 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- nn
- adaptive_pool2d
- adaptive_pool3d
- add_position_encoding
- affine_channel
- affine_grid
- autoincreased_step_counter
- batch_norm
- beam_search
- beam_search_decode
- bilinear_tensor_product
- bpr_loss
- brelu
- chunk_eval
- clip
- clip_by_norm
- continuous_value_model
- conv2d
- conv2d_transpose
- conv3d
- conv3d_transpose
- cos_sim
- crf_decoding
- crop
- cross_entropy
- ctc_greedy_decoder
- data_norm
- deformable_conv
- deformable_roi_pooling
- dice_loss
- dropout
- dynamic_gru
- dynamic_lstm
- dynamic_lstmp
- edit_distance
- elementwise_add
- elementwise_div
- elementwise_floordiv
- elementwise_max
- elementwise_min
- elementwise_mod
- elementwise_mul
- elementwise_pow
- elementwise_sub
- elu
- embedding
- expand
- fc
- flatten
- fsp_matrix
- gather
- gaussian_random
- gaussian_random_batch_size_like
- get_tensor_from_selected_rows
- grid_sampler
- group_norm
- gru_unit
- hard_sigmoid
- hash
- hsigmoid
- huber_loss
- im2sequence
- image_resize
- image_resize_short
- kldiv_loss
- l2_normalize
- label_smooth
- layer_norm
- leaky_relu
- linear_chain_crf
- lod_reset
- log
- log_loss
- logical_and
- logical_not
- logical_or
- logical_xor
- lrn
- lstm
- lstm_unit
- margin_rank_loss
- matmul
- maxout
- mean
- mean_iou
- merge_selected_rows
- mul
- multiplex
- nce
- npair_loss
- one_hot
- pad
- pad2d
- pad_constant_like
- pixel_shuffle
- pool2d
- pool3d
- pow
- prelu
- psroi_pool
- py_func
- random_crop
- rank
- rank_loss
- reduce_all
- reduce_any
- reduce_max
- reduce_mean
- reduce_min
- reduce_prod
- reduce_sum
- relu
- relu6
- reshape
- resize_bilinear
- resize_nearest
- roi_align
- roi_pool
- row_conv
- sampled_softmax_with_cross_entropy
- sampling_id
- scale
- scatter
- selu
- sequence_concat
- sequence_conv
- sequence_enumerate
- sequence_expand
- sequence_expand_as
- sequence_first_step
- sequence_last_step
- sequence_mask
- sequence_pad
- sequence_pool
- sequence_reshape
- sequence_reverse
- sequence_scatter
- sequence_slice
- sequence_softmax
- sequence_unpad
- shape
- shuffle_channel
- sigmoid_cross_entropy_with_logits
- sign
- similarity_focus
- slice
- smooth_l1
- soft_relu
- softmax
- softmax_with_cross_entropy
- space_to_depth
- spectral_norm
- split
- square_error_cost
- squeeze
- stack
- stanh
- sum
- swish
- teacher_student_sigmoid_loss
- temporal_shift
- topk
- transpose
- tree_conv
- uniform_random_batch_size_like
- unsqueeze
- unstack
- warpctc
- where
nn
adaptive_pool2d
paddle.fluid.layers.adaptivepool2d(_input, pool_size, pool_type='max', require_index=False, name=None)- pooling2d操作根据输入
input,pool_size,pool_type参数计算输出。 输入(X)和输出(Out)采用NCHW格式,其中N是批大小batch size,C是通道数,H是feature(特征)的高度,W是feature(特征)的宽度。 参数pool_size由两个元素构成, 这两个元素分别代表高度和宽度。 输出(Out)的H和W维与pool_size大小相同。
对于平均adaptive pool2d:
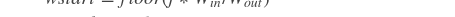
- 参数:
- input (Variable) - 池化操作的输入张量。 输入张量的格式为NCHW,其中N是batch大小,C是通道数,H是特征的高度,W是特征的宽度。
- pool_size (int | list | tuple) - 池化核大小。 如果池化核大小是元组或列表,则它必须包含两个整数(pool_size_Height,pool_size_Width)。
- pool_type (string)- 池化类型,可输入“max”代表max-pooling,或者“avg”代表average-pooling。
- require_index (bool) - 如果为true,则输出中带有最大池化点所在的索引。 如果pool_type为avg,该项不可被设置为true。
- name (str | None) - 此层的名称(可选)。 如果设置为None,则将自动命名该层。返回: 池化结果
返回类型: Variable
抛出异常:
ValueError–pool_type不是 ‘max’ 或 ‘avg’ValueError– 当pool_type是 ‘avg’ 时,错误地设置 ‘require_index’ 为true .ValueError–pool_size应为一个长度为2的列表或元组
- # 假设输入形为[N, C, H, W], `pool_size` 为 [m, n],
- # 输出形为 [N, C, m, n], adaptive pool 将输入的 H 和 W 维度
- # 平均分割为 m * n 个栅格(grid) ,然后为每个栅格进行池化得到输出
- # adaptive average pool 进行如下操作
- #
- # for i in range(m):
- # for j in range(n):
- # hstart = floor(i * H / m)
- # hend = ceil((i + 1) * H / m)
- # wstart = floor(i * W / n)
- # wend = ceil((i + 1) * W / n)
- # output[:, :, i, j] = avg(input[:, :, hstart: hend, wstart: wend])
- #
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name='data', shape=[3, 32, 32], dtype='float32')
- pool_out = fluid.layers.adaptive_pool2d(
- input=data,
- pool_size=[3, 3],
- pool_type='avg')
adaptive_pool3d
paddle.fluid.layers.adaptivepool3d(_input, pool_size, pool_type='max', require_index=False, name=None)- pooling3d操作根据输入
input,pool_size,pool_type参数计算输出。 输入(X)和输出(输出)采用NCDHW格式,其中N是批大小batch size,C是通道数,D是特征(feature)的深度,H是特征的高度,W是特征的宽度。 参数pool_size由三个元素组成。 这三个元素分别代表深度,高度和宽度。输出(Out)的D,H,W维与pool_size相同。
对于平均adaptive pool3d:
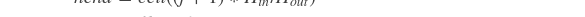
- 参数:
- input (Variable) - 池化操作的输入张量。 输入张量的格式为NCDHW,其中N是batch大小,C是通道数,D为特征的深度,H是特征的高度,W是特征的宽度。
- pool_size (int | list | tuple) - 池化核大小。 如果池化核大小是元组或列表,则它必须包含三个整数(Depth, Height, Width)。
- pool_type (string)- 池化类型,可输入“max”代表max-pooling,或者“avg”代表average-pooling。
- require_index (bool) - 如果为true,则输出中带有最大池化点所在的索引。 如果pool_type为avg,该项不可被设置为true。
- name (str | None) - 此层的名称(可选)。 如果设置为None,则将自动命名该层。返回: 池化结果
返回类型: Variable
抛出异常:
ValueError–pool_type不是 ‘max’ 或 ‘avg’ValueError– 当pool_type是 ‘avg’ 时,错误地设置 ‘require_index’ 为true .ValueError–pool_size应为一个长度为3的列表或元组
- # 假设输入形为[N, C, D, H, W], `pool_size` 为 [l, m, n],
- # 输出形为 [N, C, l, m, n], adaptive pool 将输入的D, H 和 W 维度
- # 平均分割为 l * m * n 个栅格(grid) ,然后为每个栅格进行池化得到输出
- # adaptive average pool 进行如下操作
- #
- # for i in range(l):
- # for j in range(m):
- # for k in range(n):
- # dstart = floor(i * D / l)
- # dend = ceil((i + 1) * D / l)
- # hstart = floor(j * H / m)
- # hend = ceil((j + 1) * H / m)
- # wstart = floor(k * W / n)
- # wend = ceil((k + 1) * W / n)
- # output[:, :, i, j, k] =
- # avg(input[:, :, dstart:dend, hstart: hend, wstart: wend])
- #
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name='data', shape=[3, 32, 32, 32], dtype='float32')
- pool_out, mask = fluid.layers.adaptive_pool3d(
- input=data,
- pool_size=[3, 3, 3],
- pool_type='avg')
add_position_encoding
paddle.fluid.layers.addposition_encoding(_input, alpha, beta, name=None)- 添加位置编码层
接受形状为[N×M×P]的三维输入张量,并返回一个形为[N×M×P]的输出张量,且输出张量具有位置编码值。
可参考论文: Attention Is All You Need
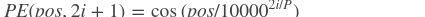
- 其中:
- PE(pos, 2i): 偶数位置上数字的增量
- PE(pos, 2i + 1): 奇数位置上数字的增量
- 参数:
- input (Variable) – 形状为[N x M x P]的三维输入张量
- alpha (float) – 输入张量的倍数
- beta (float) – 位置编码张量Positional Encoding Tensor的倍数
- name (string) – 位置编码层的名称返回: 具有位置编码的三维形状张量[N×M×P]
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- tensor = fluid.layers.data(
- name='tensor',
- shape=[32, 64, 512],
- dtype='float32',
- append_batch_size=False)
- position_tensor = fluid.layers.add_position_encoding(
- input=tensor, alpha=1.0, beta=1.0)
affine_channel
paddle.fluid.layers.affinechannel(_x, scale=None, bias=None, data_layout='NCHW', name=None, act=None)- 对输入的每个 channel 应用单独的仿射变换。用于将空间批处理范数替换为其等价的固定变换。
输入也可以是二维张量,并在二维应用仿射变换。
- 参数:
- x (Variable):特征图输入可以是一个具有NCHW阶或NHWC阶的4D张量。它也可以是二维张量和应用于第二维度的仿射变换。
- scale (Variable): 形状为(C)的一维输入,第C个元素为输入的第C通道仿射变换的尺度因子。
- bias (Variable):形状为(C)的一维输入,第C个元素是输入的第C个通道的仿射变换的偏置。
- data_layout (string, default NCHW): NCHW 或 NHWC,如果输入是一个2D张量,可以忽略该参数
- name (str, default None): 此层的名称
- act (str, default None): 应用于该层输出的激活函数返回: out (Variable): 与x具有相同形状和数据布局的张量。
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32],
- dtype='float32')
- input_scale = fluid.layers.create_parameter(shape=[3],
- dtype="float32")
- input_bias = fluid.layers.create_parameter(shape=[3],
- dtype="float32")
- out = fluid.layers.affine_channel(data,scale=input_scale,
- bias=input_bias)
affine_grid
paddle.fluid.layers.affinegrid(_theta, out_shape, name=None)- 它使用仿射变换的参数生成(x,y)坐标的网格,这些参数对应于一组点,在这些点上,输入特征映射应该被采样以生成转换后的输出特征映射。
- * 例 1:
- 给定:
- theta = [[[x_11, x_12, x_13]
- [x_14, x_15, x_16]]
- [[x_21, x_22, x_23]
- [x_24, x_25, x_26]]]
- out_shape = [2, 3, 5, 5]
- Step 1:
- 根据out_shape生成标准化坐标
- 归一化坐标的值在-1和1之间
- 归一化坐标的形状为[2,H, W],如下所示:
- C = [[[-1. -1. -1. -1. -1. ]
- [-0.5 -0.5 -0.5 -0.5 -0.5]
- [ 0. 0. 0. 0. 0. ]
- [ 0.5 0.5 0.5 0.5 0.5]
- [ 1. 1. 1. 1. 1. ]]
- [[-1. -0.5 0. 0.5 1. ]
- [-1. -0.5 0. 0.5 1. ]
- [-1. -0.5 0. 0.5 1. ]
- [-1. -0.5 0. 0.5 1. ]
- [-1. -0.5 0. 0.5 1. ]]]
- C[0]是高轴坐标,C[1]是宽轴坐标。
- Step2:
- 将C转换并重组成形为[H * W, 2]的张量,并追加到最后一个维度
- 我们得到:
- C_ = [[-1. -1. 1. ]
- [-0.5 -1. 1. ]
- [ 0. -1. 1. ]
- [ 0.5 -1. 1. ]
- [ 1. -1. 1. ]
- [-1. -0.5 1. ]
- [-0.5 -0.5 1. ]
- [ 0. -0.5 1. ]
- [ 0.5 -0.5 1. ]
- [ 1. -0.5 1. ]
- [-1. 0. 1. ]
- [-0.5 0. 1. ]
- [ 0. 0. 1. ]
- [ 0.5 0. 1. ]
- [ 1. 0. 1. ]
- [-1. 0.5 1. ]
- [-0.5 0.5 1. ]
- [ 0. 0.5 1. ]
- [ 0.5 0.5 1. ]
- [ 1. 0.5 1. ]
- [-1. 1. 1. ]
- [-0.5 1. 1. ]
- [ 0. 1. 1. ]
- [ 0.5 1. 1. ]
- [ 1. 1. 1. ]]
- Step3:
- 按下列公式计算输出
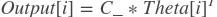
- 参数:
- theta (Variable): 一类具有形状为[N, 2, 3]的仿射变换参数
- out_shape (Variable | list | tuple):具有格式[N, C, H, W]的目标输出的shape,out_shape可以是变量、列表或元组。
- name (str|None): 此层的名称(可选)。如果没有设置,将自动命名。返回: Variable: 形为[N, H, W, 2]的输出。
抛出异常: ValueError: 如果输入了不支持的参数类型
代码示例:
- import paddle.fluid as fluid
- theta = fluid.layers.data(name="x", shape=[2, 3], dtype="float32")
- out_shape = fluid.layers.data(name="y", shape=[-1], dtype="float32")
- data = fluid.layers.affine_grid(theta, out_shape)
- # or
- data = fluid.layers.affine_grid(theta, [5, 3, 28, 28])
autoincreased_step_counter
paddle.fluid.layers.autoincreasedstep_counter(_counter_name=None, begin=1, step=1)创建一个自增变量,每个mini-batch返回主函数运行次数,变量自动加1,默认初始值为1.
参数:
- counter_name (str)-计数名称,默认为
@STEP_COUNTER@ - begin (int)-开始计数
- step (int)-执行之间增加的步数返回:全局运行步数
- counter_name (str)-计数名称,默认为
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- global_step = fluid.layers.autoincreased_step_counter(
- counter_name='@LR_DECAY_COUNTER@', begin=0, step=1)
batch_norm
paddle.fluid.layers.batchnorm(_input, act=None, is_test=False, momentum=0.9, epsilon=1e-05, param_attr=None, bias_attr=None, data_layout='NCHW', in_place=False, name=None, moving_mean_name=None, moving_variance_name=None, do_model_average_for_mean_and_var=False, fuse_with_relu=False, use_global_stats=False)- 批正则化层(Batch Normalization Layer)
可用作conv2d和全链接操作的正则化函数。该层需要的数据格式如下:
1.NHWC[batch,in_height,in_width,in_channels]2.NCHW[batch,in_channels,in_height,in_width]
更多详情请参考 : Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
input 是mini-batch的输入特征。

