_filter, pool_size, conv_padding=1, conv_filter_size=3, conv_act=None, param_attr=None, conv_with_batchnorm=False, conv_batchnorm_drop_rate=0.0, pool_stride=1, pool_type='max', use_cudnn=True)Image Convolution Group由Convolution2d,BatchNorm,DropOut和Pool2d组成。根据输入参数,img_conv_group将使用Convolution2d,BatchNorm,DropOut对Input进行连续计算,并将最后一个结果传递给Pool2d。
参数:
- input (Variable) - 具有[N,C,H,W]格式的输入图像。
- conv_num_filter (list | tuple) - 表示该组的过滤器数。
- pool_size (int | list | tuple) -
Pool2d Layer池的大小。如果pool_size是列表或元组,则它必须包含两个整数(pool_size_H,pool_size_W)。否则,pool_size_H = pool_size_W = pool_size。 - conv_padding (int | list | tuple) - Conv2d Layer的
padding大小。如果padding是列表或元组,则其长度必须等于conv_num_filter的长度。否则,所有Conv2d图层的conv_padding都是相同的。默认1。 - conv_filter_size (int | list | tuple) - 过滤器大小。如果filter_size是列表或元组,则其长度必须等于
conv_num_filter的长度。否则,所有Conv2d图层的conv_filter_size都是相同的。默认3。 - conv_act (str) -
Conv2d Layer的激活类型,BatchNorm后面没有。默认值:无。 - param_attr (ParamAttr) - Conv2d层的参数。默认值:无
- conv_with_batchnorm (bool | list) - 表示在
Conv2d Layer之后是否使用BatchNorm。如果conv_with_batchnorm是一个列表,则其长度必须等于conv_num_filter的长度。否则,conv_with_batchnorm指示是否所有Conv2d层都遵循BatchNorm。默认为False。 - conv_batchnorm_drop_rate (float | list) - 表示
BatchNorm之后的Dropout Layer的rop_rate。如果conv_batchnorm_drop_rate是一个列表,则其长度必须等于conv_num_filter的长度。否则,所有Dropout Layers的drop_rate都是conv_batchnorm_drop_rate。默认值为0.0。 - pool_stride (int | list | tuple) -
Pool2d层的汇集步幅。如果pool_stride是列表或元组,则它必须包含两个整数(pooling_stride_H,pooling_stride_W)。否则,pooling_stride_H = pooling_stride_W = pool_stride。默认1。 - pool_type (str) - 池化类型可以是最大池化的
max和平均池化的avg。默认max。 - use_cudnn (bool) - 是否使用cudnn内核,仅在安装cudnn库时才有效。默认值:True返回: 使用Convolution2d进行串行计算后的最终结果,BatchNorm,DropOut和Pool2d。
返回类型: 变量(Variable)。
代码示例
- import paddle.fluid as fluid
- img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
- conv_pool = fluid.nets.img_conv_group(input=img,
- conv_padding=1,
- conv_num_filter=[3, 3],
- conv_filter_size=3,
- conv_act="relu",
- pool_size=2,
- pool_stride=2)
scaled_dot_product_attention
SourceEnglish
paddle.fluid.nets.scaleddot_product_attention(_queries, keys, values, num_heads=1, dropout_rate=0.0)- 点乘attention运算。
attention运算机制可以被视为将查询和一组键值对映射到输出。 将输出计算为值的加权和,其中分配给每个值的权重由查询的兼容性函数(此处的点积)与对应的密钥计算。
可以通过(batch)矩阵乘法实现点积attention运算,如下所示:
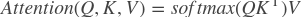
请参阅 Attention Is All You Need
- 参数:
- queries (Variable) - 输入变量,应为3-D Tensor。
- keys (Variable) - 输入变量,应为3-D Tensor。
- values (Variable) - 输入变量,应为3-D Tensor。
- num_heads (int) - 计算缩放点积attention运算的head数。默认值:1。
- dropout_rate (float) - 降低attention的dropout率。默认值:0.0。返回: 通过multi-head来缩放点积attention运算的三维张量。
返回类型: 变量(Variable)。
- 抛出异常:
ValueError- 如果输入查询键,值不是3-D Tensor会报错。
注解
当num_heads> 1时,分别学习三个线性投影,以将输入查询,键和值映射到查询’,键’和值’。 查询’,键’和值’与查询,键和值具有相同的形状。当num_heads == 1时,scaled_dot_product_attention没有可学习的参数。
代码示例
- import paddle.fluid as fluid
- queries = fluid.layers.data(name="queries",
- shape=[3, 5, 9],
- dtype="float32",
- append_batch_size=False)
- queries.stop_gradient = False
- keys = fluid.layers.data(name="keys",
- shape=[3, 6, 9],
- dtype="float32",
- append_batch_size=False)
- keys.stop_gradient = False
- values = fluid.layers.data(name="values",
- shape=[3, 6, 10],
- dtype="float32",
- append_batch_size=False)
- values.stop_gradient = False
- contexts = fluid.nets.scaled_dot_product_attention(queries, keys, values)
- contexts.shape # [3, 5, 10]
sequence_conv_pool
SourceEnglish
paddle.fluid.nets.sequenceconv_pool(_input, num_filters, filter_size, param_attr=None, act='sigmoid', pool_type='max', bias_attr=None)sequence_conv_pool由序列卷积和池化组成
参数:
- input (Variable) - sequence_conv的输入,支持变量时间长度输入序列。当前输入为shape为(T,N)的矩阵,T是mini-batch中的总时间步数,N是input_hidden_size
- num_filters (int)- 滤波器数
- filter_size (int)- 滤波器大小
- param_attr (ParamAttr) - Sequence_conv层的参数。默认:None
- act (str) - Sequence_conv层的激活函数类型。默认:sigmoid
- pool_type (str)- 池化类型。可以是max-pooling的max,average-pooling的average,sum-pooling的sum,sqrt-pooling的sqrt。默认max
- bias_attr (ParamAttr|bool|None) – sequence_conv偏置的参数属性。如果设置为False,则不会向输出单元添加偏置。如果将参数设置为ParamAttr的None或one属性,sequence_conv将创建ParamAttr作为bias_attr。如果未设置bias_attr的初始化器,则初始化偏差为零。默认值:None。返回:序列卷积(Sequence Convolution)和池化(Pooling)的结果
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- input_dim = 100 #len(word_dict)
- emb_dim = 128
- hid_dim = 512
- data = fluid.layers.data( name="words", shape=[1], dtype="int64", lod_level=1)
- emb = fluid.layers.embedding(input=data, size=[input_dim, emb_dim], is_sparse=True)
- seq_conv = fluid.nets.sequence_conv_pool(input=emb,
- num_filters=hid_dim,
- filter_size=3,
- act="tanh",
- pool_type="sqrt")
simple_img_conv_pool
SourceEnglish
paddle.fluid.nets.simpleimg_conv_pool(_input, num_filters, filter_size, pool_size, pool_stride, pool_padding=0, pool_type='max', global_pooling=False, conv_stride=1, conv_padding=0, conv_dilation=1, conv_groups=1, param_attr=None, bias_attr=None, act=None, use_cudnn=True)simple_img_conv_pool由一个Convolution2d和一个Pool2d组成。参数:
- input (Variable) - 输入图像的格式为[N,C,H,W]。
- num_filters (int) -
filter的数量。它与输出的通道相同。 - filter_size (int | list | tuple) - 过滤器大小。如果
filter_size是列表或元组,则它必须包含两个整数(filter_size_H,filter_size_W)。否则,filter_size_H = filter_size_W = filter_size。 - pool_size (int | list | tuple) - Pool2d池化层大小。如果pool_size是列表或元组,则它必须包含两个整数(pool_size_H,pool_size_W)。否则,pool_size_H = pool_size_W = pool_size。
- pool_stride (int | list | tuple) - Pool2d池化层步长。如果pool_stride是列表或元组,则它必须包含两个整数(pooling_stride_H,pooling_stride_W)。否则,pooling_stride_H = pooling_stride_W = pool_stride。
- pool_padding (int | list | tuple) - Pool2d池化层的padding。如果pool_padding是列表或元组,则它必须包含两个整数(pool_padding_H,pool_padding_W)。否则,pool_padding_H = pool_padding_W = pool_padding。默认值为0。
- pool_type (str) - 池化类型可以是
max-pooling的max和平均池的avg。默认max。 - global_pooling (bool)- 是否使用全局池。如果global_pooling = true,则忽略pool_size和pool_padding。默认为False
- conv_stride (int | list | tuple) - conv2d Layer的步长。如果stride是列表或元组,则它必须包含两个整数,(conv_stride_H,conv_stride_W)。否则,conv_stride_H = conv_stride_W = conv_stride。默认值:conv_stride = 1。
- conv_padding (int | list | tuple) - conv2d Layer的padding大小。如果padding是列表或元组,则它必须包含两个整数(conv_padding_H,conv_padding_W)。否则,conv_padding_H = conv_padding_W = conv_padding。默认值:conv_padding = 0。
- conv_dilation (int | list | tuple) - conv2d Layer的dilation大小。如果dilation是列表或元组,则它必须包含两个整数(conv_dilation_H,conv_dilation_W)。否则,conv_dilation_H = conv_dilation_W = conv_dilation。默认值:conv_dilation = 1。
- conv_groups (int) - conv2d Layer的组数。根据Alex Krizhevsky的Deep CNN论文中的分组卷积:当group = 2时,前半部分滤波器仅连接到输入通道的前半部分,而后半部分滤波器仅连接到后半部分输入通道。默认值:groups = 1。
- param_attr (ParamAttr | None) - 可学习参数的参数属性或conv2d权重。如果将其设置为None或ParamAttr的一个属性,则conv2d将创建ParamAttr作为param_attr。如果未设置param_attr的初始化,则使用
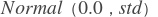 初始化参数,并且
初始化参数,并且 std为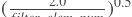 。默认值:None
。默认值:None - bias_attr (ParamAttr | bool | None) - conv2d的bias参数属性。如果设置为False,则不会向输出单元添加bias。如果将其设置为None或ParamAttr的一个属性,则conv2d将创建ParamAttr作为bias_attr。如果未设置bias_attr的初始化程序,则将偏差初始化为零。默认值:None
- act (str) - conv2d的激活类型,如果设置为None,则不附加激活。默认值:无。
- use_cudnn (bool) - 是否使用cudnn内核,仅在安装cudnn库时才有效。默认值:True。返回: Convolution2d和Pool2d之后输入的结果。
返回类型: 变量(Variable)
示例代码
- import paddle.fluid as fluid
- img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
- conv_pool = fluid.nets.simple_img_conv_pool(input=img,
- filter_size=5,
- num_filters=20,
- pool_size=2,
- pool_stride=2,
- act="relu")