当use_global_stats = True时,
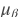 和
和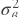 不是一个minibatch的统计数据。 它们是全局(或运行)统计数据。 (它通常来自预先训练好的模型。)训练和测试(或预测)具有相同的行为:
不是一个minibatch的统计数据。 它们是全局(或运行)统计数据。 (它通常来自预先训练好的模型。)训练和测试(或预测)具有相同的行为:
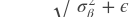
- 参数:
- input (Variable) - 输入变量的排序,可以为 2, 3, 4, 5
- act (string,默认None)- 激活函数类型,linear|relu|prelu|…
- is_test (bool,默认False) - 指示它是否在测试阶段。
- momentum (float,默认0.9)- 此值用于计算 moving_mean 和 moving_var。更新公式为:
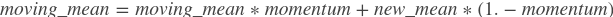 ,
,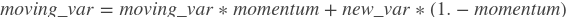 , 默认值0.9.
, 默认值0.9. - epsilon (float,默认1e-05)- 加在分母上为了数值稳定的值。默认值为1e-5。
- param_attr (ParamAttr|None) - batch_norm参数范围的属性,如果设为None或者是ParamAttr的一个属性,batch_norm创建ParamAttr为param_attr。如果没有设置param_attr的初始化函数,参数初始化为Xavier。默认:None
- bias_attr (ParamAttr|None) - batch_norm bias参数的属性,如果设为None或者是ParamAttr的一个属性,batch_norm创建ParamAttr为bias_attr。如果没有设置bias_attr的初始化函数,参数初始化为0。默认:None
- data_layout (string,默认NCHW) - NCHW|NHWC
- in_place (bool,默认False)- 得出batch norm可复用记忆的输入和输出
- name (string,默认None)- 该层名称(可选)。若设为None,则自动为该层命名
- moving_mean_name (string,默认None)- moving_mean的名称,存储全局Mean。如果将其设置为None,
batch_norm将随机命名全局平均值;否则,batch_norm将命名全局平均值为moving_mean_name - moving_variance_name (string,默认None)- moving_variance的名称,存储全局变量。如果将其设置为None,
batch_norm将随机命名全局方差;否则,batch_norm将命名全局方差为moving_variance_name - do_model_average_for_mean_and_var (bool,默认False)- 是否为mean和variance做模型均值
- fuse_with_relu (bool)- 如果为True,batch norm后该操作符执行relu
- use_global_stats (bool, Default False) – 是否使用全局均值和方差。 在预测或测试模式下,将use_global_stats设置为true或将is_test设置为true,并且行为是等效的。 在训练模式中,当设置use_global_stats为True时,在训练期间也使用全局均值和方差。返回: 张量,在输入中运用批正则后的结果
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[3, 7, 3, 7], dtype='float32', append_batch_size=False)
- hidden1 = fluid.layers.fc(input=x, size=200, param_attr='fc1.w')
- hidden2 = fluid.layers.batch_norm(input=hidden1)
beam_search
paddle.fluid.layers.beamsearch(_pre_ids, pre_scores, ids, scores, beam_size, end_id, level=0, is_accumulated=True, name=None, return_parent_idx=False)- 在机器翻译任务中,束搜索(Beam search)是选择候选词的一种经典算法
更多细节参考 Beam Search
该层在一时间步中按束进行搜索。具体而言,根据候选词使用于源句子所得的 scores , 从候选词 ids 中选择当前步骤的 top-K (最佳K)候选词的id,其中 K 是 beam_size , ids , scores 是计算单元的预测结果。如果没有提供 ids ,则将会根据 scores 计算得出。 另外, pre_id 和 pre_scores 是上一步中 beam_search 的输出,用于特殊处理翻译的结束边界。
注意,如果 is_accumulated 为 True,传入的 scores 应该是累积分数。反之,scores 会被认为为直接得分(straightforward scores), 并且会被转化为log值并且在此运算中会被累积到 pre_scores 中。在计算累积分数之前应该使用额外的 operators 进行长度惩罚。
有关束搜索用法演示,请参阅以下示例:
fluid/tests/book/test_machine_translation.py
- 参数:
pre_ids (Variable) - LodTensor变量,它是上一步
beam_search的输出。在第一步中。它应该是LodTensor,shape为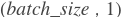 ,
,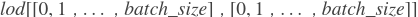
pre_scores (Variable) - LodTensor变量,它是上一步中beam_search的输出
- ids (Variable) - 包含候选ID的LodTensor变量。shape为
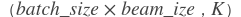 ,其中
,其中 K应该是beam_size - scores (Variable) - 与
ids及其shape对应的累积分数的LodTensor变量, 与ids的shape相同。 - beam_size (int) - 束搜索中的束宽度。
- end_id (int) - 结束标记的id。
- level (int,default 0) - 可忽略,当前不能更改 。它表示lod的源级别,解释如下。
ids的 lod 级别应为2.第一级是源级别, 描述每个源句子(beam)的前缀(分支)的数量,第二级是描述这些候选者属于前缀的句子级别的方式。链接前缀和所选候选者的路径信息保存在lod中。 - is_accumulated (bool,默认为True) - 输入分数是否为累计分数。
- name (str | None) - 该层的名称(可选)。如果设置为None,则自动命名该层。
- return_parent_idx (bool) - 是否返回一个额外的Tensor变量,在输出的pre_ids中保留selected_ids的双亲indice,可用于在下一个时间步收集单元状态。返回:LodTensor元组。包含所选的id和与其相应的分数。 如果return_parent_idx为True,则包含一个保留selected_ids的双亲indice的额外Tensor变量。
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- # 假设 `probs` 包含计算神经元所得的预测结果
- # `pre_ids` 和 `pre_scores` 为beam_search之前时间步的输出
- beam_size = 4
- end_id = 1
- pre_ids = fluid.layers.data(
- name='pre_id', shape=[1], lod_level=2, dtype='int64')
- pre_scores = fluid.layers.data(
- name='pre_scores', shape=[1], lod_level=2, dtype='float32')
- probs = fluid.layers.data(
- name='probs', shape=[10000], dtype='float32')
- topk_scores, topk_indices = fluid.layers.topk(probs, k=beam_size)
- accu_scores = fluid.layers.elementwise_add(
- x=fluid.layers.log(x=topk_scores)),
- y=fluid.layers.reshape(
- pre_scores, shape=[-1]),
- axis=0)
- selected_ids, selected_scores = fluid.layers.beam_search(
- pre_ids=pre_ids,
- pre_scores=pre_scores,
- ids=topk_indices,
- scores=accu_scores,
- beam_size=beam_size,
- end_id=end_id)
beam_search_decode
paddle.fluid.layers.beamsearch_decode(_ids, scores, beam_size, end_id, name=None)- 束搜索层(Beam Search Decode Layer)通过回溯LoDTensorArray ids,为每个源语句构建完整假设,LoDTensorArray
ids的lod可用于恢复束搜索树中的路径。请参阅下面的demo中的束搜索使用示例:
- fluid/tests/book/test_machine_translation.py
- 参数:
- id (Variable) - LodTensorArray,包含所有回溯步骤重中所需的ids。
- score (Variable) - LodTensorArra,包含所有回溯步骤对应的score。
- beam_size (int) - 束搜索中波束的宽度。
- end_id (int) - 结束token的id。
- name (str|None) - 该层的名称(可选)。如果设置为None,该层将被自动命名。返回: LodTensor 对(pair), 由生成的id序列和相应的score序列组成。两个LodTensor的shape和lod是相同的。lod的level=2,这两个level分别表示每个源句有多少个假设,每个假设有多少个id。
返回类型: 变量(variable)
代码示例
- import paddle.fluid as fluid
- # 假设 `ids` 和 `scores` 为 LodTensorArray变量,它们保留了
- # 选择出的所有时间步的id和score
- ids = fluid.layers.create_array(dtype='int64')
- scores = fluid.layers.create_array(dtype='float32')
- finished_ids, finished_scores = fluid.layers.beam_search_decode(
- ids, scores, beam_size=5, end_id=0)
bilinear_tensor_product
paddle.fluid.layers.bilineartensor_product(_x, y, size, act=None, name=None, param_attr=None, bias_attr=None)- 该层对两个输入执行双线性张量积。
例如:
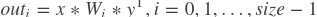
- 在这个公式中:
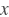 : 第一个输入,包含M个元素,形状为[batch_size, M]
: 第一个输入,包含M个元素,形状为[batch_size, M]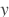 : 第二个输入,包含N个元素,形状为[batch_size, N]
: 第二个输入,包含N个元素,形状为[batch_size, N]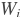 : 第i个被学习的权重,形状是[M, N]
: 第i个被学习的权重,形状是[M, N]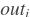 : out的第i个元素,形状是[batch_size, size]
: out的第i个元素,形状是[batch_size, size]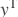 :
: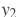 的转置
的转置
- 参数:
- x (Variable): 2-D 输入张量,形状为 [batch_size, M]
- y (Variable): 2-D 输入张量,形状为 [batch_size, N]
- size (int): 此层的维度,
- act (str, default None): 应用到该层输出的激活函数
- name (str, default None): 该层的名称
- param_attr (ParamAttr, default None): 可学习参数/权重(w) 的参数属性
- bias_attr (ParamAttr, default None): 偏差的参数属性,如果设置为False,则不会向输出单元添加偏差。如果设置为零,偏差初始化为零。默认值:None返回: Variable: 一个形为[batch_size, size]的2-D张量
代码示例:
- import paddle.fluid as fluid
- layer1 = fluid.layers.data("t1", shape=[-1, 5], dtype="float32")
- layer2 = fluid.layers.data("t2", shape=[-1, 4], dtype="float32")
- tensor = fluid.layers.bilinear_tensor_product(x=layer1, y=layer2, size=1000)
bpr_loss
paddle.fluid.layers.bprloss(_input, label, name=None)- 贝叶斯个性化排序损失计算(Bayesian Personalized Ranking Loss Operator )
该算子属于pairwise的排序类型,其标签是期望物品。在某次会话中某一给定点的损失值由下式计算而得:
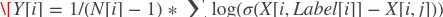
]
更多细节请参考 Session Based Recommendations with Recurrent Neural Networks_
- 参数:
- input (Variable|list) - 一个形为[N x D]的2-D tensor , 其中 N 为批大小batch size ,D 为种类的数量。该输入为logits而非概率。
- label (Variable|list) - 2-D tensor
类型的真实值, 形为[N x 1] - name (str|None) - (可选)该层的命名。 如果为None, 则自动为该层命名。 默认为None.返回: 形为[N x 1]的2D张量,即bpr损失
代码示例:
- import paddle.fluid as fluid
- neg_size = 10
- label = fluid.layers.data(
- name="label", shape=[1], dtype="int64")
- predict = fluid.layers.data(
- name="predict", shape=[neg_size + 1], dtype="float32")
- cost = fluid.layers.bpr_loss(input=predict, label=label)
brelu
paddle.fluid.layers.brelu(x, t_min=0.0, t_max=24.0, name=None)- BRelu 激活函数
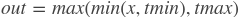
- 参数:
- x (Variable) - BReluoperator的输入
- t_min (FLOAT|0.0) - BRelu的最小值
- t_max (FLOAT|24.0) - BRelu的最大值
- name (str|None) - 该层的名称(可选)。如果设置为None,该层将被自动命名代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[2,3,16,16], dtype=”float32”)
- y = fluid.layers.brelu(x, t_min=1.0, t_max=20.0)
chunk_eval
paddle.fluid.layers.chunkeval(_input, label, chunk_scheme, num_chunk_types, excluded_chunk_types=None)- 块估计(Chunk Evaluator)
该功能计算并输出块检测(chunk detection)的准确率、召回率和F1值。
chunking的一些基础请参考 Chunking with Support Vector Machines
ChunkEvalOp计算块检测(chunk detection)的准确率、召回率和F1值,并支持IOB,IOE,IOBES和IO标注方案。以下是这些标注方案的命名实体(NER)标注例子:
- ====== ====== ====== ===== == ============ ===== ===== ===== == =========
- Li Ming works at Agricultural Bank of China in Beijing.
- ====== ====== ====== ===== == ============ ===== ===== ===== == =========
- IO I-PER I-PER O O I-ORG I-ORG I-ORG I-ORG O I-LOC
- IOB B-PER I-PER O O B-ORG I-ORG I-ORG I-ORG O B-LOC
- IOE I-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O E-LOC
- IOBES B-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O S-LOC
- ====== ====== ====== ===== == ============ ===== ===== ===== == =========
有三种块类别(命名实体类型),包括PER(人名),ORG(机构名)和LOC(地名),标签形式为标注类型(tag type)-块类型(chunk type)。
由于计算实际上用的是标签id而不是标签,需要额外注意将标签映射到相应的id,这样CheckEvalOp才可运行。关键在于id必须在列出的等式中有效。
- tag_type = label % num_tag_type
- chunk_type = label / num_tag_type
num_tag_type是标注规则中的标签类型数,num_chunk_type是块类型数,tag_type从下面的表格中获取值。
- Scheme Begin Inside End Single
- plain 0 - - -
- IOB 0 1 - -
- IOE - 0 1 -
- IOBES 0 1 2 3
仍以NER为例,假设标注规则是IOB块类型为ORG,PER和LOC。为了满足以上等式,标签图如下:
- B-ORG 0
- I-ORG 1
- B-PER 2
- I-PER 3
- B-LOC 4
- I-LOC 5
- O 6
不难证明等式的块类型数为3,IOB规则中的标签类型数为2.例如I-LOC的标签id为5,I-LOC的标签类型id为1,I-LOC的块类型id为2,与等式的结果一致。
- 参数:
- input (Variable) - 网络的输出预测
- label (Variable) - 测试数据集的标签
- chunk_scheme (str) - 标注规则,表示如何解码块。必须数IOB,IOE,IOBES或者plain。详情见描述
- num_chunk_types (int) - 块类型数。详情见描述
- excluded_chunk_types (list) - 列表包含块类型id,表示不在计数内的块类型。详情见描述返回:元组(tuple),包含precision, recall, f1_score, num_infer_chunks, num_label_chunks, num_correct_chunks
返回类型:tuple(元组)
代码示例:
- import paddle.fluid as fluid
- dict_size = 10000
- label_dict_len = 7
- sequence = fluid.layers.data(
- name='id', shape=[1], lod_level=1, dtype='int64')
- embedding = fluid.layers.embedding(
- input=sequence, size=[dict_size, 512])
- hidden = fluid.layers.fc(input=embedding, size=512)
- label = fluid.layers.data(
- name='label', shape=[1], lod_level=1, dtype='int32')
- crf = fluid.layers.linear_chain_crf(
- input=hidden, label=label, param_attr=fluid.ParamAttr(name="crfw"))
- crf_decode = fluid.layers.crf_decoding(
- input=hidden, param_attr=fluid.ParamAttr(name="crfw"))
- fluid.layers.chunk_eval(
- input=crf_decode,
- label=label,
- chunk_scheme="IOB",
- num_chunk_types=(label_dict_len - 1) / 2)
clip
paddle.fluid.layers.clip(x, min, max, name=None)- clip算子
clip算子限制给定输入的值在一个区间内。间隔使用参数”min”和”max”来指定:公式为
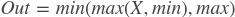
- 参数:
- x (Variable)- (Tensor)clip运算的输入,维数必须在[1,9]之间。
- min (FLOAT)- (float)最小值,小于该值的元素由min代替。
- max (FLOAT)- (float)最大值,大于该值的元素由max替换。
- name (basestring | None)- 输出的名称。返回: (Tensor)clip操作后的输出和输入(X)具有形状(shape)
返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name='data', shape=[1], dtype='float32')
- reward = fluid.layers.clip(x=input, min=-1.0, max=1.0)
clip_by_norm
paddle.fluid.layers.clipby_norm(_x, max_norm, name=None)- ClipByNorm算子
此算子将输入 X 的L2范数限制在 max_norm 内。如果 X 的L2范数小于或等于 max_norm ,则输出(Out)将与 X 相同。如果X的L2范数大于 max_norm ,则 X 将被线性缩放,使得输出(Out)的L2范数等于 max_norm ,如下面的公式所示:
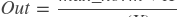
其中,
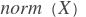 代表
代表 x 的L2范数。
- 参数:
- x (Variable)- (Tensor) clip_by_norm运算的输入,维数必须在[1,9]之间。
- max_norm (float)- 最大范数值。
- name (basestring | None)- 输出的名称。返回: (Tensor)clip_by_norm操作后的输出和输入(X)具有形状(shape).
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name='data', shape=[1], dtype='float32')
- reward = fluid.layers.clip_by_norm(x=input, max_norm=1.0)
continuous_value_model
paddle.fluid.layers.continuousvalue_model(_input, cvm, use_cvm=True)- continuous_value_model层
现在,continuous value model(cvm)仅考虑CTR项目中的展示和点击值。我们假设输入是一个含cvm_feature的词向量,其形状为[N D](D为2 + 嵌入维度)。如果use_cvm=True,它会计算log(cvm_feature),且输出的形状为[N D]。如果use_cvm=False,它会从输入中移除cvm_feature,且输出的形状为[N * (D - 2)]。
该层接受一个名为input的张量,嵌入后成为ID层(lod level为1), cvm为一个show_click info。
- 参数:
- input (Variable)-一个N x D的二维LodTensor, N为batch size, D为2 + 嵌入维度, lod level = 1。
- cvm (Variable)-一个N x 2的二维Tensor, N为batch size,2为展示和点击值。
- use_cvm (bool)-分使用/不使用cvm两种情况。如果使用cvm,输出维度和输入相等;如果不使用cvm,输出维度为输入-2(移除展示和点击值)。(cvm op是一个自定义的op,其输入是一个含embed_with_cvm默认值的序列,因此我们需要一个名为cvm的op来决定是否使用cvm。)返回:变量,一个N x D的二维LodTensor,如果使用cvm,D等于输入的维度,否则D等于输入的维度-2。
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[-1, 1], lod_level=1, append_batch_size=False, dtype="int64")#, stop_gradient=False)
- label = fluid.layers.data(name="label", shape=[-1, 1], append_batch_size=False, dtype="int64")
- embed = fluid.layers.embedding(
- input=input,
- size=[100, 11],
- dtype='float32')
- ones = fluid.layers.fill_constant_batch_size_like(input=label, shape=[-1, 1], dtype="int64", value=1)
- show_clk = fluid.layers.cast(fluid.layers.concat([ones, label], axis=1), dtype='float32')
- show_clk.stop_gradient = True
- input_with_cvm = fluid.layers.continuous_value_model(embed, show_clk, True)
conv2d
paddle.fluid.layers.conv2d(input, num_filters, filter_size, stride=1, padding=0, dilation=1, groups=None, param_attr=None, bias_attr=None, use_cudnn=True, act=None, name=None)- 卷积二维层(convolution2D layer)根据输入、滤波器(filter)、步长(stride)、填充(padding)、dilations、一组参数计算输出。输入和输出是NCHW格式,N是批尺寸,C是通道数,H是特征高度,W是特征宽度。滤波器是MCHW格式,M是输出图像通道数,C是输入图像通道数,H是滤波器高度,W是滤波器宽度。如果组数大于1,C等于输入图像通道数除以组数的结果。详情请参考UFLDL’s : 卷积 。如果提供了bias属性和激活函数类型,bias会添加到卷积(convolution)的结果中相应的激活函数会作用在最终结果上。
对每个输入X,有等式:
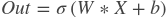
- 其中:
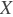 :输入值,NCHW格式的张量(Tensor)
:输入值,NCHW格式的张量(Tensor)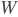 :滤波器值,MCHW格式的张量(Tensor)
:滤波器值,MCHW格式的张量(Tensor) : 卷积操作
: 卷积操作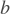 :Bias值,二维张量(Tensor),shape为
:Bias值,二维张量(Tensor),shape为 [M,1]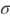 :激活函数
:激活函数 :输出值,
:输出值,Out和X的shape可能不同示例
输入:
输入shape:
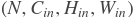
滤波器shape:
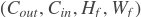
- 输出:
输出shape:
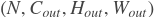
其中
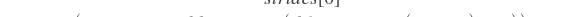
- 参数:
- input (Variable) - 格式为[N,C,H,W]格式的输入图像
- num_fliters (int) - 滤波器数。和输出图像通道相同
- filter_size (int|tuple|None) - 滤波器大小。如果filter_size是一个元组,则必须包含两个整型数,(filter_size,filter_size_W)。否则,滤波器为square
- stride (int|tuple) - 步长(stride)大小。如果步长(stride)为元组,则必须包含两个整型数,(stride_H,stride_W)。否则,stride_H = stride_W = stride。默认:stride = 1
- padding (int|tuple) - 填充(padding)大小。如果填充(padding)为元组,则必须包含两个整型数,(padding_H,padding_W)。否则,padding_H = padding_W = padding。默认:padding = 0
- dilation (int|tuple) - 膨胀(dilation)大小。如果膨胀(dialation)为元组,则必须包含两个整型数,(dilation_H,dilation_W)。否则,dilation_H = dilation_W = dilation。默认:dilation = 1
- groups (int) - 卷积二维层(Conv2D Layer)的组数。根据Alex Krizhevsky的深度卷积神经网络(CNN)论文中的成组卷积:当group=2,滤波器的前一半仅和输入通道的前一半连接。滤波器的后一半仅和输入通道的后一半连接。默认:groups = 1
- param_attr (ParamAttr|None) - conv2d的可学习参数/权重的参数属性。如果设为None或者ParamAttr的一个属性,conv2d创建ParamAttr为param_attr。如果param_attr的初始化函数未设置,参数则初始化为
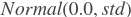 ,并且std为
,并且std为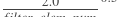 。默认为None
。默认为None - bias_attr (ParamAttr|bool|None) - conv2d bias的参数属性。如果设为False,则没有bias加到输出。如果设为None或者ParamAttr的一个属性,conv2d创建ParamAttr为bias_attr。如果bias_attr的初始化函数未设置,bias初始化为0.默认为None
- use_cudnn (bool) - 是否用cudnn核,仅当下载cudnn库才有效。默认:True
- act (str) - 激活函数类型,如果设为None,则未添加激活函数。默认:None
- name (str|None) - 该层名称(可选)。若设为None,则自动为该层命名。返回:张量,存储卷积和非线性激活结果
返回类型:变量(Variable)
- 抛出异常:
ValueError- 如果输入shape和filter_size,stride,padding和group不匹配。代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32], dtype='float32')
- conv2d = fluid.layers.conv2d(input=data, num_filters=2, filter_size=3, act="relu")
conv2d_transpose
paddle.fluid.layers.conv2dtranspose(_input, num_filters, output_size=None, filter_size=None, padding=0, stride=1, dilation=1, groups=None, param_attr=None, bias_attr=None, use_cudnn=True, act=None, name=None)- 2-D卷积转置层(Convlution2D transpose layer)
该层根据 输入(input)、滤波器(filter)和卷积核膨胀(dilations)、步长(stride)、填充(padding)来计算输出。输入(Input)和输出(Output)为NCHW格式,其中 N 为batch大小, C 为通道数(channel),H 为特征高度, W 为特征宽度。参数(膨胀、步长、填充)分别都包含两个元素。这两个元素分别表示高度和宽度。欲了解卷积转置层细节,请参考下面的说明和 参考文献 。如果参数 bias_attr 和 act 不为 None,则在卷积的输出中加入偏置,并对最终结果应用相应的激活函数。
输入
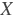 和输出
和输出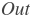 函数关系如下:
函数关系如下:
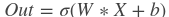
- 其中:
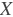 : 输入张量,具有
: 输入张量,具有 NCHW格式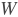 : 滤波器张量,具有
: 滤波器张量,具有 NCHW格式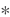 : 卷积操作
: 卷积操作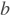 : 偏置(bias),二维张量,shape为
: 偏置(bias),二维张量,shape为 [M,1]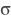 : 激活函数
: 激活函数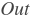 : 输出值,Out和
: 输出值,Out和 X的shape可能不一样样例:
输入:

输出:

其中

- 参数:
- input (Variable)- 输入张量,格式为[N, C, H, W]
- num_filters (int) - 滤波器(卷积核)的个数,与输出的图片的通道数( channel )相同
- output_size (int|tuple|None) - 输出图片的大小。如果output_size是一个元组(tuple),则该元形式为(image_H,image_W),这两个值必须为整型。如果output_size=None,则内部会使用filter_size、padding和stride来计算output_size。如果output_size和filter_size是同时指定的,那么它们应满足上面的公式。
- filter_size (int|tuple|None) - 滤波器大小。如果filter_size是一个tuple,则形式为(filter_size_H, filter_size_W)。否则,滤波器将是一个方阵。如果filter_size=None,则内部会计算输出大小。
- padding (int|tuple) - 填充大小。如果padding是一个元组,它必须包含两个整数(padding_H、padding_W)。否则,padding_H = padding_W = padding。默认:padding = 0。
- stride (int|tuple) - 步长大小。如果stride是一个元组,那么元组的形式为(stride_H、stride_W)。否则,stride_H = stride_W = stride。默认:stride = 1。
- dilation (int|元组) - 膨胀(dilation)大小。如果dilation是一个元组,那么元组的形式为(dilation_H, dilation_W)。否则,dilation_H = dilation_W = dilation_W。默认:dilation= 1。
- groups (int) - Conv2d转置层的groups个数。从Alex Krizhevsky的CNN Deep论文中的群卷积中受到启发,当group=2时,前半部分滤波器只连接到输入通道的前半部分,而后半部分滤波器只连接到输入通道的后半部分。默认值:group = 1。
- param_attr (ParamAttr|None) - conv2d_transfer中可学习参数/权重的属性。如果param_attr值为None或ParamAttr的一个属性,conv2d_transfer使用ParamAttrs作为param_attr的值。如果没有设置的param_attr初始化器,那么使用Xavier初始化。默认值:None。
- bias_attr (ParamAttr|bool|None) - conv2d_tran_bias中的bias属性。如果设置为False,则不会向输出单元添加偏置。如果param_attr值为None或ParamAttr的一个属性,将conv2d_transfer使用ParamAttrs作为,bias_attr。如果没有设置bias_attr的初始化器,bias将初始化为零。默认值:None。
- use_cudnn (bool) - 是否使用cudnn内核,只有已安装cudnn库时才有效。默认值:True。
- act (str) - 激活函数类型,如果设置为None,则不使用激活函数。默认值:None。
- name (str|None) - 该layer的名称(可选)。如果设置为None, 将自动命名该layer。默认值:True。返回: 存储卷积转置结果的张量。
返回类型: 变量(variable)
- 抛出异常:
ValueError: 如果输入的shape、filter_size、stride、padding和groups不匹配,抛出ValueError代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32], dtype='float32')
- conv2d_transpose = fluid.layers.conv2d_transpose(input=data, num_filters=2, filter_size=3)
conv3d
paddle.fluid.layers.conv3d(input, num_filters, filter_size, stride=1, padding=0, dilation=1, groups=None, param_attr=None, bias_attr=None, use_cudnn=True, act=None, name=None)- 3D卷积层(convolution3D layer)根据输入、滤波器(filter)、步长(stride)、填充(padding)、膨胀(dilations)、组数参数计算得到输出。输入和输出是NCHW格式,N是批尺寸,C是通道数,H是特征高度,W是特征宽度。卷积三维(Convlution3D)和卷积二维(Convlution2D)相似,但多了一维深度(depth)。如果提供了bias属性和激活函数类型,bias会添加到卷积(convolution)的结果中相应的激活函数会作用在最终结果上。
对每个输入X,有等式:

- 其中:
 :输入值,NCDHW格式的张量(Tensor)
:输入值,NCDHW格式的张量(Tensor) :滤波器值,MCDHW格式的张量(Tensor)
:滤波器值,MCDHW格式的张量(Tensor) : 卷积操作
: 卷积操作 :Bias值,二维张量(Tensor),形为
:Bias值,二维张量(Tensor),形为 [M,1] :激活函数
:激活函数 :输出值, 和
:输出值, 和 X的形状可能不同示例
- 输入:
- 输入shape:

滤波器shape:

- 输出:
- 输出shape:

其中

- 参数:
- input (Variable) - 格式为[N,C,D,H,W]格式的输入图像
- num_fliters (int) - 滤波器数。和输出图像通道相同
- filter_size (int|tuple|None) - 滤波器大小。如果filter_size是一个元组,则必须包含三个整型数,(filter_size_D, filter_size_H, filter_size_W)。否则,滤波器为棱长为int的立方体形。
- stride (int|tuple) - 步长(stride)大小。如果步长(stride)为元组,则必须包含三个整型数, (stride_D, stride_H, stride_W)。否则,stride_D = stride_H = stride_W = stride。默认:stride = 1
- padding (int|tuple) - 填充(padding)大小。如果填充(padding)为元组,则必须包含三个整型数,(padding_D, padding_H, padding_W)。否则, padding_D = padding_H = padding_W = padding。默认:padding = 0
- dilation (int|tuple) - 膨胀(dilation)大小。如果膨胀(dialation)为元组,则必须包含两个整型数, (dilation_D, dilation_H, dilation_W)。否则,dilation_D = dilation_H = dilation_W = dilation。默认:dilation = 1
- groups (int) - 卷积二维层(Conv2D Layer)的组数。根据Alex Krizhevsky的深度卷积神经网络(CNN)论文中的成组卷积:当group=2,滤波器的前一半仅和输入通道的前一半连接。滤波器的后一半仅和输入通道的后一半连接。默认:groups = 1
- param_attr (ParamAttr|None) - conv2d的可学习参数/权重的参数属性。如果设为None或者ParamAttr的一个属性,conv2d创建ParamAttr为param_attr。如果param_attr的初始化函数未设置,参数则初始化为
 ,并且std为
,并且std为 。默认为None
。默认为None - bias_attr (ParamAttr|bool|None) - conv2d bias的参数属性。如果设为False,则没有bias加到输出。如果设为None或者ParamAttr的一个属性,conv2d创建ParamAttr为bias_attr。如果bias_attr的初始化函数未设置,bias初始化为0.默认为None
- use_cudnn (bool) - 是否用cudnn核,仅当下载cudnn库才有效。默认:True
- act (str) - 激活函数类型,如果设为None,则未添加激活函数。默认:None
- name (str|None) - 该层名称(可选)。若设为None,则自动为该层命名。返回:张量,存储卷积和非线性激活结果
返回类型:变量(Variable)
- 抛出异常:
ValueError- 如果input的形和filter_size,stride,padding和group不匹配。代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 12, 32, 32], dtype='float32')
- conv3d = fluid.layers.conv3d(input=data, num_filters=2, filter_size=3, act="relu")
conv3d_transpose
paddle.fluid.layers.conv3dtranspose(_input, num_filters, output_size=None, filter_size=None, padding=0, stride=1, dilation=1, groups=None, param_attr=None, bias_attr=None, use_cudnn=True, act=None, name=None)- 3-D卷积转置层(Convlution3D transpose layer)
该层根据 输入(input)、滤波器(filter)和卷积核膨胀(dilations)、步长(stride)、填充来计算输出。输入(Input)和输出(Output)为NCDHW格式。其中 N 为batch大小, C 为通道数(channel), D 为特征深度, H 为特征高度, W 为特征宽度。参数(膨胀、步长、填充)分别包含两个元素。这两个元素分别表示高度和宽度。欲了解卷积转置层细节,请参考下面的说明和 参考文献 。如果参数 bias_attr 和 act 不为None,则在卷积的输出中加入偏置,并对最终结果应用相应的激活函数
输入X和输出Out函数关系X,有等式如下:

- 其中:
 : 输入张量,具有
: 输入张量,具有 NCDHW格式 : 滤波器张量,,具有
: 滤波器张量,,具有 NCDHW格式 : 卷积操作
: 卷积操作 : 偏置(bias),二维张量,shape为
: 偏置(bias),二维张量,shape为 [M,1] : 激活函数
: 激活函数 : 输出值,
: 输出值, Out和X的 shape可能不一样样例
输入:

输出:

其中:

- 参数:
- input (Variable)- 输入张量,格式为[N, C, D, H, W]
- num_filters (int) - 滤波器(卷积核)的个数,与输出的图片的通道数(channel)相同
- output_size (int|tuple|None) - 输出图片的大小。如果
output_size是一个元组(tuple),则该元形式为(image_H,image_W),这两个值必须为整型。如果output_size=None,则内部会使用filter_size、padding和stride来计算output_size。如果output_size和filter_size是同时指定的,那么它们应满足上面的公式。 - filter_size (int|tuple|None) - 滤波器大小。如果
filter_size是一个tuple,则形式为(filter_size_H, filter_size_W)。否则,滤波器将是一个方阵。如果filter_size=None,则内部会计算输出大小。 - padding (int|tuple) - 填充大小。如果
padding是一个元组,它必须包含两个整数(padding_H、padding_W)。否则,padding_H = padding_W = padding。默认:padding = 0。 - stride (int|tuple) - 步长大小。如果
stride是一个元组,那么元组的形式为(stride_H、stride_W)。否则,stride_H = stride_W = stride。默认:stride = 1。 - dilation (int|元组) - 膨胀大小。如果
dilation是一个元组,那么元组的形式为(dilation_H, dilation_W)。否则,dilation_H = dilation_W = dilation_W。默认:dilation= 1。 - groups (int) - Conv2d转置层的groups个数。从Alex Krizhevsky的CNN Deep论文中的群卷积中受到启发,当group=2时,前半部分滤波器只连接到输入通道的前半部分,而后半部分滤波器只连接到输入通道的后半部分。默认值:group = 1。
- param_attr (ParamAttr|None) - conv2d_transfer中可学习参数/权重的属性。如果param_attr值为None或ParamAttr的一个属性,conv2d_transfer使用ParamAttrs作为param_attr的值。如果没有设置的param_attr初始化器,那么使用Xavier初始化。默认值:None。
- bias_attr (ParamAttr|bool|None) - conv2d_tran_bias中的bias属性。如果设置为False,则不会向输出单元添加偏置。如果param_attr值为None或ParamAttr的一个属性,将conv2d_transfer使用ParamAttrs作为,bias_attr。如果没有设置bias_attr的初始化器,bias将初始化为零。默认值:None。
- use_cudnn (bool) - 是否使用cudnn内核,只有已安装cudnn库时才有效。默认值:True。
- act (str) - 激活函数类型,如果设置为None,则不使用激活函数。默认值:None。
- name (str|None) - 该layer的名称(可选)。如果设置为None, 将自动命名该layer。默认值:True。返回: 存储卷积转置结果的张量。
返回类型: 变量(variable)
- 抛出异常:
ValueError: 如果输入的shape、filter_size、stride、padding和groups不匹配,抛出ValueError代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 12, 32, 32], dtype='float32')
- conv3d_transpose = fluid.layers.conv3d_transpose(input=data, num_filters=2, filter_size=3)
cos_sim
paddle.fluid.layers.cossim(_X, Y)- 余弦相似度算子(Cosine Similarity Operator)

输入X和Y必须具有相同的shape,除非输入Y的第一维为1(不同于输入X),在计算它们的余弦相似度之前,Y的第一维会被broadcasted,以匹配输入X的shape。
输入X和Y都携带或者都不携带LoD(Level of Detail)信息。但输出仅采用输入X的LoD信息。
- 参数:
- X (Variable) - cos_sim操作函数的一个输入
- Y (Variable) - cos_sim操作函数的第二个输入返回:cosine(X,Y)的输出
返回类型:变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[3, 7], dtype='float32', append_batch_size=False)
- y = fluid.layers.data(name='y', shape=[1, 7], dtype='float32', append_batch_size=False)
- out = fluid.layers.cos_sim(x, y)
crf_decoding
paddle.fluid.layers.crfdecoding(_input, param_attr, label=None)- 该函数读取由
linear_chain_crf学习的emission feature weights(发射状态特征的权重)和 transition feature weights(转移特征的权重)。本函数实现了Viterbi算法,可以动态地寻找隐藏状态最可能的序列,该序列也被称为Viterbi路径(Viterbi path),从而得出的标注(tags)序列。
这个运算的结果会随着 Label 参数的有无而改变:
Label非None的情况,在实际训练中时常发生。此时本函数会协同chunk_eval工作。本函数会返回一行形为[N X 1]的向量,其中值为0的部分代表该label不适合作为对应结点的标注,值为1的部分则反之。此类型的输出可以直接作为chunk_eval算子的输入- 当没有
Label时,该函数会执行标准decoding过程
(没有 Label 时)该运算返回一个形为 [N X 1]的向量,其中元素取值范围为 0 ~ 最大标注个数-1,分别为预测出的标注(tag)所在的索引。
- 参数:
- input (Variable)(LoDTensor,默认类型为 LoDTensor
) — 一个形为 [N x D] 的LoDTensor,其中 N 是mini-batch的大小,D是标注(tag) 的总数。 该输入是 linear_chain_crf的 unscaled emission weight matrix (未标准化的发射权重矩阵) - param_attr (ParamAttr) — 参与训练的参数的属性
- label (Variable)(LoDTensor,默认类型为 LoDTensor
) — 形为[N x 1]的正确标注(ground truth)。 该项可选择传入。 有关该参数的更多信息,请详见上述描述 返回:(LoDTensor, LoDTensor<int64_t>)decoding结果。具体内容根据Label参数是否提供而定。请参照函数介绍来详细了解。
- input (Variable)(LoDTensor,默认类型为 LoDTensor
返回类型: Variable
代码示例
- import paddle.fluid as fluid
- images = fluid.layers.data(name='pixel', shape=[784], dtype='float32')
- label = fluid.layers.data(name='label', shape=[1], dtype='int32')
- hidden = fluid.layers.fc(input=images, size=2)
- crf = fluid.layers.linear_chain_crf(input=hidden, label=label,
- param_attr=fluid.ParamAttr(name="crfw"))
- crf_decode = fluid.layers.crf_decoding(input=hidden,
- param_attr=fluid.ParamAttr(name="crfw"))
crop
paddle.fluid.layers.crop(x, shape=None, offsets=None, name=None)- 根据偏移量(offsets)和形状(shape),裁剪输入张量。
样例:
- * Case 1:
- Given
- X = [[0, 1, 2, 0, 0]
- [0, 3, 4, 0, 0]
- [0, 0, 0, 0, 0]],
- and
- shape = [2, 2],
- offsets = [0, 1],
- output is:
- Out = [[1, 2],
- [3, 4]].
- * Case 2:
- Given
- X = [[0, 1, 2, 5, 0]
- [0, 3, 4, 6, 0]
- [0, 0, 0, 0, 0]],
- and shape is tensor
- shape = [[0, 0, 0]
- [0, 0, 0]]
- and
- offsets = [0, 1],
- output is:
- Out = [[1, 2, 5],
- [3, 4, 6]].
- 参数:
- x (Variable): 输入张量。
- shape (Variable|list/tuple of integer) - 输出张量的形状由参数shape指定,它可以是一个变量/整数的列表/整数元组。如果是张量变量,它的秩必须与x相同。该方式适可用于每次迭代时候需要改变输出形状的情况。如果是整数列表/tupe,则其长度必须与x的秩相同
- offsets (Variable|list/tuple of integer|None) - 指定每个维度上的裁剪的偏移量。它可以是一个Variable,或者一个整数list/tupe。如果是一个tensor variable,它的rank必须与x相同,这种方法适用于每次迭代的偏移量(offset)都可能改变的情况。如果是一个整数list/tupe,则长度必须与x的rank的相同,如果shape=None,则每个维度的偏移量为0。
- name (str|None) - 该层的名称(可选)。如果设置为None,该层将被自动命名。返回: 裁剪张量。
返回类型: 变量(Variable)
抛出异常: 如果形状不是列表、元组或变量,抛出ValueError
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3, 5], dtype="float32")
- y = fluid.layers.data(name="y", shape=[2, 3], dtype="float32")
- crop = fluid.layers.crop(x, shape=y)
- ## or
- z = fluid.layers.data(name="z", shape=[3, 5], dtype="float32")
- crop = fluid.layers.crop(z, shape=[2, 3])
cross_entropy
paddle.fluid.layers.crossentropy(_input, label, soft_label=False, ignore_index=-100)- 该函数定义了输入和标签之间的cross entropy(交叉熵)层。该函数支持standard cross-entropy computation(标准交叉熵损失计算)以及soft-label cross-entropy computation(软标签交叉熵损失计算)
One-hot cross-entropy算法
- soft_label = False, Label[i, 0] 指明样本i的类别所具的索引:
Soft-label cross-entropy算法
- soft_label = True, Label[i, j] 表明样本i对应类别j的soft label(软标签):
请确保采用此算法时识别为各软标签的概率总和为1
One-hot cross-entropy with vecterized label(使用向量化标签的One-hot)算法
作为 2 的特殊情况,当软类标签内部只有一个非零概率元素,且它的值为1,那么 2 算法降级为一种仅有one-hot标签的one-hot交叉熵


- 参数:
- input (Variable|list) – 一个形为[N x D]的二维tensor,其中N是batch大小,D是类别(class)数目。 这是由之前的operator计算出的概率,绝大多数情况下是由softmax operator得出的结果
- label (Variable|list) – 一个二维tensor组成的正确标记的数据集(ground truth)。 当
soft_label为False时,label为形为[N x 1]的tensor。 soft_label为True时, label是形为 [N x D]的 tensor - soft_label (bool) – 标志位,指明是否需要把给定的标签列表认定为软标签。默认为False。
- ignore_index (int) – 指定一个被无视的目标值,并且这个值不影响输入梯度。仅在
soft_label为False时生效。 默认值: kIgnoreIndex返回: 一个形为[N x 1]的二维tensor,承载了交叉熵损失
弹出异常: ValueError
- 当
input的第一维和label的第一维不相等时,弹出异常- 当
soft_label值为True, 且input的第二维和label的第二维不相等时,弹出异常- 当
soft_label值为False,且label的第二维不是1时,弹出异常
代码示例
- import paddle.fluid as fluid
- classdim = 7
- x = fluid.layers.data(name='x', shape=[3, 7], dtype='float32', append_batch_size=False)
- label = fluid.layers.data(name='label', shape=[3, 1], dtype='float32', append_batch_size=False)
- predict = fluid.layers.fc(input=x, size=classdim, act='softmax')
- cost = fluid.layers.cross_entropy(input=predict, label=label)
ctc_greedy_decoder
paddle.fluid.layers.ctcgreedy_decoder(_input, blank, name=None)- 此op用于贪婪策略解码序列,步骤如下:
- 获取输入中的每一行的最大值索引,也就是numpy.argmax(input, axis=0)。
- 对于step1结果中的每个序列,在两个空格之间合并重复部分(即合并重复的上一步中的到的索引值)并删除所有空格。简单举一个例子,
- 已知:
- input.data = [[0.6, 0.1, 0.3, 0.1],
- [0.3, 0.2, 0.4, 0.1],
- [0.1, 0.5, 0.1, 0.3],
- [0.5, 0.1, 0.3, 0.1],
- [0.5, 0.1, 0.3, 0.1],
- [0.2, 0.2, 0.2, 0.4],
- [0.2, 0.2, 0.1, 0.5],
- [0.5, 0.1, 0.3, 0.1]]
- input.lod = [[4, 4]]
- 计算过程:
- 1. 将argmax的运算结果应用于输入的第一个序列,即 input.data[0:4] 。
- 则得出的结果为[[0], [2], [1], [0]]
- 2. 合并重复的索引值部分,删除空格,即为0的值。
- 则第一个输入序列对应的输出为:[[2], [1]]
- 最后
- output.data = [[2],
- [1],
- [3]]
- output.lod = [[2, 1]]
- 参数:
- input (Variable) — (LoDTensor
),变长序列的概率,它是一个具有LoD信息的二维张量。它的形状是[Lp, num_classes + 1],其中Lp是所有输入序列长度的和,num_classes是真正的类别。(不包括空白标签)。 - blank (int) — Connectionist Temporal Classification (CTC) loss空白标签索引, 属于半开区间[0,num_classes + 1)。
- name (str) — 此层的名称。可选。返回: CTC贪婪解码结果是一个形为(Lp,1)的二维张量,其中Lp是所有输出序列的长度之和。如果结果中的所有序列都为空,则输出LoDTensor 为[-1],其中LoD[[]] 形为[1,1]。
- input (Variable) — (LoDTensor
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[8], dtype='float32')
- cost = fluid.layers.ctc_greedy_decoder(input=x, blank=0)
data_norm
paddle.fluid.layers.datanorm(_input, act=None, epsilon=1e-05, param_attr=None, data_layout='NCHW', in_place=False, name=None, moving_mean_name=None, moving_variance_name=None, do_model_average_for_mean_and_var=False)- 数据正则化层
可用作conv2d和fully_connected操作的正则化函数。 此层所需的数据格式为以下之一:
- NHWC [batch, in_height, in_width, in_channels]
- NCHW [batch, in_channels, in_height, in_width]
 为一个mini-batch上的特征:
为一个mini-batch上的特征:

- 参数:
- input (variable) - 输入变量,它是一个LoDTensor。
- act (string,默认None) - 激活函数类型,线性| relu | prelu | …
- epsilon (float,默认1e-05) -
- param_attr (ParamAttr) - 参数比例的参数属性。
- data_layout (string,默认NCHW) - NCHW | NHWC
- in_place (bool,默认值False) - 使data_norm的输入和输出复用同一块内存。
- name (string,默认None) - 此层的名称(可选)。 如果设置为None,则将自动命名该层。
- moving_mean_name (string,Default None) - 存储全局Mean的moving_mean的名称。
- moving_variance_name (string,默认None) - 存储全局Variance的moving_variance的名称。
- do_model_average_for_mean_and_var (bool,默认值为false) - 是否为mean和variance进行模型平均。返回: 张量变量,是对输入数据进行正则化后的结果。
返回类型: Variable
代码示例
- import paddle.fluid as fluid
- hidden1 = fluid.layers.data(name="hidden1", shape=[200])
- hidden2 = fluid.layers.data_norm(name="hidden2", input=hidden1)
deformable_conv
paddle.fluid.layers.deformableconv(_input, offset, mask, num_filters, filter_size, stride=1, padding=0, dilation=1, groups=None, deformable_groups=None, im2col_step=None, param_attr=None, bias_attr=None, name=None)- 可变形卷积层
在4-D输入上计算2-D可变形卷积。给定输入图像x,输出特征图y,可变形卷积操作如下所示:[y(p) = sum_{k=1}^{K}{w_k x(p + p_k + Delta p_k) Delta m_k}]其中(Delta p_k) 和 (Delta m_k) 分别为第k个位置的可学习偏移和调制标量。参考可变形卷积网络v2:可变形程度越高,结果越好。
示例
- 输入:
- 输入形状: ((N, C{in}, H{in}, W{in}))卷积核形状: ((C{out}, C{in}, H_f, W_f))偏移形状: ((N, 2 deformable_groups H_f * H_w, H{in}, W{in}))掩膜形状: ((N, deformable_groups H_f H_w, H{in}, W_{in}))
- 输出:
- 输出形状: ((N, C{out}, H{out}, W_{out}))
- 其中
- [begin{split}H{out}&= frac{(H{in} + 2 paddings[0] - (dilations[0] (Hf - 1) + 1))}{strides[0]} + 1 \W{out}&= frac{(W_{in} + 2 paddings[1] - (dilations[1] (W_f - 1) + 1))}{strides[1]} + 1end{split}]
- 参数:
- input (Variable) - 形式为[N, C, H, W]的输入图像。
- offset (Variable) – 可变形卷积层的输入坐标偏移。
- Mask (Variable) – 可变形卷积层的输入掩膜。
- num_filters (int) – 卷积核数。和输出图像通道数相同。
- filter_size (int|tuple|None) – 卷积核大小。如果filter_size为元组,则必须包含两个整数(filter_size_H, filter_size_W)。否则卷积核将为方形。
- stride (int|tuple) – 步长大小。如果stride为元组,则必须包含两个整数(stride_H, stride_W)。否则stride_H = stride_W = stride。默认stride = 1。
- padding (int|tuple) – padding大小。如果padding为元组,则必须包含两个整数(padding_H, padding_W)。否则padding_H = padding_W = padding。默认padding = 0。
- dilation (int|tuple) – dilation大小。如果dilation为元组,则必须包含两个整数(dilation_H, dilation_W)。否则dilation_H = dilation_W = dilation。默认dilation = 1。
- groups (int) – 可变形卷积层的群组数。依据Alex Krizhevsky的Deep CNN论文中的分组卷积,有:当group=2时,前一半卷积核只和前一半输入通道有关,而后一半卷积核只和后一半输入通道有关。默认groups=1。
- deformable_groups (int) – 可变形群组分区数。默认deformable_groups = 1。
- im2col_step (int) – 每个im2col计算的最大图像数。总batch大小应该可以被该值整除或小于该值。如果您面临内存问题,可以尝试在此处使用一个更小的值。默认im2col_step = 64。
- param_attr (ParamAttr|None) – 可变形卷积的可学习参数/权重的参数属性。如果将其设置为None或ParamAttr的一个属性,可变形卷积将创建ParamAttr作为param_attr。如果没有设置此param_attr的Initializer,该参数将被(Normal(0.0, std))初始化,且其中的(std) 为 ((frac{2.0 }{filter_elem_num})^{0.5})。默认值None。
- bias_attr (ParamAttr|bool|None) – 可变形卷积层的偏置的参数属性。如果设为False,则输出单元不会加偏置。如果设为None或者ParamAttr的一个属性,conv2d会创建ParamAttr作为bias_attr。如果不设置bias_attr的Initializer,偏置会被初始化为0。默认值None。
- name (str|None) – 该层的名字(可选项)。如果设为None,该层将会被自动命名。默认值None。返回:储存可变形卷积结果的张量变量。
返回类型:变量(Variable)
抛出:ValueError – 如果input, filter_size, stride, padding和groups的大小不匹配。
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32], dtype='float32')
- offset = fluid.layers.data(name='offset', shape=[18, 32, 32], dtype='float32')
- mask = fluid.layers.data(name='mask', shape=[9, 32, 32], dtype='float32')
- out = fluid.layers.deformable_conv(input=data, offset=offset, mask=mask, num_filters=2, filter_size=3, padding=1)
deformable_roi_pooling
paddle.fluid.layers.deformableroi_pooling(_input, rois, trans, no_trans=False, spatial_scale=1.0, group_size=[1, 1], pooled_height=1, pooled_width=1, part_size=None, sample_per_part=1, trans_std=0.1, position_sensitive=False, name=None)可变形PSROI池层
参数:
- input (Variable) - 可变形PSROI池层的输入。输入张量的形状为[N,C,H,W]。其中N是批量大小,C是输入通道的数量,H是特征的高度,W是特征的宽度。
- rois (Variable)- 将池化的ROIs(感兴趣区域)。应为一个形状为(num_rois, 4)的2-D LoDTensor,且lod level为1。给出[[x1, y1, x2, y2], …],(x1, y1)为左上角坐标,(x2, y2)为右下角坐标。
- trans (Variable)- 池化时ROIs上的特征偏移。格式为NCHW,其中N是ROIs的数量,C是通道的数量,指示x和y方向上的偏移距离,H是池化的高度,W是池化的宽度。
- no_trans (bool)- roi池化阶段是否加入偏移以获取新值。取True或False。默认为False。
- spatial_scale (float) - 输入特征图的高度(或宽度)与原始图像高度(或宽度)的比率。等于卷积图层中总步长的倒数,默认为1.0。
- group_size (list|tuple)- 输入通道划分成的组数(例如,输入通道的数量是k1 k2 [](https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/api_cn/layers_cn/#id5)(C + 1),其中k1和k2是组宽度和高度,C + 1是输出通道的数量。如( 4,6)中4是组的高度,6是组的宽度)。默认为[1,1]。
- pooled_height (integer)- 池化后输出的高度。
- pooled_width (integer)- 池化后输出的宽度。
- part_size (list|tuple)- 偏移高度和宽度,如(4, 6)代表高度为4、宽度为6,默认为None,此时默认值[pooled_height, pooled_width]。
- sample_per_part (integer)- 每个bin中的样本数量,默认为1。
- trans_std (float)- 偏移系数,默认为0.1。
- position_sensitive (bool)- 是否选择可变形psroi池化模式,默认为False。
- name (str)- 层名,默认为None。返回: 存储可变形psroi池层的张量变量
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input",
- shape=[2, 192, 64, 64],
- dtype='float32',
- append_batch_size=False)
- rois = fluid.layers.data(name="rois",
- shape=[4],
- dtype='float32',
- lod_level=1)
- trans = fluid.layers.data(name="trans",
- shape=[2, 384, 64, 64],
- dtype='float32',
- append_batch_size=False)
- x = fluid.layers.nn.deformable_roi_pooling(input=input,
- rois=rois,
- trans=trans,
- no_trans=False,
- spatial_scale=1.0,
- group_size=(1, 1),
- pooled_height=8,
- pooled_width=8,
- part_size=(8, 8),
- sample_per_part=4,
- trans_std=0.1,
- position_sensitive=False)
dice_loss
paddle.fluid.layers.diceloss(_input, label, epsilon=1e-05)- dice_loss是比较两批数据相似度,通常用于二值图像分割,即标签为二值。
dice_loss定义为:

- 参数:
- input (Variable) - rank>=2的预测。第一个维度是batch大小,最后一个维度是类编号。
- label (Variable)- 与输入tensor rank相同的正确的标注数据(groud truth)。第一个维度是batch大小,最后一个维度是1。
- epsilon (float) - 将会加到分子和分母上。如果输入和标签都为空,则确保dice为1。默认值:0.00001返回: dice_loss shape为[1]。
返回类型: dice_loss(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='data', shape = [3, 224, 224, 2], dtype='float32')
- label = fluid.layers.data(name='label', shape=[3, 224, 224, 1], dtype='float32')
- predictions = fluid.layers.softmax(x)
- loss = fluid.layers.dice_loss(input=predictions, label=label)
dropout
paddle.fluid.layers.dropout(x, dropout_prob, is_test=False, seed=None, name=None, dropout_implementation='downgrade_in_infer')- dropout操作
丢弃或者保持x的每个元素独立。Dropout是一种正则化技术,通过在训练过程中阻止神经元节点间的联合适应性来减少过拟合。根据给定的丢弃概率dropout操作符随机将一些神经元输出设置为0,其他的仍保持不变。
dropout op可以从Program中删除,提高执行效率。
- 参数:
x (Variable)-输入张量
dropout_prob (float)-设置为0的单元的概率
is_test (bool)-显示是否进行测试用语的标记
seed (int)-Python整型,用于创建随机种子。如果该参数设为None,则使用随机种子。注:如果给定一个整型种子,始终丢弃相同的输出单元。训练过程中勿用固定不变的种子。
name (str|None)-该层名称(可选)。如果设置为None,则自动为该层命名
dropout_implementation (string) -
[‘downgrade_in_infer’(default)|’upscale_in_train’] 其中:
-
downgrade_in_infer(default), 在预测时减小输出结果
- train: out = input * mask- inference: out = input * (1.0 - dropout_prob)
(mask是一个张量,维度和输入维度相同,值为0或1,值为0的比例即为 dropout_prob )
-
upscale_in_train, 增加训练时的结果
- train: out = input * mask / ( 1.0 - dropout_prob )- inference: out = input
(mask是一个张量,维度和输入维度相同,值为0或1,值为0的比例即为 dropout_prob )
dropout操作符可以从程序中移除,程序变得高效。
返回:与输入X,shape相同的张量
返回类型:变量
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="data", shape=[32, 32], dtype="float32")
- droped = fluid.layers.dropout(x, dropout_prob=0.5)
dynamic_gru
paddle.fluid.layers.dynamicgru(_input, size, param_attr=None, bias_attr=None, is_reverse=False, gate_activation='sigmoid', candidate_activation='tanh', h_0=None, origin_mode=False)- 实现了Gated Recurrent Unit层。
如果origin_mode为False,那么gru运算公式来自论文 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling 。
公式如下:




如果origin_mode为True,那么运算公式来自于 Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation
公式如下:

其中,
 为按元素将向量相乘。
为按元素将向量相乘。 是更新门(update gate)和重置门(reset gate)的激励函数(activation), 常为
是更新门(update gate)和重置门(reset gate)的激励函数(activation), 常为 函数。
函数。 是candidate hidden state(候选隐藏状态)的激励函数,常为
是candidate hidden state(候选隐藏状态)的激励函数,常为 。
。
注意
 这些在 input
这些在 input 上的操作不包括在该运算中。用户可以选择性地在GRU层之前使用FC层来进行这一操作。
上的操作不包括在该运算中。用户可以选择性地在GRU层之前使用FC层来进行这一操作。
- 参数:
input (Variable) – dynamic_gru层的输入, 支持variable time length input sequence(可变时长输入序列)。 本变量底层的tensor是一个(T×3D)矩阵, 其中T是该mini-batch中总时间步数, D是隐藏状态的规模(hidden size)。
size (int) – GRU cell的维度
param_attr (ParamAttr|None) – 可学习的隐藏层权重矩阵的参数属性。注意:
- 该矩阵为一个(T X 3D)矩阵。其中D为隐藏状态的规模(hidden size)
- 该矩阵的所有元素由两部分组成。一是update gate和reset gate的权重,形为(D X 2D),二是候选隐藏状态(candidate hidden state)的权重,形为 (D X D)
如果该函数参数被设为None或者 ParamAttr 类的属性之一,则会生成一个 ParamAttr 类的对象作为param_attr。如果param_attr未被初始化(即其构造函数未被设置),Xavier会负责初始化它。 默认值为None。
bias_attr (ParamAttr|bool|None) - GRU层bias的参数属性。该(1 X 3D)形的bias变量将会连结(concatenate)在update gate(更新门)、reset gate(重置门)、candidate calculations(候选隐藏状态计算)后。如果值为False,将没有bias会应用到上述三个过程中。如果该函数参数被设为None或者
ParamAttr类的属性之一,dynamic_gru会生成一个ParamAttr类的对象作为param_attr。如果bias_attr未被初始化(即其构造函数未被设置),则它会被初始化为0。默认值为None。is_reverse (bool) –是否计算反GRU(reversed GRU),默认为False
gate_activation (str) – update gate 和 reset gate的激励函数(activation)。 可选择[“sigmoid”, “tanh”, “relu”, “identity”]其一, 默认为 “sigmoid”
candidate_activation (str) – candidate hidden state(候选隐藏状态)计算所需的激励函数(activation)。 可从[“sigmoid”, “tanh”, “relu”, “identity”]中选择, 默认为 “tanh”
h_0 (Variable) – 该函数参数为初始隐藏状态。若未赋值,则默认为0。它是一个 (N x D) tensor, 其中 N 为输入mini-batch的总时间步数, D 为 隐藏状态规模(hidden size)
返回: GRU的隐藏状态(hidden state)。形为(T X D),序列长度和输入相同。
返回类型: 变量(variable)
代码示例
- import paddle.fluid as fluid
- dict_dim, emb_dim = 128, 64
- data = fluid.layers.data(name='sequence', shape=[1],
- dtype='int32', lod_level=1)
- emb = fluid.layers.embedding(input=data, size=[dict_dim, emb_dim])
- hidden_dim = 512
- x = fluid.layers.fc(input=emb, size=hidden_dim * 3)
- hidden = fluid.layers.dynamic_gru(input=x, size=hidden_dim)
dynamic_lstm
paddle.fluid.layers.dynamiclstm(_input, size, h_0=None, c_0=None, param_attr=None, bias_attr=None, use_peepholes=True, is_reverse=False, gate_activation='sigmoid', cell_activation='tanh', candidate_activation='tanh', dtype='float32', name=None)- LSTM,即Long-Short Term Memory(长短期记忆)运算。
默认实现方式为diagonal/peephole连接(https://arxiv.org/pdf/1402.1128.pdf),公式如下:






W 代表了权重矩阵(weight matrix),例如
 是从输入门(input gate)到输入的权重矩阵,
是从输入门(input gate)到输入的权重矩阵, ,
, ,
, 是对角权重矩阵(diagonal weight matrix),用于peephole连接。在此实现方式中,我们使用向量来代表这些对角权重矩阵。
是对角权重矩阵(diagonal weight matrix),用于peephole连接。在此实现方式中,我们使用向量来代表这些对角权重矩阵。
- 其中:
 表示bias向量(
表示bias向量( 是输入门的bias向量)
是输入门的bias向量) 是非线性激励函数(non-linear activations),比如逻辑sigmoid函数
是非线性激励函数(non-linear activations),比如逻辑sigmoid函数 ,
, ,
, 和
和 分别为输入门(input gate),遗忘门(forget gate),输出门(output gate),以及神经元激励向量(cell activation vector)这些向量和神经元输出激励向量(cell output activation vector)
分别为输入门(input gate),遗忘门(forget gate),输出门(output gate),以及神经元激励向量(cell activation vector)这些向量和神经元输出激励向量(cell output activation vector) 有相同的大小。
有相同的大小。 意为按元素将两向量相乘
意为按元素将两向量相乘 ,
, 分别为神经元(cell)输入、输出的激励函数(activation)。常常使用tanh函数。
分别为神经元(cell)输入、输出的激励函数(activation)。常常使用tanh函数。 也被称为候选隐藏状态(candidate hidden state)。可根据当前输入和之前的隐藏状态计算而得将
也被称为候选隐藏状态(candidate hidden state)。可根据当前输入和之前的隐藏状态计算而得将 use_peepholes设为False来禁用 peephole 连接方法。 公式等详细信息请参考 http://www.bioinf.jku.at/publications/older/2604.pdf 。
注意,
 这些在输入
这些在输入 上的操作不包括在此运算中。用户可以在LSTM operator之前选择使用全连接运算。
上的操作不包括在此运算中。用户可以在LSTM operator之前选择使用全连接运算。
- 参数:
input (Variable) (LoDTensor) - LodTensor类型,支持variable time length input sequence(时长可变的输入序列)。 该LoDTensor中底层的tensor是一个形为(T X 4D)的矩阵,其中T为此mini-batch上的总共时间步数。D为隐藏层的大小、规模(hidden size)
size (int) – 4 * 隐藏层大小
h_0 (Variable) – 最初的隐藏状态(hidden state),可选项。默认值为0。它是一个(N x D)张量,其中N是batch大小,D是隐藏层大小。
c_0 (Variable) – 最初的神经元状态(cell state), 可选项。 默认值0。它是一个(N x D)张量, 其中N是batch大小。h_0和c_0仅可以同时为None,不能只其中一个为None。
param_attr (ParamAttr|None) – 可学习的隐藏层权重的参数属性。注意:
- Weights =
- 形为(D x 4D), 其中D是hidden size(隐藏层规模)

如果它被设为None或者 ParamAttr 属性之一, dynamic_lstm会创建 ParamAttr 对象作为param_attr。如果没有对param_attr初始化(即构造函数没有被设置), Xavier会负责初始化参数。默认为None。
- bias_attr (ParamAttr|None) – 可学习的bias权重的属性, 包含两部分,input-hidden bias weights(输入隐藏层的bias权重)和 peephole connections weights(peephole连接权重)。如果
use_peepholes值为True, 则意为使用peephole连接的权重。另外:
- use_peepholes = False - Biases =
- 形为(1 x 4D)。- use_peepholes = True - Biases =
- 形为 (1 x 7D)。


如果它被设为None或 ParamAttr 的属性之一, dynamic_lstm 会创建一个 ParamAttr 对象作为bias_attr。 如果没有对bias_attr初始化(即构造函数没有被设置),bias会被初始化为0。默认值为None。
use_peepholes (bool) – (默认: True) 是否使用diagonal/peephole连接方式
is_reverse (bool) – (默认: False) 是否计算反LSTM(reversed LSTM)
gate_activation (str) – (默认: “sigmoid”)应用于input gate(输入门),forget gate(遗忘门)和 output gate(输出门)的激励函数(activation),默认为sigmoid
cell_activation (str) – (默认: tanh)用于神经元输出的激励函数(activation), 默认为tanh
candidate_activation (str) – (默认: tanh)candidate hidden state(候选隐藏状态)的激励函数(activation), 默认为tanh
dtype (str) – 即 Data type(数据类型)。 可以选择 [“float32”, “float64”],默认为“float32”
name (str|None) – 该层的命名,可选项。如果值为None, 将会自动对该层命名
返回:隐藏状态(hidden state),LSTM的神经元状态。两者都是(T x D)形,且LoD保持与输入一致
返回类型: 元组(tuple)
代码示例
- import paddle.fluid as fluid
- emb_dim = 256
- vocab_size = 10000
- hidden_dim = 512
- data = fluid.layers.data(name='x', shape=[1],
- dtype='int32', lod_level=1)
- emb = fluid.layers.embedding(input=data, size=[vocab_size, emb_dim], is_sparse=True)
- forward_proj = fluid.layers.fc(input=emb, size=hidden_dim * 4,
- bias_attr=False)
- forward, _ = fluid.layers.dynamic_lstm(
- input=forward_proj, size=hidden_dim * 4, use_peepholes=False)
dynamic_lstmp
paddle.fluid.layers.dynamiclstmp(_input, size, proj_size, param_attr=None, bias_attr=None, use_peepholes=True, is_reverse=False, gate_activation='sigmoid', cell_activation='tanh', candidate_activation='tanh', proj_activation='tanh', dtype='float32', name=None, h_0=None, c_0=None, cell_clip=None, proj_clip=None)- 动态LSTMP层(Dynamic LSTMP Layer)
LSTMP层(具有循环映射的LSTM)在LSTM层后有一个分离的映射层,从原始隐藏状态映射到较低维的状态,用来减少参数总数,减少LSTM计算复杂度,特别是输出单元相对较大的情况下。 Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling
公式如下:

- 在以上公式中:
 : 代表权重矩阵(例如
: 代表权重矩阵(例如 是输入门道输入的权重矩阵)
是输入门道输入的权重矩阵) ,
, ,
, : peephole connections的对角权重矩阵。在我们的实现中,外面用向量代表这些对角权重矩阵
: peephole connections的对角权重矩阵。在我们的实现中,外面用向量代表这些对角权重矩阵 : 代表偏差向量(例如
: 代表偏差向量(例如 是输入偏差向量)
是输入偏差向量) : 激活函数,比如逻辑回归函数
: 激活函数,比如逻辑回归函数 和
和 :分别代表输入门,遗忘门,输出门和cell激活函数向量,四者的大小和cell输出激活函数向量
:分别代表输入门,遗忘门,输出门和cell激活函数向量,四者的大小和cell输出激活函数向量 的四者大小相等
的四者大小相等 : 隐藏状态
: 隐藏状态 : 隐藏状态的循环映射
: 隐藏状态的循环映射 : 候选隐藏状态
: 候选隐藏状态 : 向量的元素状态生成
: 向量的元素状态生成 和
和 : cell输入和cell输出激活函数,通常使用
: cell输入和cell输出激活函数,通常使用
 : 映射输出的激活函数,通常用
: 映射输出的激活函数,通常用 或等同的
或等同的
将 use_peepholes 设置为False,断开窥视孔连接(peephole connection)。在此省略公式,详情请参照论文 LONG SHORT-TERM MEMORY 。
注意输入
 中的
中的 不在此操作符中。用户选择在LSTMP层之前使用全链接层。
不在此操作符中。用户选择在LSTMP层之前使用全链接层。
- 参数:
input (Variable) - dynamic_lstmp层的输入,支持输入序列长度为变量的倍数。该变量的张量为一个矩阵,维度为(T X 4D),T为mini-batch的总时间步长,D是隐藏大小。
size (int) - 4*隐藏状态大小(hidden size)
proj_size (int) - 投影输出的大小
param_attr (ParamAttr|None) - 可学习hidden-hidden权重和投影权重的参数属性。说明:
- Hidden-hidden (隐藏状态到隐藏状态)权重 =
- hidden-hidden权重的权重矩阵为(P4D),P是投影大小,D是隐藏大小。
- 投影(Projection)权重 =
- 投影权重的shape为(DP)


如果设为None或者ParamAttr的一个属性,dynamic_lstm将创建ParamAttr为param_attr。如果param_attr的初始函数未设置,参数则初始化为Xavier。默认:None。
bias_attr (ParamAttr|None) - 可学习bias权重的bias属性,包含输入隐藏的bias权重和窥视孔连接权重(peephole connection),前提是use_peepholes设为True。
- 说明:
- 1.use_peepholes = False
- Biases = {
 }.
}. - 维度为(1*4D)
- Biases = {
- 2.use_peepholes = True
- Biases = {
 }
} - 维度为(1*7D)如果设置为None或者ParamAttr的一个属性,dynamic_lstm将创建ParamAttr为bias_attr。bias_attr的初始函数未设置,bias则初始化为0.默认:None。
- Biases = {
use_peepholes (bool) - 是否开启诊断/窥视孔链接,默认为True。
is_reverse (bool) - 是否计算反向LSTM,默认为False。
gate_activation (bool) - 输入门(input gate)、遗忘门(forget gate)和输出门(output gate)的激活函数。Choices = [“sigmoid”,“tanh”,“relu”,“identity”],默认“sigmoid”。
cell_activation (str) - cell输出的激活函数。Choices = [“sigmoid”,“tanh”,“relu”,“identity”],默认“tanh”。
candidate_activation (str) - 候选隐藏状态(candidate hidden state)的激活状态。Choices = [“sigmoid”,“tanh”,“relu”,“identity”],默认“tanh”。
proj_activation (str) - 投影输出的激活函数。Choices = [“sigmoid”,“tanh”,“relu”,“identity”],默认“tanh”。
dtype (str) - 数据类型。Choices = [“float32”,“float64”],默认“float32”。
name (str|None) - 该层名称(可选)。若设为None,则自动为该层命名。
h_0 (Variable) - 初始隐藏状态是可选输入,默认为0。这是一个具有形状的张量(N x D),其中N是批大小,D是投影大小。
c_0 (Variable) - 初始cell状态是可选输入,默认为0。这是一个具有形状(N x D)的张量,其中N是批大小。h_0和c_0可以为空,但只能同时为空。
cell_clip (float) - 如果提供该参数,则在单元输出激活之前,单元状态将被此值剪裁。
proj_clip (float) - 如果 num_proj > 0 并且 proj_clip 被提供,那么将投影值沿元素方向剪切到[-proj_clip,proj_clip]内
返回:含有两个输出变量的元组,隐藏状态(hidden state)的投影和LSTMP的cell状态。投影的shape为(TP),cell state的shape为(TD),两者的LoD和输入相同。
返回类型:元组(tuple)
代码示例:
- import paddle.fluid as fluid
- dict_dim, emb_dim = 128, 64
- data = fluid.layers.data(name='sequence', shape=[1],
- dtype='int32', lod_level=1)
- emb = fluid.layers.embedding(input=data, size=[dict_dim, emb_dim])
- hidden_dim, proj_dim = 512, 256
- fc_out = fluid.layers.fc(input=emb, size=hidden_dim * 4,
- act=None, bias_attr=None)
- proj_out, _ = fluid.layers.dynamic_lstmp(input=fc_out,
- size=hidden_dim * 4,
- proj_size=proj_dim,
- use_peepholes=False,
- is_reverse=True,
- cell_activation="tanh",
- proj_activation="tanh")
edit_distance
paddle.fluid.layers.editdistance(_input, label, normalized=True, ignored_tokens=None)- 编辑距离算子
计算一批给定字符串及其参照字符串间的编辑距离。编辑距离也称Levenshtein距离,通过计算从一个字符串变成另一个字符串所需的最少操作步骤来衡量两个字符串的相异度。这里的操作包括插入、删除和替换。
比如给定假设字符串A=“kitten”和参照字符串B=“sitting”,从A变换成B编辑距离为3,至少需要两次替换和一次插入:
“kitten”->“sitten”->“sittn”->“sitting”
输入为LoDTensor,包含假设字符串(带有表示批尺寸的总数)和分离信息(具体为LoD信息)。并且批尺寸大小的参照字符串和输入LoDTensor的顺序保持一致。
输出包含批尺寸大小的结果,代表一对字符串中每个字符串的编辑距离。如果Attr(normalized)为真,编辑距离则处以参照字符串的长度。
- 参数:
- input (Variable)-假设字符串的索引
- label (Variable)-参照字符串的索引
- normalized (bool,默认为True)-表示是否用参照字符串的长度进行归一化
- ignored_tokens (list
,默认为None)-计算编辑距离前需要移除的token - name (str)-该层名称,可选返回:[batch_size,1]中序列到序列到编辑距离
返回类型:变量
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[1], dtype='int64')
- y = fluid.layers.data(name='y', shape=[1], dtype='int64')
- cost, _ = fluid.layers.edit_distance(input=x,label=y)
- cpu = fluid.core.CPUPlace()
- exe = fluid.Executor(cpu)
- exe.run(fluid.default_startup_program())
- import numpy
- x_ = numpy.random.randint(5, size=(2, 1)).astype('int64')
- y_ = numpy.random.randint(5, size=(2, 1)).astype('int64')
- print(x_)
- print(y_)
- x = fluid.create_lod_tensor(x_, [[2]], cpu)
- y = fluid.create_lod_tensor(y_, [[2]], cpu)
- outs = exe.run(feed={'x':x, 'y':y}, fetch_list=[cost.name])
- print(outs)
elementwise_add
paddle.fluid.layers.elementwiseadd(_x, y, axis=-1, act=None, name=None)- 逐元素相加算子
等式为:

 :任意维度的张量(Tensor).
:任意维度的张量(Tensor). :一个维度必须小于等于X维度的张量(Tensor)。
:一个维度必须小于等于X维度的张量(Tensor)。- 对于这个运算算子有2种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),则
的形状(shape),则 axis为 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入
 和
和 可以携带不同的LoD信息。但输出仅与输入
可以携带不同的LoD信息。但输出仅与输入 共享LoD信息。
共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_add(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_add(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_add(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_add(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_add(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_add(x5, y5, axis=0)
elementwise_div
paddle.fluid.layers.elementwisediv(_x, y, axis=-1, act=None, name=None)- 逐元素相除算子
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入
 和
和 可以携带不同的LoD信息。但输出仅与输入
可以携带不同的LoD信息。但输出仅与输入 共享LoD信息。
共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_div(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_div(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_div(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_div(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_div(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_div(x5, y5, axis=0)
elementwise_floordiv
paddle.fluid.layers.elementwisefloordiv(_x, y, axis=-1, act=None, name=None)- FloorDiv运算。
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算分两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入
 和
和 可以携带不同的LoD信息。但输出仅与输入
可以携带不同的LoD信息。但输出仅与输入 共享LoD信息。
共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # example 1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_floordiv(x0, y0)
- # example 2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_floordiv(x1, y1)
- # example 3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_floordiv(x2, y2, axis=2)
- # example 4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_floordiv(x3, y3, axis=1)
- # example 5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_floordiv(x4, y4, axis=0)
- # example 6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_floordiv(x5, y5, axis=0)
elementwise_max
paddle.fluid.layers.elementwisemax(_x, y, axis=-1, act=None, name=None)- 最大元素算子
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入X和Y可以携带不同的LoD信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_max(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_max(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_max(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_max(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_max(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_max(x5, y5, axis=0)
elementwise_min
paddle.fluid.layers.elementwisemin(_x, y, axis=-1, act=None, name=None)- 最小元素算子
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾部维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入X和Y可以携带不同的LoD信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_min(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_min(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_min(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_min(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_min(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_min(x5, y5, axis=0)
elementwise_mod
paddle.fluid.layers.elementwisemod(_x, y, axis=-1, act=None, name=None)- 按元素的取模运算。
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入X和Y可以携带不同的LoD信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # example 1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_mod(x0, y0)
- # example 2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_mod(x1, y1)
- # example 3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_mod(x2, y2, axis=2)
- # example 4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_mod(x3, y3, axis=1)
- # example 5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_mod(x4, y4, axis=0)
- # example 6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_mod(x5, y5, axis=0)
elementwise_mul
paddle.fluid.layers.elementwisemul(_x, y, axis=-1, act=None, name=None)- 逐元素相乘算子
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入X和Y可以携带不同的LoD信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_mul(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_mul(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_mul(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_mul(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_mul(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_mul(x5, y5, axis=0)
elementwise_pow
paddle.fluid.layers.elementwisepow(_x, y, axis=-1, act=None, name=None)- 逐元素幂运算算子
等式是:

 :任何维度的张量(Tensor)。
:任何维度的张量(Tensor)。 :维度必须小于或等于X维度的张量(Tensor)。
:维度必须小于或等于X维度的张量(Tensor)。- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。代码示例
的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。代码示例
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入X和Y可以携带不同的LoD信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- import paddle.fluid as fluid
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_pow(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- import paddle.fluid as fluid
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_pow(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- import paddle.fluid as fluid
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_pow(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- import paddle.fluid as fluid
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_pow(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- import paddle.fluid as fluid
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_pow(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- import paddle.fluid as fluid
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_pow(x5, y5, axis=0)
elementwise_sub
paddle.fluid.layers.elementwisesub(_x, y, axis=-1, act=None, name=None)- 逐元素相减算子
等式是:

- X :任何维度的张量(Tensor)。
- Y :维度必须小于或等于X维度的张量(Tensor)。
- 此运算算子有两种情况:
 的形状(shape)与
的形状(shape)与 相同。
相同。 的形状(shape)是
的形状(shape)是 的连续子序列。
的连续子序列。
- 对于情况2:
- 用
 匹配
匹配 的形状(shape),其中
的形状(shape),其中 axis将是 传到
传到 上的起始维度索引。
上的起始维度索引。 - 如果
axis为-1(默认值),则 。
。 - 考虑到子序列,
 的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
的大小为1的尾随维度将被忽略,例如shape(Y)=(2,1)=>(2)。例如:
- 用
- shape(X) = (2, 3, 4, 5), shape(Y) = (,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (5,)
- shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
输入X和Y可以携带不同的LoD信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Tensor)- 第一个输入张量(Tensor)。
- y (Tensor)- 第二个输入张量(Tensor)。
- axis (INT)- (int,默认-1)。将Y传到X上的起始维度索引。
- act (basestring | None)- 激活函数名称,应用于输出。
- name (basestring | None)- 输出的名称。返回: 元素运算的输出。
代码示例
- import paddle.fluid as fluid
- # 例1: shape(x) = (2, 3, 4, 5), shape(y) = (2, 3, 4, 5)
- x0 = fluid.layers.data(name="x0", shape=[2, 3, 4, 5], dtype='float32')
- y0 = fluid.layers.data(name="y0", shape=[2, 3, 4, 5], dtype='float32')
- z0 = fluid.layers.elementwise_sub(x0, y0)
- # 例2: shape(X) = (2, 3, 4, 5), shape(Y) = (5)
- x1 = fluid.layers.data(name="x1", shape=[2, 3, 4, 5], dtype='float32')
- y1 = fluid.layers.data(name="y1", shape=[5], dtype='float32')
- z1 = fluid.layers.elementwise_sub(x1, y1)
- # 例3: shape(X) = (2, 3, 4, 5), shape(Y) = (4, 5), with axis=-1(default) or axis=2
- x2 = fluid.layers.data(name="x2", shape=[2, 3, 4, 5], dtype='float32')
- y2 = fluid.layers.data(name="y2", shape=[4, 5], dtype='float32')
- z2 = fluid.layers.elementwise_sub(x2, y2, axis=2)
- # 例4: shape(X) = (2, 3, 4, 5), shape(Y) = (3, 4), with axis=1
- x3 = fluid.layers.data(name="x3", shape=[2, 3, 4, 5], dtype='float32')
- y3 = fluid.layers.data(name="y3", shape=[3, 4], dtype='float32')
- z3 = fluid.layers.elementwise_sub(x3, y3, axis=1)
- # 例5: shape(X) = (2, 3, 4, 5), shape(Y) = (2), with axis=0
- x4 = fluid.layers.data(name="x4", shape=[2, 3, 4, 5], dtype='float32')
- y4 = fluid.layers.data(name="y4", shape=[2], dtype='float32')
- z4 = fluid.layers.elementwise_sub(x4, y4, axis=0)
- # 例6: shape(X) = (2, 3, 4, 5), shape(Y) = (2, 1), with axis=0
- x5 = fluid.layers.data(name="x5", shape=[2, 3, 4, 5], dtype='float32')
- y5 = fluid.layers.data(name="y5", shape=[2], dtype='float32')
- z5 = fluid.layers.elementwise_sub(x5, y5, axis=0)
elu
paddle.fluid.layers.elu(x, alpha=1.0, name=None)- ELU激活层(ELU Activation Operator)
根据 https://arxiv.org/abs/1511.07289 对输入张量中每个元素应用以下计算。

- 参数:
- x(Variable)- ELU operator的输入
- alpha(FAOAT|1.0)- ELU的alpha值
- name (str|None) -这个层的名称(可选)。如果设置为None,该层将被自动命名。返回: ELU操作符的输出
返回类型: 输出(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3,10,32,32], dtype="float32")
- y = fluid.layers.elu(x, alpha=0.2)
embedding
paddle.fluid.layers.embedding(input, size, is_sparse=False, is_distributed=False, padding_idx=None, param_attr=None, dtype='float32')- 嵌入层(Embedding Layer)
该层用于查找由输入提供的id在查找表中的嵌入矩阵。查找的结果是input里每个ID对应的嵌入矩阵。所有的输入变量都作为局部变量传入LayerHelper构造器
- 参数:
- input (Variable)-包含IDs的张量
- size (tuple|list)-查找表参数的维度。应当有两个参数,一个代表嵌入矩阵字典的大小,一个代表每个嵌入向量的大小。
- is_sparse (bool)-代表是否用稀疏更新的标志
- is_distributed (bool)-是否从远程参数服务端运行查找表
- padding_idx (int|long|None)-如果为
None,对查找结果无影响。如果padding_idx不为空,表示一旦查找表中找到input中对应的padding_idz,则用0填充输出结果。如果 ,在查找表中使用的
,在查找表中使用的 padding_idx值为 。
。 - param_attr (ParamAttr)-该层参数
- dtype (np.dtype|core.VarDesc.VarType|str)-数据类型:float32,float_16,int等。返回:张量,存储已有输入的嵌入矩阵。
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name='sequence', shape=[1], dtype='int64', lod_level=1)
- emb = fluid.layers.embedding(input=data, size=[128, 64])
expand
paddle.fluid.layers.expand(x, expand_times, name=None)- expand运算会按给定的次数对输入各维度进行复制(tile)运算。 您应该通过提供属性
expand_times来为每个维度设置次数。 X的秩应该在[1,6]中。请注意,expand_times的大小必须与X的秩相同。以下是一个用例:
- 输入(X) 是一个形状为[2, 3, 1]的三维张量(Tensor):
- [
- [[1], [2], [3]],
- [[4], [5], [6]]
- ]
- 属性(expand_times): [1, 2, 2]
- 输出(Out) 是一个形状为[2, 6, 2]的三维张量(Tensor):
- [
- [[1, 1], [2, 2], [3, 3], [1, 1], [2, 2], [3, 3]],
- [[4, 4], [5, 5], [6, 6], [4, 4], [5, 5], [6, 6]]
- ]
- 参数:
- x (Variable)- 一个秩在[1, 6]范围中的张量(Tensor).
- expand_times (list|tuple) - 每一个维度要扩展的次数.返回: expand变量是LoDTensor。expand运算后,输出(Out)的每个维度的大小等于输入(X)的相应维度的大小乘以
expand_times给出的相应值。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[10], dtype='float32')
- out = fluid.layers.expand(x=x, expand_times=[1, 2, 2])
fc
paddle.fluid.layers.fc(input, size, num_flatten_dims=1, param_attr=None, bias_attr=None, act=None, is_test=False, name=None)- 全连接层
该函数在神经网络中建立一个全连接层。 它可以将一个或多个tensor( input 可以是一个list或者Variable,详见参数说明)作为自己的输入,并为每个输入的tensor创立一个变量,称为“权”(weights),等价于一个从每个输入单元到每个输出单元的全连接权矩阵。FC层用每个tensor和它对应的权相乘得到形状为[M, size]输出tensor,M是批大小。如果有多个输入tensor,那么形状为[M, size]的多个输出张量的结果将会被加起来。如果 bias_attr 非空,则会新创建一个偏向变量(bias variable),并把它加入到输出结果的运算中。最后,如果 act 非空,它也会加入最终输出的计算中。
当输入为单个张量:

当输入为多个张量:

- 上述等式中:
 :输入的数目,如果输入是变量列表,N等于len(input)
:输入的数目,如果输入是变量列表,N等于len(input) :第i个输入的tensor
:第i个输入的tensor :对应第i个输入张量的第i个权重矩阵
:对应第i个输入张量的第i个权重矩阵 :该层创立的bias参数
:该层创立的bias参数 :activation function(激励函数)
:activation function(激励函数) :输出tensor
:输出tensor
- Given:
- data_1.data = [[[0.1, 0.2],
- [0.3, 0.4]]]
- data_1.shape = (1, 2, 2) # 1 is batch_size
- data_2 = [[[0.1, 0.2, 0.3]]]
- data_2.shape = (1, 1, 3)
- out = fluid.layers.fc(input=[data_1, data_2], size=2)
- Then:
- out.data = [[0.18669507, 0.1893476]]
- out.shape = (1, 2)
- 参数:
- input (Variable|list of Variable) – 该层的输入tensor(s)(张量),其维度至少是2
- size (int) – 该层输出单元的数目
- num_flatten_dims (int, default 1) – fc层可以接受一个维度大于2的tensor。此时, 它首先会被扁平化(flattened)为一个二维矩阵。 参数
num_flatten_dims决定了输入tensor的flattened方式: 前num_flatten_dims(包含边界,从1开始数) 个维度会被扁平化为最终矩阵的第一维 (维度即为矩阵的高), 剩下的 rank(X) - num_flatten_dims 维被扁平化为最终矩阵的第二维 (即矩阵的宽)。 例如, 假设X是一个五维tensor,其形可描述为(2, 3, 4, 5, 6), 且num_flatten_dims = 3。那么扁平化的矩阵形状将会如此: (2 x 3 x 4, 5 x 6) = (24, 30) - param_attr (ParamAttr|list of ParamAttr, default None) – 该层可学习的参数/权的参数属性
- bias_attr (ParamAttr|list of ParamAttr, default None) – 该层bias变量的参数属性。如果值为False, 则bias变量不参与输出单元运算。 如果值为None,bias变量被初始化为0。默认为 None。
- act (str, default None) – 应用于输出的Activation(激励函数)
- is_test (bool) – 表明当前执行是否处于测试阶段的标志
- name (str, default None) – 该层的命名返回:转换结果
返回类型: Variable
弹出异常:ValueError - 如果输入tensor的维度小于2
代码示例
- import paddle.fluid as fluid
- # 当输入为单个张量时
- data = fluid.layers.data(name="data", shape=[32, 32], dtype="float32")
- fc = fluid.layers.fc(input=data, size=1000, act="tanh")
- # 当输入为多个张量时
- data_1 = fluid.layers.data(name="data_1", shape=[32, 32], dtype="float32")
- data_2 = fluid.layers.data(name="data_2", shape=[24, 36], dtype="float32")
- fc = fluid.layers.fc(input=[data_1, data_2], size=1000, act="tanh")
flatten
paddle.fluid.layers.flatten(x, axis=1, name=None)- 将输入张量压扁成二维矩阵
例如:
- Case 1:
- 给定
- X.shape = (3, 100, 100, 4)
- 且
- axis = 2
- 得到:
- Out.shape = (3 * 100, 4 * 100)
- Case 2:
- 给定
- X.shape = (3, 100, 100, 4)
- 且
- axis = 0
- 得到:
- Out.shape = (1, 3 * 100 * 100 * 4)
- 参数:
- x (Variable) - 一个秩>=axis 的张量
- axis (int) - flatten的划分轴,[0, axis) 轴数据被flatten到输出矩阵的0轴,[axis, R)被flatten到输出矩阵的1轴,其中R是输入张量的秩。axis的值必须在[0,R]范围内。当 axis= 0 时,输出张量的形状为 (1,d_0 d_1 … d_n) ,其输入张量的形状为(d_0, d_1,… d_n)。
- name (str|None) - 此层的名称(可选)。如果没有设置,层将自动命名。返回: 一个二维张量,它包含输入张量的内容,但维数发生变化。输入的[0, axis)维将沿给定轴flatten到输出的前一个维度,剩余的输入维数flatten到输出的后一个维度。
返回类型: Variable
- 抛出异常:
- ValueError: 如果 x 不是一个变量
- ValueError: 如果axis的范围不在 [0, rank(x)]代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[4, 4, 3], dtype="float32")
- out = fluid.layers.flatten(x=x, axis=2)
fsp_matrix
paddle.fluid.layers.fspmatrix(_x, y)- FSP matrix op
此运算用于计算两个特征映射的求解过程(FSP)矩阵。给定形状为[x_channel,h,w]的特征映射x和形状为[y_channel,h,w]的特征映射y,我们可以分两步得到x和y的fsp矩阵:
1.用形状[X_channel,HW]将X重塑为矩阵,并用形状[HW,y_channel]将Y重塑和转置为矩阵。
2.乘以x和y得到形状为[x_channel,y_channel]的fsp矩阵。
输出是一批fsp矩阵。
- 参数:
- x (Variable): 一个形状为[batch_size, x_channel, height, width]的特征映射
- y (Variable):具有形状[batch_size, y_channel, height, width]的特征映射。Y轴通道可以与输入(X)的X轴通道不同,而其他尺寸必须与输入(X)相同。返回:形状为[batch_size, x_channel, y_channel]的fsp op的输出。x_channel 是x的通道,y_channel是y的通道。
返回类型:fsp matrix (Variable)
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32])
- feature_map_0 = fluid.layers.conv2d(data, num_filters=2,
- filter_size=3)
- feature_map_1 = fluid.layers.conv2d(feature_map_0, num_filters=2,
- filter_size=1)
- loss = fluid.layers.fsp_matrix(feature_map_0, feature_map_1)
gather
paddle.fluid.layers.gather(input, index, overwrite=True)- 收集层(gather layer)
根据索引index获取X的最外层维度的条目,并将它们串连在一起。

- X = [[1, 2],
- [3, 4],
- [5, 6]]
- Index = [1, 2]
- Then:
- Out = [[3, 4],
- [5, 6]]
- 参数:
- input (Variable) - input的秩rank >= 1。
- index (Variable) - index的秩rank = 1。
- overwrite (bool) - 具有相同索引时更新grad的模式。如果为True,则使用覆盖模式更新相同索引的grad,如果为False,则使用accumulate模式更新相同索引的grad。Default值为True。返回:和输入的秩相同的输出张量。
返回类型:output (Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[-1, 5], dtype='float32')
- index = fluid.layers.data(name='index', shape=[-1, 1], dtype='int32')
- output = fluid.layers.gather(x, index)
gaussian_random
paddle.fluid.layers.gaussianrandom(_shape, mean=0.0, std=1.0, seed=0, dtype='float32')- gaussian_random算子。
用于使用高斯随机生成器初始化张量(Tensor)。
- 参数:
- shape (tuple | list)- (vector
)随机张量的维数 - mean (Float)- (默认值0.0)随机张量的均值
- std (Float)- (默认值为1.0)随机张量的std
- seed (Int)- (默认值为 0)生成器随机生成种子。0表示使用系统范围的种子。注意如果seed不为0,则此算子每次将始终生成相同的随机数
- dtype (np.dtype | core.VarDesc.VarType | str)- 输出的数据类型。返回: 输出高斯随机运算矩阵
- shape (tuple | list)- (vector
返回类型: 输出(Variable)
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- out = fluid.layers.gaussian_random(shape=[20, 30])
gaussian_random_batch_size_like
paddle.fluid.layers.gaussianrandom_batch_size_like(_input, shape, input_dim_idx=0, output_dim_idx=0, mean=0.0, std=1.0, seed=0, dtype='float32')用于使用高斯随机发生器初始化张量。分布的defalut均值为0.并且分布的defalut标准差(std)为1.用户可以通过输入参数设置mean和std。
参数:
- input (Variable)- 其input_dim_idx’th维度指定batch_size的张量(Tensor)。
- shape (元组|列表)- 输出的形状。
- input_dim_idx (Int)- 默认值0.输入批量大小维度的索引。
- output_dim_idx (Int)- 默认值0.输出批量大小维度的索引。
- mean (Float)- (默认值0.0)高斯分布的平均值(或中心值)。
- std (Float)- (默认值 1.0)高斯分布的标准差(std或spread)。
- seed (Int)- (默认为0)用于随机数引擎的随机种子。0表示使用系统生成的种子。请注意,如果seed不为0,则此算子将始终每次生成相同的随机数。
- dtype (np.dtype | core.VarDesc.VarType | str)- 输出数据的类型为float32,float_16,int等。返回: 指定形状的张量将使用指定值填充。
返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[13, 11], dtype='float32')
- out = fluid.layers.gaussian_random_batch_size_like(
- input, shape=[-1, 11], mean=1.0, std=2.0)
get_tensor_from_selected_rows
paddle.fluid.layers.gettensor_from_selected_rows(_x, name=None)Get Tensor From Selected Rows用于从选中行(Selected Rows)中获取张量参数:
- x (Variable) - 输入,类型是SelectedRows
- name (basestring|None) - 输出的名称返回: 输出类型为LoDTensor
返回类型: out(Variable)
代码示例:
- import paddle.fluid as fluid
- b = fluid.default_main_program().global_block()
- input = b.create_var(name="X", dtype="float32", persistable=True, type=fluid.core.VarDesc.VarType.SELECTED_ROWS)
- out = fluid.layers.get_tensor_from_selected_rows(input)
grid_sampler
paddle.fluid.layers.gridsampler(_x, grid, name=None)- 该操作使用基于flow field网格的双线性插值对输入X进行采样,通常由affine_grid生成。
形状为(N、H、W、2)的网格是由两个形状均为(N、H、W)的坐标(grid_x grid_y)连接而成的。
其中,grid_x是输入数据x的第四个维度(宽度维度)的索引,grid_y是第三维度(高维)的索引,最终得到4个最接近的角点的双线性插值值。
step 1:
得到(x, y)网格坐标,缩放到[0,h -1/W-1]
grid_x = 0.5 (grid[:, :, :, 0] + 1) (W - 1) grid_y = 0.5 (grid[:, :, :, 1] + 1) (H - 1)
step 2:
在每个[H, W]区域用网格(X, y)作为输入数据X的索引,并将双线性插值点值由4个最近的点表示。
- wn ------- y_n ------- en
- | | |
- | d_n |
- | | |
- x_w --d_w-- grid--d_e-- x_e
- | | |
- | d_s |
- | | |
- ws ------- y_s ------- wn
- x_w = floor(x) // west side x coord
- x_e = x_w + 1 // east side x coord
- y_n = floor(y) // north side y coord
- y_s = y_s + 1 // south side y coord
- d_w = grid_x - x_w // distance to west side
- d_e = x_e - grid_x // distance to east side
- d_n = grid_y - y_n // distance to north side
- d_s = y_s - grid_y // distance to south side
- wn = X[:, :, y_n, x_w] // north-west point value
- en = X[:, :, y_n, x_e] // north-east point value
- ws = X[:, :, y_s, x_w] // south-east point value
- es = X[:, :, y_s, x_w] // north-east point value
- output = wn * d_e * d_s + en * d_w * d_s
- + ws * d_e * d_n + es * d_w * d_n
- 参数:
- x (Variable): 输入数据,形状为[N, C, H, W]
- grid (Variable): 输入网格张量,形状为[N, H, W, 2]
- name (str, default None): 该层的名称返回: out (Variable): 输入X基于输入网格的bilnear插值计算结果,形状为[N, C, H, W]
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[3, 10, 32, 32], dtype='float32')
- theta = fluid.layers.data(name='theta', shape=[3, 2, 3], dtype='float32')
- grid = fluid.layers.affine_grid(theta=theta, out_shape=[3, 10, 32, 32]})
- out = fluid.layers.grid_sampler(x=x, grid=grid)
group_norm
paddle.fluid.layers.groupnorm(_input, groups, epsilon=1e-05, param_attr=None, bias_attr=None, act=None, data_layout='NCHW', name=None)参考论文: Group Normalization
参数:
- input (Variable):输入张量变量
- groups (int):从 channel 中分离出来的 group 的数目
- epsilon (float):为防止方差除零,增加一个很小的值
- param_attr (ParamAttr|None):可学习标度的参数属性
 ,如果设置为False,则不会向输出单元添加标度。如果设置为0,偏差初始化为1。默认值:None
,如果设置为False,则不会向输出单元添加标度。如果设置为0,偏差初始化为1。默认值:None - bias_attr (ParamAttr|None):可学习偏置的参数属性 :math:`b ` , 如果设置为False,则不会向输出单元添加偏置量。如果设置为零,偏置初始化为零。默认值:None。
- act (str):将激活应用于输出的 group normalizaiton
- data_layout (string|NCHW): 只支持NCHW。
- name (str):这一层的名称(可选)返回: Variable: 一个张量变量,它是对输入进行 group normalization 后的结果。
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[8, 32, 32],
- dtype='float32')
- x = fluid.layers.group_norm(input=data, groups=4)
gru_unit
paddle.fluid.layers.gruunit(_input, hidden, size, param_attr=None, bias_attr=None, activation='tanh', gate_activation='sigmoid', origin_mode=False)- GRU单元层。GRU执行步骤基于如下等式:
如果origin_mode为True,则该运算公式来自论文Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling 。
公式如下:




如果origin_mode为False,则该运算公式来自论文Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation 。

GRU单元的输入包括
 ,
, 。在上述等式中,
。在上述等式中, 会被分割成三部分:
会被分割成三部分: 、
、 和
和 。这意味着要为一批输入实现一个全GRU层,我们需要采用一个全连接层,才能得到
。这意味着要为一批输入实现一个全GRU层,我们需要采用一个全连接层,才能得到 。
。 和
和 分别代表了GRU神经元的update gates(更新门)和reset gates(重置门)。和LSTM不同,GRU少了一个门(它没有LSTM的forget gate)。但是它有一个叫做中间候选隐藏状态(intermediate candidate hidden output)的输出,记为
分别代表了GRU神经元的update gates(更新门)和reset gates(重置门)。和LSTM不同,GRU少了一个门(它没有LSTM的forget gate)。但是它有一个叫做中间候选隐藏状态(intermediate candidate hidden output)的输出,记为 。 该层有三个输出:
。 该层有三个输出: 以及
以及 的连结(concatenation)。
的连结(concatenation)。
- 参数:
input (Variable) – 经FC层变换后的当前步骤的输入值
hidden (Variable) – 从上一步而来的gru unit 隐藏状态值(hidden value)
size (integer) – 输入数据的维度
param_attr (ParamAttr|None) – 可学习的隐藏层权重矩阵的参数属性。注意:
- 该权重矩阵形为
,是隐藏状态的规模(hidden size)- 该权重矩阵的所有元素由两部分组成, 一是update gate和reset gate的权重,形为
;二是候选隐藏状态(candidate hidden state)的权重矩阵,形为




如果该函数参数值为None或者 ParamAttr 类中的属性之一,gru_unit则会创建一个 ParamAttr 类的对象作为 param_attr。如果param_attr没有被初始化,那么会由Xavier来初始化它。默认值为None
- bias_attr (ParamAttr|bool|None) - GRU的bias变量的参数属性。形为
 的bias连结(concatenate)在update gates(更新门),reset gates(重置门)以及candidate calculations(候选隐藏状态计算)中的bias。如果值为False,那么上述三者将没有bias参与运算。若值为None或者
的bias连结(concatenate)在update gates(更新门),reset gates(重置门)以及candidate calculations(候选隐藏状态计算)中的bias。如果值为False,那么上述三者将没有bias参与运算。若值为None或者 ParamAttr 类中的属性之一,gru_unit则会创建一个 ParamAttr 类的对象作为 bias_attr。如果bias_attr没有被初始化,那它会被默认初始化为0。默认值为None。
activation (string) – 神经元 “actNode” 的激励函数(activation)类型。默认类型为‘tanh’
gate_activation (string) – 门 “actGate” 的激励函数(activation)类型。 默认类型为 ‘sigmoid’
返回: hidden value(隐藏状态的值),reset-hidden value(重置隐藏状态值),gate values(门值)
返回类型: 元组(tuple)
代码示例
- import paddle.fluid as fluid
- dict_dim, emb_dim = 128, 64
- data = fluid.layers.data(name='step_data', shape=[1], dtype='int32')
- emb = fluid.layers.embedding(input=data, size=[dict_dim, emb_dim])
- hidden_dim = 512
- x = fluid.layers.fc(input=emb, size=hidden_dim * 3)
- pre_hidden = fluid.layers.data(
- name='pre_hidden', shape=[hidden_dim], dtype='float32')
- hidden = fluid.layers.gru_unit(
- input=x, hidden=pre_hidden, size=hidden_dim * 3)
hard_sigmoid
paddle.fluid.layers.hardsigmoid(_x, slope=0.2, offset=0.5, name=None)- HardSigmoid激活算子。
sigmoid的分段线性逼近(https://arxiv.org/abs/1603.00391),比sigmoid快得多。

斜率是正数。偏移量可正可负的。斜率和位移的默认值是根据上面的参考设置的。建议使用默认值。
- 参数:
- x (Variable) - HardSigmoid operator的输入
- slope (FLOAT|0.2) -斜率
- offset (FLOAT|0.5) - 偏移量
- name (str|None) - 这个层的名称(可选)。如果设置为None,该层将被自动命名。代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3,10,32,32], dtype="float32")
- y = fluid.layers.hard_sigmoid(x, slope=0.3, offset=0.8)
hash
paddle.fluid.layers.hash(input, hash_size, num_hash=1, name=None)- 将输入 hash 到一个整数,该数的值小于给定的 hash size
我们使用的哈希算法是 xxHash - Extremely fast hash algorithm
提供一简单的例子:
- 给出:
- # shape [2, 2]
- input.data = [
- [[1, 2],
- [3, 4]],
- ]
- input.lod = [[0, 2]]
- hash_size = 10000
- num_hash = 4
- 然后:
- 哈希操作将这个二维input的所有数字作为哈希算法每次的输入。
- 每个输入都将被哈希4次,最终得到一个长度为4的数组。
- 数组中的每个值的范围从0到9999。
- # shape [2, 4]
- output.data = [
- [[9662, 9217, 1129, 8487],
- [8310, 1327, 1654, 4567]],
- ]
- output.lod = [[0, 2]]
- 参数:
- input (Variable) - 输入变量是一个 one-hot 词。输入变量的维数必须是2。
- hash_size (int) - 哈希算法的空间大小。输出值将保持在
 范围内。
范围内。 - num_hash (int) - 哈希次数,默认为1。
- name (str, default None) - 该层的名称返回:哈希的结果变量,是一个lodtensor。
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- import numpy as np
- titles = fluid.layers.data(name='titles', shape=[1], dtype='int32', lod_level=1)
- hash_r = fluid.layers.hash(name='hash_x', input=titles, num_hash=1, hash_size=1000)
- place = fluid.core.CPUPlace()
- exece = fluid.Executor(place)
- exece.run(fluid.default_startup_program())
- # 初始化Tensor
- tensor = fluid.core.LoDTensor()
- tensor.set(np.random.randint(0, 10, (3, 1)).astype("int32"), place)
- # 设置LoD
- tensor.set_recursive_sequence_lengths([[1, 1, 1]])
- out = exece.run(feed={'titles': tensor}, fetch_list=[hash_r], return_numpy=False)
hsigmoid
paddle.fluid.layers.hsigmoid(input, label, num_classes, param_attr=None, bias_attr=None, name=None, path_table=None, path_code=None, is_custom=False, is_sparse=False)- 层次sigmod( hierarchical sigmoid )加速语言模型的训练过程。这个operator将类别组织成一个完全二叉树,也可以使用
is_custom参数来传入自定义的树结构来实现层次化。
树中每个叶节点表示一个类(一个单词),每个内部节点进行一个二分类。对于每个单词,都有一个从根到它的叶子节点的唯一路径,hsigmoid计算路径上每个内部节点的损失(cost),并将它们相加得到总损失(cost)。
hsigmoid可以把时间复杂度
 优化到
优化到 ,其中
,其中 表示单词字典的大小。
表示单词字典的大小。
使用默认树结构,请参考 Hierarchical Probabilistic Neural Network Language Model 。
若要使用自定义树结构,请设置 is_custom 值为True。但在此之前,请完成以下几步:
1.使用自定义词典来建立二叉树,每个叶结点都应该是词典中的单词
2.建立一个dict类型数据结构,来存储 单词id -> 该单词叶结点至根结点路径 的映射,称之为路径表 path_table 参数
3.建立一个dict类型数据结构,来存储 单词id -> 该单词叶结点至根结点路径的编码(code) 的映射。 编码code是指每次二分类的标签,1为真,0为假
4.现在我们的每个单词都已经有自己的路径和路径编码,当对于同一批输入进行操作时,你可以同时传入一批路径和路径编码进行运算。
- 参数:
- input (Variable) - 输入张量,shape为
[N×D],其中N是minibatch的大小,D是特征大小。 - label (Variable) - 训练数据的标签。该tensor的shape为
[N×1] - num_classes (int) - 类别的数量不能少于2。若使用默认树结构,该参数必须用户设置。当
is_custom=False时,该项绝不能为None。反之,如果is_custom=True,它取值应为非叶节点的个数,来指明二分类实用的类别数目。 - param_attr (ParamAttr|None) - 可学习参数/ hsigmoid权重的参数属性。如果将其设置为ParamAttr的一个属性或None,则将ParamAttr设置为param_attr。如果没有设置param_attr的初始化器,那么使用用Xavier初始化。默认值:没None。
- bias_attr (ParamAttr|bool|None) - hsigmoid偏置的参数属性。如果设置为False,则不会向输出添加偏置。如果将其设置ParamAttr的一个属性或None,则将ParamAttr设置为bias_attr。如果没有设置bias_attr的初始化器,偏置将初始化为零。默认值:None。
- name (str|None) - 该layer的名称(可选)。如果设置为None,该层将被自动命名。默认值:None。
- path_table (Variable|None) – 存储每一批样本从词到根节点的路径。路径应为从叶至根方向。
path_table和path_code应具有相同的形, 对于每个样本 i ,path_table[i]为一个类似np.array的结构,该数组内的每个元素都是其双亲结点权重矩阵的索引 - path_code (Variable|None) – 存储每批样本的路径编码,仍然是按从叶至根方向。各样本路径编码批都由其各祖先结点的路径编码组成
- is_custom (bool|False) – 使用用户自定义二叉树取代默认二叉树结构,如果该项为真, 请务必设置
path_table,path_code,num_classes, 否则就需要设置 num_classes - is_sparse (bool|False) – 使用稀疏更新方式,而非密集更新。如果为真, W的梯度和输入梯度将会变得稀疏返回: (LoDTensor) 层次sigmod( hierarchical sigmoid) 。shape[N, 1]
- input (Variable) - 输入张量,shape为
返回类型: Out
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[2], dtype='float32')
- y = fluid.layers.data(name='y', shape=[1], dtype='int64')
- out = fluid.layers.hsigmoid(input=x, label=y, num_classes=6)
huber_loss
paddle.fluid.layers.huberloss(_input, label, delta)- Huber损失是更具鲁棒性的损失函数。 huber损失可以评估输入对标签的合适度。 与MSE损失不同,Huber损失可更为稳健地处理异常值。
当输入和标签之间的距离大于delta时:

当输入和标签之间的距离小于delta时:

- 参数:
- input (Variable) - 此输入是前一个算子计算得到的概率。 第一个维度是批大小batch_size,最后一个维度是1。
- label (Variable) - 第一个维度为批量大小batch_size且最后一个维度为1的真实值
- delta (float) - huber loss的参数,用于控制异常值的范围返回: 形为[batch_size, 1]的huber loss.
返回类型: huber_loss (Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[13], dtype='float32')
- predict = fluid.layers.fc(input=x, size=1)
- label = fluid.layers.data(
- name='label', shape=[1], dtype='float32')
- loss = fluid.layers.huber_loss(
- input=predict, label=label, delta=1.0)
im2sequence
paddle.fluid.layers.im2sequence(input, filter_size=1, stride=1, padding=0, input_image_size=None, out_stride=1, name=None)- 从输入张量中提取图像张量,与im2col相似,shape={input.batch_size output_height output_width, filter_size_H filter_size_W input.通道}。这个op使用filter / kernel扫描图像并将这些图像转换成序列。一个图片展开后的timestep的个数为output_height * output_width,其中output_height和output_width由下式计算:

每个timestep的维度为
 。
。
- 参数:
- input (Variable)- 输入张量,格式为[N, C, H, W]
- filter_size (int|tuple|None) - 滤波器大小。如果filter_size是一个tuple,它必须包含两个整数(filter_size_H, filter_size_W)。否则,过滤器将是一个方阵。
- stride (int|tuple) - 步长大小。如果stride是一个元组,它必须包含两个整数(stride_H、stride_W)。否则,stride_H = stride_W = stride。默认:stride = 1。
- padding (int|tuple) - 填充大小。如果padding是一个元组,它可以包含两个整数(padding_H, padding_W),这意味着padding_up = padding_down = padding_H和padding_left = padding_right = padding_W。或者它可以使用(padding_up, padding_left, padding_down, padding_right)来指示四个方向的填充。否则,标量填充意味着padding_up = padding_down = padding_left = padding_right = padding Default: padding = 0。
- input_image_size (Variable) - 输入包含图像的实际大小。它的维度为[batchsize,2]。该参数可有可无,是用于batch上的预测。
- out_stride (int|tuple) - 通过CNN缩放图像。它可有可无,只有当input_image_size不为空时才有效。如果out_stride是tuple,它必须包含(out_stride_H, out_stride_W),否则,out_stride_H = out_stride_W = out_stride。
- name (int) - 该layer的名称,可以忽略。返回: LoDTensor shape为{batch_size output_height output_width, filter_size_H filter_size_W input.channels}。如果将输出看作一个矩阵,这个矩阵的每一行都是一个序列的step。
返回类型: output
- Given:
- x = [[[[ 6. 2. 1.]
- [ 8. 3. 5.]
- [ 0. 2. 6.]]
- [[ 2. 4. 4.]
- [ 6. 3. 0.]
- [ 6. 4. 7.]]]
- [[[ 6. 7. 1.]
- [ 5. 7. 9.]
- [ 2. 4. 8.]]
- [[ 1. 2. 1.]
- [ 1. 3. 5.]
- [ 9. 0. 8.]]]]
- x.dims = {2, 2, 3, 3}
- And:
- filter = [2, 2]
- stride = [1, 1]
- padding = [0, 0]
- Then:
- output.data = [[ 6. 2. 8. 3. 2. 4. 6. 3.]
- [ 2. 1. 3. 5. 4. 4. 3. 0.]
- [ 8. 3. 0. 2. 6. 3. 6. 4.]
- [ 3. 5. 2. 6. 3. 0. 4. 7.]
- [ 6. 7. 5. 7. 1. 2. 1. 3.]
- [ 7. 1. 7. 9. 2. 1. 3. 5.]
- [ 5. 7. 2. 4. 1. 3. 9. 0.]
- [ 7. 9. 4. 8. 3. 5. 0. 8.]]
- output.dims = {8, 8}
- output.lod = [[4, 4]]
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32],
- dtype='float32')
- output = fluid.layers.im2sequence(
- input=data, stride=[1, 1], filter_size=[2, 2])
image_resize
paddle.fluid.layers.imageresize(_input, out_shape=None, scale=None, name=None, resample='BILINEAR', actual_shape=None, align_corners=True, align_mode=1)- 调整一个batch中图片的大小。
输入张量的shape为(num_batch, channels, in_h, in_w),并且调整大小只适用于最后两个维度(高度和宽度)。
支持重新取样方法:
BILINEAR:双线性插值
NEAREST:最近邻插值
最近邻插值是在输入张量的第3维(高度)和第4维(宽度)上进行最近邻插值。
双线性插值是线性插值的扩展,用于在直线2D网格上插值两个变量(例如,该操作中的H方向和W方向)的函数。 关键思想是首先在一个方向上执行线性插值,然后在另一个方向上再次执行线性插值。
Align_corners和align_mode是可选参数,插值的计算方法可以由它们选择。
示例:
- For scale:
- if align_corners = True && out_size > 1 :
- scale_factor = (in_size-1.0)/(out_size-1.0)
- else:
- scale_factor = float(in_size/out_size)
- Nearest neighbor interpolation:
- if:
- align_corners = False
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = \left \lfloor {H_{in} * scale_{}factor}} \right \rfloor
- W_out = \left \lfloor {W_{in} * scale_{}factor}} \right \rfloor
- else:
- align_corners = True
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = round(H_{in} * scale_{factor})
- W_out = round(W_{in} * scale_{factor})
- Bilinear interpolation:
- if:
- align_corners = False , align_mode = 0
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = (H_{in}+0.5) * scale_{factor} - 0.5
- W_out = (W_{in}+0.5) * scale_{factor} - 0.5
- else:
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = H_{in} * scale_{factor}
- W_out = W_{in} * scale_{factor}
有关最近邻插值的详细信息,请参阅维基百科:https://en.wikipedia.org/wiki/Nearest-neighbor_interpolation。
有关双线性插值的详细信息,请参阅维基百科:https://en.wikipedia.org/wiki/Bilinear_interpolation。
- 参数:
- input (Variable) - 图片调整层的输入张量,这是一个shape=4的张量(num_batch, channels, in_h, in_w)
- out_shape (list|tuple|Variable|None) - 图片调整层的输出,shape为(out_h, out_w)。默认值:None
- scale (float|None)-输入的高度或宽度的乘数因子 。 out_shape和scale至少要设置一个。out_shape的优先级高于scale。默认值:None
- name (str|None) - 该层的名称(可选)。如果设置为None,该层将被自动命名
- resample (str) - 重采样方法。目前只支持“双线性”。默认值:双线性插值
- actual_shape (Variable) - 可选输入,用于动态指定输出形状。如果指定actual_shape,图像将根据给定的形状调整大小,而不是根据指定形状的
out_shape和scale进行调整。也就是说,actual_shape具有最高的优先级。如果希望动态指定输出形状,建议使用actual_shape而不是out_shape。在使用actual_shape指定输出形状时,还需要设置out_shape和scale之一,否则在图形构建阶段会出现错误。默认值:None - align_corners (bool)- 一个可选的bool型参数,如果为True,则将输入和输出张量的4个角落像素的中心对齐,并保留角点像素的值。 默认值:True
- align_mode (int)- 双线性插值的可选项。 可以是 ‘0’ 代表src_idx = scale *(dst_indx + 0.5)-0.5;可以为‘1’ ,代表src_idx = scale * dst_index。返回: 4维tensor,shape为 (num_batches, channls, out_h, out_w).
返回类型: 变量(variable)
- 抛出异常:
TypeError- out_shape应该是一个列表、元组或变量。TypeError- actual_shape应该是变量或None。ValueError- image_resize的”resample”只能是”BILINEAR”或”NEAREST”。ValueError- out_shape 和 scale 不可同时为 None。ValueError- out_shape 的长度必须为 2。ValueError- scale应大于0。TypeError- align_corners 应为bool型。ValueError- align_mode 只能取 ‘0’ 或 ‘1’。代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[3,6,9], dtype="float32")
- out = fluid.layers.image_resize(input, out_shape=[12, 12], resample="NEAREST")
image_resize_short
paddle.fluid.layers.imageresize_short(_input, out_short_len, resample='BILINEAR')调整一批图片的大小。输入图像的短边将被调整为给定的out_short_len 。输入图像的长边按比例调整大小,最终图像的长宽比保持不变。
参数:
- input (Variable) - 图像调整图层的输入张量,这是一个4维的形状张量(num_batch, channels, in_h, in_w)。
- out_short_len (int) - 输出图像的短边长度。
- resample (str) - resample方法,默认为双线性插值。返回: 4维张量,shape为(num_batch, channls, out_h, out_w)
返回类型: 变量(variable)
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[3,6,9], dtype="float32")
- out = fluid.layers.image_resize_short(input, out_short_len=3)
kldiv_loss
paddle.fluid.layers.kldivloss(_x, target, reduction='mean', name=None)- 此运算符计算输入(x)和输入(Target)之间的Kullback-Leibler发散损失。
kL发散损失计算如下:

 为输入(x),
为输入(x), 输入(Target)。
输入(Target)。
当 reduction 为 none 时,输出损失与输入(x)形状相同,各点的损失单独计算,不应用reduction 。
当 reduction 为 mean 时,输出损失为[1]的形状,损失值为所有损失的平均值。
当 reduction 为 sum 时,输出损失为[1]的形状,损失值为所有损失的总和。
当 reduction 为 batchmean 时,输出损失为[1]的形状,损失值为所有损失的总和除以批量大小。
- 参数:
- x (Variable) - KL发散损失算子的输入张量。这是一个形状为[N, ]的张量,其中N是批大小,表示任何数量的附加维度
- target (Variable) - KL发散损失算子的张量。这是一个具有输入(x)形状的张量
- reduction (Variable)-要应用于输出的reduction类型,可用类型为‘none’ | ‘batchmean’ | ‘mean’ | ‘sum’,‘none’表示无reduction,‘batchmean’ 表示输出的总和除以批大小,‘mean’ 表示所有输出的平均值,‘sum’表示输出的总和。
- name (str, default None) - 该层的名称返回:KL发散损失
返回类型:kldiv_loss (Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[4,2,2], dtype='float32')
- target = fluid.layers.data(name='target', shape=[4,2,2], dtype='float32')
- loss = fluid.layers.kldiv_loss(x=x, target=target, reduction='batchmean')
l2_normalize
paddle.fluid.layers.l2normalize(_x, axis, epsilon=1e-12, name=None)- L2正则(L2 normalize Layer)
该层用欧几里得距离之和对维轴的x归一化。对于1-D张量(系数矩阵的维度固定为0),该层计算公式如下:

对于x多维的情况,该函数分别对维度轴上的每个1-D切片单独归一化
- 参数:
- x (Variable|list)- l2正则层(l2_normalize layer)的输入
- axis (int)-运用归一化的轴。如果轴小于0,归一化的维是rank(X)+axis。-1是最后维
- epsilon (float)-epsilon用于避免分母为0,默认值为1e-12
- name (str|None)-该层名称(可选)。如果设为空,则自动为该层命名返回:输出张量,同x的维度一致
返回类型:变量
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name="data",
- shape=(3, 17, 13),
- dtype="float32")
- normed = fluid.layers.l2_normalize(x=data, axis=1)
label_smooth
paddle.fluid.layers.labelsmooth(_label, prior_dist=None, epsilon=0.1, dtype='float32', name=None)- 标签平滑是一种对分类器层进行正则化的机制,称为标签平滑正则化(LSR)。
由于直接优化正确标签的对数似然可能会导致过拟合,降低模型的适应能力,因此提出了标签平滑的方法来降低模型置信度。标签平滑使用标签
 自身和一些固定模式随机分布变量
自身和一些固定模式随机分布变量 。对
。对 标签,我们有:
标签,我们有:

其中
 和
和 分别是权重,
分别是权重, 是平滑后的标签。 通常μ 使用均匀分布
是平滑后的标签。 通常μ 使用均匀分布
查看更多关于标签平滑的细节 https://arxiv.org/abs/1512.00567
- 参数:
- label (Variable) - 包含标签数据的输入变量。 标签数据应使用 one-hot 表示。
- prior_dist (Variable) - 用于平滑标签的先验分布。 如果未提供,则使用均匀分布。 prior_dist的shape应为
 。
。 - epsilon (float) - 用于混合原始真实分布和固定分布的权重。
- dtype (np.dtype | core.VarDesc.VarType | str) - 数据类型:float32,float_64,int等。
- name (str | None) - 此层的名称(可选)。 如果设置为None,则将自动命名图层。返回:张量变量, 包含平滑后的标签
返回类型: Variable
代码示例
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- label = fluid.layers.data(name="label", shape=[1], dtype="float32")
- one_hot_label = fluid.layers.one_hot(input=label, depth=10)
- smooth_label = fluid.layers.label_smooth(
- label=one_hot_label, epsilon=0.1, dtype="float32")
layer_norm
paddle.fluid.layers.layernorm(_input, scale=True, shift=True, begin_norm_axis=1, epsilon=1e-05, param_attr=None, bias_attr=None, act=None, name=None)- 假设特征向量存在于维度
begin_norm_axis … rank (input)上,计算大小为H的特征向量a在该维度上的矩统计量,然后使用相应的统计量对每个特征向量进行归一化。 之后,如果设置了scale和shift,则在标准化的张量上应用可学习的增益和偏差以进行缩放和移位。
请参考 Layer Normalization
公式如下



 : 该层神经元输入总和的向量表示
: 该层神经元输入总和的向量表示 : 层中隐藏的神经元个数
: 层中隐藏的神经元个数 : 可训练的缩放因子参数
: 可训练的缩放因子参数 : 可训练的bias参数
: 可训练的bias参数- 参数:
- input (Variable) - 输入张量变量。
- scale (bool) - 是否在归一化后学习自适应增益g。默认为True。
- shift (bool) - 是否在归一化后学习自适应偏差b。默认为True。
- begin_norm_axis (int) -
begin_norm_axis到rank(input)的维度执行规范化。默认1。 - epsilon (float) - 添加到方差的很小的值,以防止除零。默认1e-05。
- param_attr (ParamAttr | None) - 可学习增益g的参数属性。如果
scale为False,则省略param_attr。如果scale为True且param_attr为None,则默认ParamAttr将作为比例。如果添加了param_attr, 则将其初始化为1。默认None。 - bias_attr (ParamAttr | None) - 可学习偏差的参数属性b。如果
shift为False,则省略bias_attr。如果shift为True且param_attr为None,则默认ParamAttr将作为偏差。如果添加了bias_attr,则将其初始化为0。默认None。 - act (str) - 激活函数。默认 None
- name (str) - 该层的名称, 可选的。默认为None,将自动生成唯一名称。返回: 标准化后的结果
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32],
- dtype='float32')
- x = fluid.layers.layer_norm(input=data, begin_norm_axis=1)
leaky_relu
paddle.fluid.layers.leakyrelu(_x, alpha=0.02, name=None)- LeakyRelu 激活函数

- 参数:
- x (Variable) - LeakyRelu Operator的输入
- alpha (FLOAT|0.02) - 负斜率,值很小。
- name (str|None) - 此层的名称(可选)。如果设置为None,该层将被自动命名。代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[2,3,16,16], dtype="float32")
- y = fluid.layers.leaky_relu(x, alpha=0.01)
linear_chain_crf
paddle.fluid.layers.linearchain_crf(_input, label, param_attr=None)- 线性链条件随机场(Linear Chain CRF)
条件随机场定义间接概率图,节点代表随机变量,边代表两个变量之间的依赖。CRF学习条件概率
 ,
, 是结构性输入,
是结构性输入, 为输入标签。
为输入标签。
线性链条件随机场(Linear Chain CRF)是特殊的条件随机场(CRF),有利于序列标注任务。序列标注任务不为输入设定许多条件依赖。唯一的限制是输入和输出必须是线性序列。因此类似CRF的图是一个简单的链或者线,也就是线性链随机场(linear chain CRF)。
该操作符实现了线性链条件随机场(linear chain CRF)的前向——反向算法。详情请参照 http://www.cs.columbia.edu/~mcollins/fb.pdf 和 http://cseweb.ucsd.edu/~elkan/250Bwinter2012/loglinearCRFs.pdf。
长度为L的序列s的概率定义如下:

其中Z是正则化值,所有可能序列的P(s)之和为1,x是线性链条件随机场(linear chain CRF)的发射(emission)特征权重。
线性链条件随机场最终输出mini-batch每个训练样本的条件概率的对数
1.这里
代表Emission2.Transition的第一维度值,代表起始权重,这里用
表示3.Transition的下一维值,代表末尾权重,这里用
表示4.Transition剩下的值,代表转移权重,这里用
表示5.Label用
表示





注意:
1.条件随机场(CRF)的特征函数由发射特征(emission feature)和转移特征(transition feature)组成。发射特征(emission feature)权重在调用函数前计算,而不在函数里计算。
2.由于该函数对所有可能序列的进行全局正则化,发射特征(emission feature)权重应是未缩放的。因此如果该函数带有发射特征(emission feature),并且发射特征是任意非线性激活函数的输出,则请勿调用该函数。
3.Emission的第二维度必须和标记数字(tag number)相同
- 参数:
- input (Variable,LoDTensor,默认float类型LoDTensor) - 一个二维LoDTensor,shape为[N*D],N是mini-batch的大小,D是总标记数。线性链条件随机场的未缩放发射权重矩阵
- input (Tensor,默认float类型LoDTensor) - 一个二维张量,shape为[(D+2)*D]。linear_chain_crf操作符的可学习参数。更多详情见operator注释
- label (Variable,LoDTensor,默认int64类型LoDTensor) - shape为[N*10的LoDTensor,N是mini-batch的总元素数
- param_attr (ParamAttr) - 可学习参数的属性
- 返回:
- output(Variable,Tensor,默认float类型Tensor):shape为[N*D]的二维张量。Emission的指数。这是前向计算中的中间计算结果,在后向计算中还会复用
output(Variable,Tensor,默认float类型Tensor):shape为[(D+2)*D]的二维张量。Transition的指数。这是前向计算中的中间计算结果,在后向计算中还会复用
output(Variable,Tensor,默认float类型Tensor):mini-batch每个训练样本的条件概率的对数。这是一个shape为[S*1]的二维张量,S是mini-batch的序列数。注:S等同于mini-batch的序列数。输出不再是LoDTensor
返回类型:output(Variable)
代码示例:
- import paddle.fluid as fluid
- emission = fluid.layers.data(name='emission', shape=[1000], dtype='float32')
- target = fluid.layers.data(name='target', shape=[1], dtype='int32')
- crf_cost = fluid.layers.linear_chain_crf(
- input=emission,
- label=target,
- param_attr=fluid.ParamAttr(
- name='crfw',
- learning_rate=0.2))
lod_reset
paddle.fluid.layers.lodreset(_x, y=None, target_lod=None)- 设定x的LoD为y或者target_lod。如果提供y,首先将y.lod指定为目标LoD,否则y.data将指定为目标LoD。如果未提供y,目标LoD则指定为target_lod。如果目标LoD指定为Y.data或target_lod,只提供一层LoD。
- * 例1:
- 给定一级LoDTensor x:
- x.lod = [[ 2, 3, 1 ]]
- x.data = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0]]
- x.dims = [6, 1]
- target_lod: [4, 2]
- 得到一级LoDTensor:
- out.lod = [[4, 2]]
- out.data = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0]]
- out.dims = [6, 1]
- * 例2:
- 给定一级LoDTensor x:
- x.lod = [[2, 3, 1]]
- x.data = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0]]
- x.dims = [6, 1]
- y是张量(Tensor):
- y.data = [[2, 4]]
- y.dims = [1, 3]
- 得到一级LoDTensor:
- out.lod = [[2, 4]]
- out.data = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0]]
- out.dims = [6, 1]
- * 例3:
- 给定一级LoDTensor x:
- x.lod = [[2, 3, 1]]
- x.data = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0]]
- x.dims = [6, 1]
- y是二级LoDTensor:
- y.lod = [[2, 2], [2, 2, 1, 1]]
- y.data = [[1.1], [2.1], [3.1], [4.1], [5.1], [6.1]]
- y.dims = [6, 1]
- 得到一个二级LoDTensor:
- out.lod = [[2, 2], [2, 2, 1, 1]]
- out.data = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0]]
- out.dims = [6, 1]
- 参数:
- x (Variable)-输入变量,可以为Tensor或者LodTensor
- y (Variable|None)-若提供,输出的LoD则衍生自y
- target_lod (list|tuple|None)-一层LoD,y未提供时作为目标LoD返回:输出变量,该层指定为LoD
返回类型:变量
抛出异常:TypeError - 如果y和target_lod都为空
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[10])
- y = fluid.layers.data(name='y', shape=[10, 20], lod_level=2)
- out = fluid.layers.lod_reset(x=x, y=y)
log
paddle.fluid.layers.log(x, name=None)- 给定输入张量,计算其每个元素的自然对数

- 参数:
- x (Variable) – 输入张量
- name (str|None, default None) – 该layer的名称,如果为None,自动命名返回:给定输入张量计算自然对数
返回类型: 变量(variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3, 4], dtype="float32")
- output = fluid.layers.log(x)
log_loss
paddle.fluid.layers.logloss(_input, label, epsilon=0.0001, name=None)- 负log loss层
该层对输入的预测结果和目的标签进行计算,返回负log loss损失值。

- 参数:
- input (Variable|list) – 形为[N x 1]的二维张量, 其中N为batch大小。 该输入是由先前运算得来的概率集。
- label (Variable|list) – 形为[N x 1]的二维张量,承载着正确标记的数据, 其中N为batch大小。
- epsilon (float) – epsilon
- name (string) – log_loss层的名称返回: 形为[N x 1]的二维张量,承载着负log_loss值
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- prob = fluid.layers.data(name='prob', shape=[10], dtype='float32')
- cost = fluid.layers.log_loss(input=prob, label=label)
logical_and
paddle.fluid.layers.logicaland(_x, y, out=None, name=None)- logical_and算子
它在X和Y上以元素方式操作,并返回Out。X、Y和Out是N维布尔张量(Tensor)。Out的每个元素的计算公式为:

- 参数:
- x (Variable)- (LoDTensor)logical_and算子的左操作数
- y (Variable)- (LoDTensor)logical_and算子的右操作数
- out (Tensor)- 输出逻辑运算的张量。
- name (basestring | None)- 输出的名称。返回: (LoDTensor)n-dim bool张量。每个元素的计算公式:

返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- left = fluid.layers.data(
- name='left', shape=[1], dtype='int32')
- right = fluid.layers.data(
- name='right', shape=[1], dtype='int32')
- result = fluid.layers.logical_and(x=left, y=right)
logical_not
paddle.fluid.layers.logicalnot(_x, out=None, name=None)- logical_not算子
它在X上以元素方式操作,并返回Out。X和Out是N维布尔张量(Tensor)。Out的每个元素的计算公式为:

- 参数:
- x (Variable)- (LoDTensor)logical_not算子的操作数
- out (Tensor)- 输出逻辑运算的张量。
- name (basestring | None)- 输出的名称。返回: (LoDTensor)n维布尔张量。
返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- left = fluid.layers.data(
- name='left', shape=[1], dtype='int32')
- result = fluid.layers.logical_not(x=left)
logical_or
paddle.fluid.layers.logicalor(_x, y, out=None, name=None)- logical_or算子
它在X和Y上以元素方式操作,并返回Out。X、Y和Out是N维布尔张量(Tensor)。Out的每个元素的计算公式为:

- 参数:
- x (Variable)- (LoDTensor)logical_or算子的左操作数
- y (Variable)- (LoDTensor)logical_or算子的右操作数
- out (Tensor)- 输出逻辑运算的张量。
- name (basestring | None)- 输出的名称。返回: (LoDTensor)n维布尔张量。每个元素的计算公式:

返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- left = fluid.layers.data(
- name='left', shape=[1], dtype='int32')
- right = fluid.layers.data(
- name='right', shape=[1], dtype='int32')
- result = fluid.layers.logical_or(x=left, y=right)
logical_xor
paddle.fluid.layers.logicalxor(_x, y, out=None, name=None)- logical_xor算子
它在X和Y上以元素方式操作,并返回Out。X、Y和Out是N维布尔张量(Tensor)。Out的每个元素的计算公式为:

- 参数:
- x (Variable)- (LoDTensor)logical_xor算子的左操作数
- y (Variable)- (LoDTensor)logical_xor算子的右操作数
- out (Tensor)- 输出逻辑运算的张量。
- name (basestring | None)- 输出的名称。返回: (LoDTensor)n维布尔张量。
返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- left = fluid.layers.data(
- name='left', shape=[1], dtype='int32')
- right = fluid.layers.data(
- name='right', shape=[1], dtype='int32')
- result = fluid.layers.logical_xor(x=left, y=right)
lrn
paddle.fluid.layers.lrn(input, n=5, k=1.0, alpha=0.0001, beta=0.75, name=None)- 局部响应正则层(Local Response Normalization Layer)
该层对局部输入区域正则化,执行一种侧向抑制(lateral inhibition)。
公式如下:

- 在以上公式中:
 :累加的通道数
:累加的通道数 :位移(避免除数为0)
:位移(避免除数为0) : 缩放参数
: 缩放参数 : 指数参数参考 : ImageNet Classification with Deep Convolutional Neural Networks
: 指数参数参考 : ImageNet Classification with Deep Convolutional Neural Networks
参数:
- input (Variable)- 该层输入张量,输入张量维度必须为4
- n (int,默认5) - 累加的通道数
- k (float,默认1.0)- 位移(通常为正数,避免除数为0)
- alpha (float,默认1e-4)- 缩放参数
- beta (float,默认0.75)- 指数
- name (str,默认None)- 操作符名
- 抛出异常:
ValueError- 如果输入张量的阶不为4返回:张量,存储转置结果
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name="data", shape=[3, 112, 112], dtype="float32")
- lrn = fluid.layers.lrn(input=data)
lstm
paddle.fluid.layers.lstm(input, init_h, init_c, max_len, hidden_size, num_layers, dropout_prob=0.0, is_bidirec=False, is_test=False, name=None, default_initializer=None, seed=-1)- 如果您的设备是GPU,本op将使用cudnn LSTM实现
一个没有 peephole 连接的四门长短期记忆网络。在前向传播中,给定迭代的输出ht和单元输出ct可由递归输入ht-1、单元输入ct-1和上一层输入xt计算,给定矩阵W、R和bias bW, bR由下式计算:

- 公式中:
- W 项表示权重矩阵(e.g.
 是从输入门到输入的权重矩阵)
是从输入门到输入的权重矩阵) - b 项表示偏差向量(
 和
和 是输入门的偏差向量)
是输入门的偏差向量) - sigmoid 是 logistic sigmoid 函数
- i、f、o、c 分别为输入门、遗忘门、输出门和激活向量,它们的大小与 cell 输出激活向量h相同。
 是向量的元素乘积
是向量的元素乘积- tanh是激活函数
 也称为候选隐藏状态,它是根据当前输入和之前的隐藏状态来计算的sigmoid的计算公式为:
也称为候选隐藏状态,它是根据当前输入和之前的隐藏状态来计算的sigmoid的计算公式为:
- W 项表示权重矩阵(e.g.
 。
。
- 参数:
- input (Variable) - LSTM 输入张量,形状必须为(seq_len x,batch_size,x,input_size)
- init_h (Variable) – LSTM的初始隐藏状态,是一个有形状的张量(num_layers,x,batch_size,x,hidden_size)如果is_bidirec = True,形状应该是(num_layers*2,x, batch_size, x, hidden_size)
- init_c (Variable) - LSTM的初始状态。这是一个有形状的张量(num_layers, x, batch_size, x, hidden_size)如果is_bidirec = True,形状应该是(num_layers*2, x, batch_size, x, hidden_size)
- max_len (int) – LSTM的最大长度。输入张量的第一个 dim 不能大于max_len
- hidden_size (int) - LSTM的隐藏大小
- num_layers (int) – LSTM的总层数
- dropout_prob (float|0.0) – dropout prob,dropout 只在 rnn 层之间工作,而不是在时间步骤之间。dropout 不作用于最后的 rnn 层的 rnn 输出中
- is_bidirec (bool) – 是否是双向的
- is_test (bool) – 是否在测试阶段
- name (str|None) - 此层的名称(可选)。如果没有设置,该层将被自动命名。
- default_initializer (Initialize|None) – 在哪里使用初始化器初始化权重,如果没有设置,将进行默认初始化。
- seed (int) – LSTM中dropout的Seed,如果是-1,dropout将使用随机Seed返回: 三个张量, rnn_out, last_h, last_c:
rnn_out为LSTM hidden的输出结果。形为(seq_len x batch_size x hidden_size)如果is_bidirec设置为True,则形为(seq_len x batch_sze hidden_size * 2)
- last_h(Tensor): LSTM最后一步的隐藏状态,形状为(num_layers x batch_size x hidden_size);如果is_bidirec设置为True,形状为(num_layers*2 x batch_size x hidden_size)
- last_c(Tensor): LSTM最后一步的cell状态,形状为(num_layers x batch_size x hidden_size);如果is_bidirec设置为True,形状为(num_layers*2 x batch_size x hidden_size)返回类型: rnn_out(Tensor),last_h(Tensor),last_c(Tensor)
代码示例:
- import paddle.fluid as fluid
- emb_dim = 256
- vocab_size = 10000
- data = fluid.layers.data(name='x', shape=[-1, 100, 1],
- dtype='int32')
- emb = fluid.layers.embedding(input=data, size=[vocab_size, emb_dim], is_sparse=True)
- batch_size = 20
- max_len = 100
- dropout_prob = 0.2
- input_size = 100
- hidden_size = 150
- num_layers = 1
- init_h = layers.fill_constant( [num_layers, batch_size, hidden_size], 'float32', 0.0 )
- init_c = layers.fill_constant( [num_layers, batch_size, hidden_size], 'float32', 0.0 )
- rnn_out, last_h, last_c = fluid.layers.lstm(emb, init_h, init_c, max_len, hidden_size, num_layers, dropout_prob=dropout_prob)
lstm_unit
paddle.fluid.layers.lstmunit(_x_t, hidden_t_prev, cell_t_prev, forget_bias=0.0, param_attr=None, bias_attr=None, name=None)- Lstm unit layer
lstm步的等式:

lstm单元的输入包括
 ,
, 和
和 。
。 和
和 的第二维应当相同。在此实现过程中,线性转换和非线性转换分离。以
的第二维应当相同。在此实现过程中,线性转换和非线性转换分离。以 为例。线性转换运用到fc层,等式为:
为例。线性转换运用到fc层,等式为:

非线性转换运用到lstm_unit运算,方程如下:

该层有
 和
和 两个输出。
两个输出。
- 参数:
- x_t (Variable) - 当前步的输入值,二维张量,shape为 M x N ,M是批尺寸,N是输入尺寸
- hidden_t_prev (Variable) - lstm单元的隐藏状态值,二维张量,shape为 M x S,M是批尺寸,N是lstm单元的大小
- cell_t_prev (Variable) - lstm单元的cell值,二维张量,shape为 M x S ,M是批尺寸,N是lstm单元的大小
- forget_bias (Variable) - lstm单元的遗忘bias
- param_attr (ParamAttr|None) - 可学习hidden-hidden权重的擦参数属性。如果设为None或者ParamAttr的一个属性,lstm_unit创建ParamAttr为param_attr。如果param_attr的初始化函数未设置,参数初始化为Xavier。默认:None
- bias_attr (ParamAttr|None) - 可学习bias权重的bias属性。如果设为False,输出单元中则不添加bias。如果设为None或者ParamAttr的一个属性,lstm_unit创建ParamAttr为bias_attr。如果bias_attr的初始化函数未设置,bias初始化为0.默认:None
- name (str|None) - 该层名称(可选)。若设为None,则自动为该层命名返回:lstm单元的hidden(隐藏状态)值和cell值
返回类型:tuple(元组)
- 抛出异常:
ValueError-x_t,hidden_t_prev和cell_t_prev的阶不为2,或者x_t,hidden_t_prev和cell_t_prev的第一维不一致,或者hidden_t_prev和cell_t_prev的第二维不一致代码示例:
- import paddle.fluid as fluid
- dict_dim, emb_dim, hidden_dim = 128, 64, 512
- data = fluid.layers.data(name='step_data', shape=[1], dtype='int32')
- x = fluid.layers.embedding(input=data, size=[dict_dim, emb_dim])
- pre_hidden = fluid.layers.data(name='pre_hidden', shape=[hidden_dim], dtype='float32')
- pre_cell = fluid.layers.data(name='pre_cell', shape=[hidden_dim], dtype='float32')
- hidden = fluid.layers.lstm_unit(
- x_t=x,
- hidden_t_prev=prev_hidden,
- cell_t_prev=prev_cell)
margin_rank_loss
paddle.fluid.layers.marginrank_loss(_label, left, right, margin=0.1, name=None)- margin rank loss(差距排序损失)层。在排序问题中,它可以比较传进来的
left得分和right得分。
可用如下等式定义:

- 参数:
- label (Variable) – 表明是否左元素排名要高于右元素
- left (Variable) – 左元素排序得分
- right (Variable) – 右元素排序得分
- margin (float) – 指定固定的得分差
- name (str|None) – 可选项,该层的命名。如果为None, 该层将会被自动命名返回: 排序损失
返回类型: 变量(Variable)
- 抛出异常:
ValueError-label,left,right有一者不为Variable类型时,抛出此异常代码示例
- import paddle.fluid as fluid
- label = fluid.layers.data(name="label", shape=[-1, 1], dtype="float32")
- left = fluid.layers.data(name="left", shape=[-1, 1], dtype="float32")
- right = fluid.layers.data(name="right", shape=[-1, 1], dtype="float32")
- out = fluid.layers.margin_rank_loss(label, left, right)
matmul
paddle.fluid.layers.matmul(x, y, transpose_x=False, transpose_y=False, alpha=1.0, name=None)- 对两个张量进行矩阵相乘
当前输入的张量可以为任意阶,但当任意一个输入的阶数大于3时,两个输入的阶必须相等。实际的操作取决于x,y的维度和 transpose_x , transpose_y 的标记值。具体如下:
- 如果transpose值为真,则对应
tensor的最后两维将被转置。如:x是一个shape=[D]的一阶张量,那么x在非转置形式中为[1,D],在转置形式中为[D,1],而y则相反,在非转置形式中作为[D,1],在转置形式中作为[1,D]。 转置后,这两个
tensors将为 2-D 或 n-D ,并依据下列规则进行矩阵相乘:- 如果两个都是2-D,则同普通矩阵一样进行矩阵相乘- 如果任意一个是n-D,则将其视为驻留在最后两个维度的矩阵堆栈,并在两个张量上应用支持广播的批处理矩阵乘法。注意,如果原始张量x或y的秩为1且没有转置,则在矩阵乘法之后,前置或附加维度1将被移除。参数:
- x (Variable)-输入变量,类型为Tensor或LoDTensor
- y (Variable)-输入变量,类型为Tensor或LoDTensor
- transpose_x (bool)-相乘前是否转置x
- transpose_y (bool)-相乘前是否转置y
- alpha (float)-输出比例。默认为1.0
- name (str|None)-该层名称(可选)。如果设置为空,则自动为该层命名返回:张量乘积变量
返回类型:变量(Variable)
代码示例:
- # 以下是解释输入和输出维度的示例
- # x: [B, ..., M, K], y: [B, ..., K, N]
- # fluid.layers.matmul(x, y) # out: [B, ..., M, N]
- # x: [B, M, K], y: [B, K, N]
- # fluid.layers.matmul(x, y) # out: [B, M, N]
- # x: [B, M, K], y: [K, N]
- # fluid.layers.matmul(x, y) # out: [B, M, N]
- # x: [M, K], y: [K, N]
- # fluid.layers.matmul(x, y) # out: [M, N]
- # x: [B, M, K], y: [K]
- # fluid.layers.matmul(x, y) # out: [B, M]
- # x: [K], y: [K]
- # fluid.layers.matmul(x, y) # out: [1]
- # x: [M], y: [N]
- # fluid.layers.matmul(x, y, True, True) # out: [M, N]
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[2, 3], dtype='float32')
- y = fluid.layers.data(name='y', shape=[3, 2], dtype='float32')
- out = fluid.layers.matmul(x, y, True, True)
maxout
paddle.fluid.layers.maxout(x, groups, name=None)- 假设输入形状为(N, Ci, H, W),输出形状为(N, Co, H, W),则
 运算公式如下:
运算公式如下:

- 请参阅论文:
- Maxout Networks: http://www.jmlr.org/proceedings/papers/v28/goodfellow13.pdf
- Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks: https://arxiv.org/pdf/1312.6082v4.pdf
- 参数:
- x (Variable) - (tensor) maxout算子的输入张量。输入张量的格式为NCHW。其中N为 batch size ,C为通道数,H和W为feature的高和宽
- groups (INT)- 指定将输入张量的channel通道维度进行分组的数目。输出的通道数量为通道数除以组数。
- name (basestring|None) - 输出的名称返回:Tensor,maxout算子的输出张量。输出张量的格式也是NCHW。其中N为 batch size,C为通道数,H和W为特征的高和宽。
返回类型:out(Variable)
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name='data',
- shape=[256, 32, 32],
- dtype='float32')
- out = fluid.layers.maxout(input, groups=2)
mean
paddle.fluid.layers.mean(x, name=None)mean算子计算X中所有元素的平均值
参数:
- x (Variable)- (Tensor) 均值运算的输入。
- name (basestring | None)- 输出的名称。返回: 均值运算输出张量(Tensor)
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name='data', shape=[2, 3], dtype='float32')
- mean = fluid.layers.mean(input)
mean_iou
paddle.fluid.layers.meaniou(_input, label, num_classes)- 均值IOU(Mean Intersection-Over-Union)是语义图像分割中的常用的评价指标之一,它首先计算每个语义类的IOU,然后计算类之间的平均值。定义如下:

在一个confusion矩阵中累积得到预测值,然后从中计算均值-IOU。
- 参数:
- input (Variable) - 类型为int32或int64的语义标签的预测结果张量。
- label (Variable) - int32或int64类型的真实label张量。它的shape应该与输入相同。
- num_classes (int) - 标签可能的类别数目。返回: 返回三个变量:
mean_iou: 张量,形为[1], 代表均值IOU。
- out_wrong: 张量,形为[num_classes]。每个类别中错误的个数。
- out_correct:张量,形为[num_classes]。每个类别中的正确的个数。返回类型: mean_iou (Variable),out_wrong(Variable),out_correct(Variable)
代码示例
- import paddle.fluid as fluid
- predict = fluid.layers.data(name='predict', shape=[3, 32, 32])
- label = fluid.layers.data(name='label', shape=[1])
- iou, wrongs, corrects = fluid.layers.mean_iou(predict, label, num_classes)
merge_selected_rows
paddle.fluid.layers.mergeselected_rows(_x, name=None)- 实现合并选中行(row)操作
该运算用于合并(值相加)输入张量中重复的行。输出行没有重复的行,并且按值从小到大顺序重新对行排序。
- 例如:
- 输入:
- X.rows = [0, 5, 5, 4, 19]
- X.height = 20
- X.value = [[1, 1] [2, 2] [3, 3] [4, 4] [6, 6]]
- 输出:
- Out.row is [0, 4, 5, 19]
- Out.height is 20
- Out.value is: [[1, 1] [4, 4] [5, 5] [6, 6]]
- 参数:
- x (Variable) – 输入类型为SelectedRows, 选中行有可能重复
- name (basestring|None) – 输出变量的命名返回: 输出类型为SelectedRows,并且选中行不会重复
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- b = fluid.default_main_program().global_block()
- var = b.create_var(
- name="X", dtype="float32", persistable=True,
- type=fluid.core.VarDesc.VarType.SELECTED_ROWS)
- y = fluid.layers.merge_selected_rows(var)
mul
paddle.fluid.layers.mul(x, y, x_num_col_dims=1, y_num_col_dims=1, name=None)- mul算子此运算是用于对输入X和Y执行矩阵乘法。等式是:

输入X和Y都可以携带LoD(详细程度)信息。但输出仅与输入X共享LoD信息。
- 参数:
- x (Variable)- (Tensor) 乘法运算的第一个输入张量。
- y (Variable)- (Tensor) 乘法运算的第二个输入张量。
- x_num_col_dims (int)- 默认值1, 可以将具有两个以上维度的张量作为输入。如果输入X是具有多于两个维度的张量,则输入X将先展平为二维矩阵。展平规则是:前
num_col_dims将被展平成最终矩阵的第一个维度(矩阵的高度),其余的 rank(X) - num_col_dims 维度被展平成最终矩阵的第二个维度(矩阵的宽度)。结果是展平矩阵的高度等于X的前x_num_col_dims维数的乘积,展平矩阵的宽度等于X的最后一个秩(x)-num_col_dims个剩余维度的维数的乘积。例如,假设X是一个五维张量,形状为(2,3,4,5,6)。 则扁平化后的张量具有的形即为 (2x3x4,5x6)=(24,30)。 - y_num_col_dims (int)- 默认值1, 可以将具有两个以上维度的张量作为输入。如果输入Y是具有多于两个维度的张量,则Y将首先展平为二维矩阵。
y_num_col_dims属性确定Y的展平方式。有关更多详细信息,请参阅x_num_col_dims的注释。 - name (basestring | None)- 输出的名称。返回: 乘法运算输出张量(Tensor).
返回类型: 输出(Variable)。
代码示例
- import paddle.fluid as fluid
- dataX = fluid.layers.data(name="dataX", append_batch_size = False, shape=[2, 5], dtype="float32")
- dataY = fluid.layers.data(name="dataY", append_batch_size = False, shape=[5, 3], dtype="float32")
- output = fluid.layers.mul(dataX, dataY,
- x_num_col_dims = 1,
- y_num_col_dims = 1)
multiplex
paddle.fluid.layers.multiplex(inputs, index)- 引用给定的索引变量,该层从输入变量中选择行构造Multiplex变量。
假设有
 个输入变量,
个输入变量, 代表第i个输入变量,而且
代表第i个输入变量,而且 is in
is in 。
。
所有输入变量都是具有相同形状的张量
 。
。
请注意,输入张量的秩应至少为2。每个输入变量将被视为形状为
 的二维矩阵,其中
的二维矩阵,其中 表示
表示 ,N表示
,N表示 。
。
设
 为第i个输入变量的第j行。 给定的索引变量是具有形状[M,1]的2-D张量。 设
为第i个输入变量的第j行。 给定的索引变量是具有形状[M,1]的2-D张量。 设 为索引变量的第i个索引值。 然后输出变量将是一个形状为
为索引变量的第i个索引值。 然后输出变量将是一个形状为 的张量。
的张量。
如果将输出张量视为具有形状[M,N]的2-D矩阵,并且令O[i]为矩阵的第i行,则O[i]等于

- Ids: 索引张量
- X[0 : N - 1]: 输出的候选张量度(N >= 2).
- 对于从 0 到 batchSize-1 的每个索引i,输出是第(Ids [i]) 张量的第i行对于第i行的输出张量:

其中
 为输出张量,
为输出张量, 为第k个输入张量,并且
为第k个输入张量,并且 。
。
示例:
- 例1:
- 假设:
- X = [[[0,0,3,4], [0,1,3,4], [0,2,4,4], [0,3,3,4]],
- [[1,0,3,4], [1,1,7,8], [1,2,4,2], [1,3,3,4]],
- [[2,0,3,4], [2,1,7,8], [2,2,4,2], [2,3,3,4]],
- [[3,0,3,4], [3,1,7,8], [3,2,4,2], [3,3,3,4]]]
- index = [3,0,1,2]
- out:[[3 0 3 4] // X[3,0] (3 = index[i], 0 = i); i=0
- [0 1 3 4] // X[0,1] (0 = index[i], 1 = i); i=1
- [1 2 4 2] // X[1,2] (0 = index[i], 2 = i); i=2
- [2 3 3 4]] // X[2,3] (0 = index[i], 3 = i); i=3
- 例2:
- 假设:
- X = [[[0,0,3,4], [0,1,3,4], [0,2,4,4], [0,3,3,4]],
- [[1,0,3,4], [1,1,7,8], [1,2,4,2], [1,3,3,4]]]
- index = [1,0]
- out:[[1 0 3 4] // X[1,0] (3 = index[0], 0 = i); i=1
- [0 1 3 4] // X[0,1] (0 = index[1], 1 = i); i=2
- [0 2 4 4] // X[0,2] (0 = 0, 2 = i); i=3
- [0 3 3 4]] // X[0,3] (0 = 0, 3 = i); i=4
- 参数:
- inputs (list) - 要从中收集的变量列表。所有变量的形状相同,秩至少为2
- index (Variable) - Tensor
,索引变量为二维张量,形状[M, 1],其中M为批大小。 返回:multiplex 张量
代码示例
- import paddle.fluid as fluid
- x1 = fluid.layers.data(name='x1', shape=[4], dtype='float32')
- x2 = fluid.layers.data(name='x2', shape=[4], dtype='float32')
- index = fluid.layers.data(name='index', shape=[1], dtype='int32')
- out = fluid.layers.multiplex(inputs=[x1, x2], index=index)
nce
paddle.fluid.layers.nce(input, label, num_total_classes, sample_weight=None, param_attr=None, bias_attr=None, num_neg_samples=None, name=None, sampler='uniform', custom_dist=None, seed=0, is_sparse=False)计算并返回噪音对比估计( noise-contrastive estimation training loss)。请参考 See Noise-contrastive estimation: A new estimation principle for unnormalized statistical models该operator默认使用均匀分布进行抽样。
参数:
- input (Variable) - 输入变量
- label (Variable) - 标签
- num_total_classes (int) - 所有样本中的类别的总数
- sample_weight (Variable|None) - 存储每个样本权重,shape为[batch_size, 1]存储每个样本的权重。每个样本的默认权重为1.0
- param_attr (ParamAttr|None) -
 的参数属性。如果它没有被设置为ParamAttr的一个属性,nce将创建ParamAttr为param_attr。如没有设置param_attr的初始化器,那么参数将用Xavier初始化。默认值:None
的参数属性。如果它没有被设置为ParamAttr的一个属性,nce将创建ParamAttr为param_attr。如没有设置param_attr的初始化器,那么参数将用Xavier初始化。默认值:None - bias_attr (ParamAttr|bool|None) - nce偏置的参数属性。如果设置为False,则不会向输出添加偏置(bias)。如果值为None或ParamAttr的一个属性,则bias_attr=ParamAtt。如果没有设置bias_attr的初始化器,偏置将被初始化为零。默认值:None
- num_neg_samples (int) - 负样例的数量。默认值是10
- name (str|None) - 该layer的名称(可选)。如果设置为None,该层将被自动命名
- sampler (str) – 取样器,用于从负类别中进行取样。可以是 ‘uniform’, ‘log_uniform’ 或 ‘custom_dist’。 默认 ‘uniform’
- custom_dist (float[]) – 一个 float[] 并且它的长度为
num_total_classes。 如果取样器类别为‘custom_dist’,则使用此参数。 custom_dist[i] 是第i个类别被取样的概率。默认为 None - seed (int) – 取样器使用的seed。默认为0
- is_sparse (bool) – 标志位,指明是否使用稀疏更新,
 和
和 会变为 SelectedRows返回: nce loss
会变为 SelectedRows返回: nce loss
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- import numpy as np
- window_size = 5
- words = []
- for i in xrange(window_size):
- words.append(fluid.layers.data(
- name='word_{0}'.format(i), shape=[1], dtype='int64'))
- dict_size = 10000
- label_word = int(window_size / 2) + 1
- embs = []
- for i in xrange(window_size):
- if i == label_word:
- continue
- emb = fluid.layers.embedding(input=words[i], size=[dict_size, 32],
- param_attr='embed', is_sparse=True)
- embs.append(emb)
- embs = fluid.layers.concat(input=embs, axis=1)
- loss = fluid.layers.nce(input=embs, label=words[label_word],
- num_total_classes=dict_size, param_attr='nce.w_0',
- bias_attr='nce.b_0')
- # 或使用自定义分布
- dist = np.array([0.05,0.5,0.1,0.3,0.05])
- loss = fluid.layers.nce(input=embs, label=words[label_word],
- num_total_classes=5, param_attr='nce.w_1',
- bias_attr='nce.b_1',
- num_neg_samples=3,
- sampler="custom_dist",
- custom_dist=dist)
npair_loss
paddle.fluid.layers.npairloss(_anchor, positive, labels, l2_reg=0.002)- Npair Loss Layer
参考阅读 Improved Deep Metric Learning with Multi class N pair Loss Objective
NPair损失需要成对的数据。NPair损失分为两部分:第一部分是嵌入向量上的L2正则化器;第二部分是以anchor的相似矩阵和正的相似矩阵为逻辑的交叉熵损失。
- 参数:
- anchor (Variable) - 嵌入锚定图像的向量。尺寸=[batch_size, embedding_dims]
- positive (Variable) - 嵌入正图像的向量。尺寸=[batch_size, embedding_dims]
- labels (Variable) - 1维张量,尺寸=[batch_size]
- l2_reg (float32) - 嵌入向量的L2正则化项,默认值:0.002返回: npair loss,尺寸=[1]
返回类型:npair loss(Variable)
代码示例:
- import paddle.fluid as fluid
- anchor = fluid.layers.data(
- name = 'anchor', shape = [18, 6], dtype = 'float32', append_batch_size=False)
- positive = fluid.layers.data(
- name = 'positive', shape = [18, 6], dtype = 'float32', append_batch_size=False)
- labels = fluid.layers.data(
- name = 'labels', shape = [18], dtype = 'float32', append_batch_size=False)
- npair_loss = fluid.layers.npair_loss(anchor, positive, labels, l2_reg = 0.002)
one_hot
paddle.fluid.layers.onehot(_input, depth)该层创建输入指数的one-hot表示
参数:
- input (Variable)-输入指数,最后维度必须为1
- depth (scalar)-整数,定义one-hot维度的深度返回:输入的one-hot表示
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- label = fluid.layers.data(name="label", shape=[1], dtype="int64")
- one_hot_label = fluid.layers.one_hot(input=label, depth=10)
pad
paddle.fluid.layers.pad(x, paddings, pad_value=0.0, name=None)- 在张量上加上一个由
pad_value给出的常数值,填充宽度由paddings指定。其中,维度i中x内容前填充的值个数用paddings[i]表示,维度i中x内容后填充的值个数用paddings[i+1]表示。
一个例子:
- Given:
- x = [[1, 2], [3, 4]]
- paddings = [0, 1, 1, 2]
- pad_value = 0
- Return:
- out = [[0, 1, 2, 0, 0]
- [0, 3, 4, 0, 0]
- [0, 0, 0, 0, 0]]
- 参数:
- x (Variable) — —输入张量变量。
- paddings (list) — 一个整数列表。按顺序填充在每个维度上填充元素。
padding长度必须是rank(x)×2 - pad_value (float) — 用来填充的常量值。
- name (str|None) — 这个层的名称(可选)。如果设置为None,该层将被自动命名。返回: 填充后的张量变量
返回类型: 变量(Variable)
代码示例
- # x 为一个秩为2的张量
- import paddle.fluid as fluid
- x = fluid.layers.data(name='data', shape=[224], dtype='float32')
- out = fluid.layers.pad(
- x=x, paddings=[0, 1, 1, 2], pad_value=0.)
pad2d
paddle.fluid.layers.pad2d(input, paddings=[0, 0, 0, 0], mode='constant', pad_value=0.0, data_format='NCHW', name=None)- 依照 paddings 和 mode 属性对图像进行2维
pad,如果mode是reflection,则paddings[0]和paddings[1]必须不大于height-1。宽度维数具有相同的条件。
例如:
- 假设X是输入图像:
- X = [[1, 2, 3],
- [4, 5, 6]]
- Case 0:
- paddings = [0, 1, 2, 3],
- mode = 'constant'
- pad_value = 0
- Out = [[0, 0, 1, 2, 3, 0, 0, 0]
- [0, 0, 4, 5, 6, 0, 0, 0]
- [0, 0, 0, 0, 0, 0, 0, 0]]
- Case 1:
- paddings = [0, 1, 2, 1],
- mode = 'reflect'
- Out = [[3, 2, 1, 2, 3, 2]
- [6, 5, 4, 5, 6, 5]
- [3, 2, 1, 2, 3, 2]]
- Case 2:
- paddings = [0, 1, 2, 1],
- mode = 'edge'
- Out = [[1, 1, 1, 2, 3, 3]
- [4, 4, 4, 5, 6, 6]
- [4, 4, 4, 5, 6, 6]]
- 参数:
- input (Variable) - 具有[N, C, H, W]格式或[N, H, W, C]格式的输入图像。
- paddings (tuple|list|Variable) - 填充区域的大小。如果填充是一个元组,它必须包含四个整数,(padding_top, padding_bottom, padding_left, padding_right)。默认:padding =[0,0,0,0]。
- mode (str) - 三种模式:constant(默认)、reflect、edge。默认值:常数
- pad_value (float32) - 以常量模式填充填充区域的值。默认值:0
- data_format (str) - 可选字符串,选项有:
NHWC,NCHW。指定输入数据的数据格式。默认值:NCHW - name (str|None) - 此层的名称(可选)。如果没有设置,该层将被自动命名。返回: tensor变量,按照 padding值 和 mode 进行填充
返回类型:variable
代码示例:
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[3, 32, 32], dtype='float32')
- result = fluid.layers.pad2d(input=data, paddings=[1,2,3,4], mode='reflect')
pad_constant_like
paddle.fluid.layers.padconstant_like(_x, y, pad_value=0.0, name=None)- 使用
pad_value填充Y,填充到每个axis(轴)值的数量由X和Y的形不同而指定。((0,shape_x_0 - shape_y_0),…(0,shape_x_n - shape_y_n ))是每个axis唯一pad宽度。输入应该是k维张量(k> 0且k <7)。
实例如下
- Given:
- X = [[[[ 0, 1, 2],
- [ 3, 4, 5]],
- [[ 6, 7, 8],
- [ 9, 10, 11]],
- [[12, 13, 14],
- [15, 16, 17]]],
- [[[18, 19, 20],
- [21, 22, 23]],
- [[24, 25, 26],
- [27, 28, 29]],
- [[30, 31, 32],
- [33, 34, 35]]]]
- X.shape = (2, 3, 2, 3)
- Y = [[[[35, 36, 37]],
- [[38, 39, 40]],
- [[41, 42, 43]]]]
- Y.shape = (1, 3, 1, 3)
- 参数:
- x (Variable)- 输入Tensor变量。
- y (Variable)- 输出Tensor变量。
- pad_value (float) - 用于填充的常量值。
- name (str | None) - 这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回:填充张量(Tensor)变量
返回类型: 变量(Variable)
示例代码
- # x是秩为4的tensor, x.shape = (2, 3, 2, 3)
- # y是秩为4的tensor, y.shape = (1, 3, 1, 3)
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[2,3,2,3], dtype='float32')
- y = fluid.layers.data(name='y', shape=[1,3,1,3], dtype='float32')
- out = fluid.layers.pad_constant_like(x=x, y=y, pad_value=0.)
- # out是秩为4的tensor, out.shape = [2, 3 ,2 , 3]
pixel_shuffle
paddle.fluid.layers.pixelshuffle(_x, upscale_factor)- pixel shuffle 层(像素重组层)
该层将一个形为[N, C, H, W]的张量重新排列成形为 [N, C/r*2, Hr, W*r] 的张量。这样做有利于实现步长(stride)为1/r的高效sub-pixel(亚像素)卷积。详见Shi等人在2016年发表的论文 Real Time Single Image and Video Super Resolution Using an Efficient Sub Pixel Convolutional Neural Network 。
- 给定一个形为 x.shape = [1, 9, 4, 4] 的4-D张量
- 设定:upscale_factor=3
- 那么输出张量的形为:[1, 1, 12, 12]
- 参数:
- x (Variable)- 输入Tensor变量。
- upscale_factor (int)- 增大空间分辨率的增大因子返回:根据新的维度信息进行重组的张量
返回类型: Variable
抛出异常: ValueError - 如果upscale_factor的平方不能整除输入的通道维(C)大小。
示例代码
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[9,4,4])
- output = fluid.layers.pixel_shuffle(x=input, upscale_factor=3)
pool2d
paddle.fluid.layers.pool2d(input, pool_size=-1, pool_type='max', pool_stride=1, pool_padding=0, global_pooling=False, use_cudnn=True, ceil_mode=False, name=None, exclusive=True)- pooling2d操作符根据
input, 池化类型pool_type, 池化核大小pool_size, 步长pool_stride,填充pool_padding这些参数得到输出。
输入X和输出Out是NCHW格式,N为batch尺寸,C是通道数,H是特征高度,W是特征宽度。
参数(ksize,strides,paddings)含有两个元素。这两个元素分别代表高度和宽度。输入X的大小和输出Out的大小可能不一致。
例如:
- 输入:
X shape:

输出:
- Out shape:

如果 ceil_mode = false:


如果 ceil_mode = true:


如果 exclusive = false:

如果 exclusive = true:

- 参数:
- input (Variable) - 池化操作的输入张量。输入张量格式为NCHW,N为批尺寸,C是通道数,H是特征高度,W是特征宽度
- pool_size (int|list|tuple) - 池化核的大小。如果它是一个元组或列表,它必须包含两个整数值, (pool_size_Height, pool_size_Width)。若为一个整数,则它的平方值将作为池化核大小,比如若pool_size=2, 则池化核大小为2x2。
- pool_type (string) - 池化类型,可以是“max”对应max-pooling,“avg”对应average-pooling
- pool_stride (int|list|tuple) - 池化层的步长。如果它是一个元组或列表,它将包含两个整数,(pool_stride_Height, pool_stride_Width)。否则它是一个整数的平方值。
- pool_padding (int|list|tuple) - 填充大小。如果它是一个元组或列表,它必须包含两个整数值,(pool_padding_on_Height, pool_padding_on_Width)。否则它是一个整数的平方值。
- global_pooling (bool,默认false)- 是否用全局池化。如果global_pooling = true,
pool_size和pool_padding将被忽略。 - use_cudnn (bool,默认false)- 只在cudnn核中用,需要下载cudnn
- ceil_mode (bool,默认false)- 是否用ceil函数计算输出高度和宽度。默认False。如果设为False,则使用floor函数
- name (str|None) - 该层名称(可选)。若设为None,则自动为该层命名。
- exclusive (bool) - 是否在平均池化模式忽略填充值。默认为True。返回:池化结果
返回类型:变量(Variable)
- 抛出异常:
ValueError- 如果pool_type既不是“max”也不是“avg”ValueError- 如果global_pooling为False并且‘pool_size’为-1ValueError- 如果use_cudnn不是bool值代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name='data', shape=[3, 32, 32], dtype='float32')
- pool2d = fluid.layers.pool2d(
- input=data,
- pool_size=2,
- pool_type='max',
- pool_stride=1,
- global_pooling=False)
pool3d
paddle.fluid.layers.pool3d(input, pool_size=-1, pool_type='max', pool_stride=1, pool_padding=0, global_pooling=False, use_cudnn=True, ceil_mode=False, name=None, exclusive=True)- 函数使用上述输入参数的池化配置,为三维空间添加池化操作
pooling3d操作根据input,pool_type,pool_size,strides和paddings参数计算输出。 输入(X)和输出(输出)采用NCDHW格式,其中N是批量大小,C是通道数,D,H和W分别是特征的深度,高度和宽度。 参数(ksize,strides,paddings)是三个元素。 这三个元素分别代表深度,高度和宽度。 输入(X)大小和输出(Out)大小可能不同。
例如,
输入X形为
 ,输出形为
,输出形为
当ceil_mode = false时,

当ceil_mode = true时,

当exclusive = false时,

当exclusive = true时,

- 参数:
- input (Vairable) - 池化运算的输入张量。输入张量的格式为NCDHW, N是批尺寸,C是通道数,D是特征深度,H是特征高度,W是特征宽度。
- pool_size (int|list|tuple) - 池化窗口的大小。如果为元组类型,那么它应该是由三个整数组成:深度,高度,宽度。如果是int类型,它应该是一个整数的立方。
- pool_type (str) - 池化类型, “max” 对应max-pooling, “avg” 对应average-pooling。
- pool_stride (int|list|tuple) - 池化跨越步长。如果为元组类型,那么它应该是由三个整数组成:深度,高度,宽度。如果是int类型,它应该是一个整数的立方。
- pool_padding (int|list|tuple) - 填充大小。如果为元组类型,那么它应该是由三个整数组成:深度,高度,宽度。如果是int类型,它应该是一个整数的立方。
- global_pooling (bool) - 是否使用全局池化。如果global_pooling = true,
pool_size和pool_padding将被忽略。 - use_cudnn (bool) - 是否用cudnn核,只有在cudnn库安装时有效。
- ceil_mode (bool) - 是否用ceil函数计算输出高度和宽度。默认False。如果设为False,则使用floor函数。
- name (str) - 该层名称(可选)。若为空,则自动为该层命名。
- exclusive (bool) - 是否在平均池化模式忽略填充值。默认为True。返回:pool3d层的输出
返回类型:变量(Variable)
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name='data', shape=[3, 32, 32, 32], dtype='float32')
- pool3d = fluid.layers.pool3d(
- input=data,
- pool_size=2,
- pool_type='max',
- pool_stride=1,
- global_pooling=False)
pow
paddle.fluid.layers.pow(x, factor=1.0, name=None)- 指数激活算子(Pow Activation Operator.)

- 参数
- x (Variable) - Pow operator的输入
- factor (FLOAT|1.0) - Pow的指数因子
- name (str|None) -这个层的名称(可选)。如果设置为None,该层将被自动命名。返回: 输出Pow操作符
返回类型: 输出(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3,10,32,32], dtype="float32")
- y = fluid.layers.pow(x, factor=2.0)
prelu
paddle.fluid.layers.prelu(x, mode, param_attr=None, name=None)- 等式:

共提供三种激活方式:
- all: 所有元素使用同一个alpha值
- channel: 在同一个通道中的元素使用同一个alpha值
- element: 每一个元素有一个独立的alpha值
- 参数:
- x (Variable)- 输入为Tensor。
- mode (string) - 权重共享模式。
- param_attr (ParamAttr|None) - 可学习权重
 的参数属性,可由ParamAttr创建。
的参数属性,可由ParamAttr创建。 - name (str | None)- 这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 输出Tensor与输入shape相同。
返回类型: 变量(Variable)
代码示例:
- import paddle.fluid as fluid
- from paddle.fluid.param_attr import ParamAttr
- x = fluid.layers.data(name="x", shape=[5,10,10], dtype="float32")
- mode = 'channel'
- output = fluid.layers.prelu(
- x,mode,param_attr=ParamAttr(name='alpha'))
psroi_pool
paddle.fluid.layers.psroipool(_input, rois, output_channels, spatial_scale, pooled_height, pooled_width, name=None)- PSROIPool运算
区分位置的感兴趣区域池化方法(Position sensitive region of interest pooling,也称为PSROIPooling)是对输入的 “感兴趣区域”(RoI)执行按位置的average池化,并将N个按位置评分图(score map)和一个由num_rois个感兴趣区域所组成的列表作为输入。
用于R-FCN的PSROIPooling。 有关更多详细信息,请参阅 https://arxiv.org/abs/1605.06409。
- 参数:
- input (Variable) - (Tensor),PSROIPoolOp的输入。 输入张量的格式是NCHW。 其中N是批大小batch_size,C是输入通道的数量,H是输入特征图的高度,W是特征图宽度
- rois (Variable) - 要进行池化的RoI(感兴趣区域)。应为一个形状为(num_rois, 4)的二维LoDTensor,其lod level为1。给出[[x1, y1, x2, y2], …],(x1, y1)为左上角坐标,(x2, y2)为右下角坐标。
- output_channels (integer) - (int),输出特征图的通道数。 对于共C个种类的对象分类任务,output_channels应该是(C + 1),该情况仅适用于分类任务。
- spatial_scale (float) - (float,default 1.0),乘法空间比例因子,用于将ROI坐标从其输入比例转换为池化使用的比例。默认值:1.0
- pooled_height (integer) - (int,默认值1),池化输出的高度。默认值:1
- pooled_width (integer) - (int,默认值1),池化输出的宽度。默认值:1
- name (str,default None) - 此层的名称。返回: (Tensor),PSROIPoolOp的输出是形为 (num_rois,output_channels,pooled_h,pooled_w) 的4-D Tensor。
返回类型: 变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[490, 28, 28], dtype='float32')
- rois = fluid.layers.data(name='rois', shape=[4], lod_level=1, dtype='float32')
- pool_out = fluid.layers.psroi_pool(x, rois, 10, 1.0, 7, 7)
py_func
paddle.fluid.layers.pyfunc(_func, x, out, backward_func=None, skip_vars_in_backward_input=None)- PyFunc运算。
用户可以使用 py_func 在Python端注册operator。 func 的输入 x 是LoDTensor,输出可以是numpy数组或LoDTensor。 Paddle将在前向部分调用注册的 func ,并在反向部分调用 backward_func (如果 backward_func 不是None)。
在调用此函数之前,应正确设置 out 的数据类型和形状。 但是,out 和 x 对应梯度的数据类型和形状将自动推断而出。
backward_func 的输入顺序为:前向输入x,前向输出 out 和反向输入 out 的梯度。 如果 out 的某些变量没有梯度,则输入张量在Python端将为None。
如果in的某些变量没有梯度,则用户应返回None。
此功能还可用于调试正在运行的网络,可以通过添加没有输出的py_func运算,并在func中打印输入x。
- 参数:
- func (callable) - 前向Python函数。
- x (Variable|list(Variable)|tuple(Variable)) - func的输入。
- out (Variable|list(Variable)|tuple(Variable)) - func的输出。 Paddle无法自动推断out的形状和数据类型。 应事先创建
out。 - backward_func (callable|None) - 反向Python函数。 None意味着没有反向计算。 默认None。
- skip_vars_in_backward_input (Variable|list(Variable)|tuple(Variable)) - backward_func输入中不需要的变量。 这些变量必须是x和out中的一个。 如果设置,这些变量将不是backward_func的输入,仅在backward_func不是None时有用。 默认None。返回: 传入的
out
返回类型: out (Variable|list(Variable)|tuple(Variable))
代码示例:
- import paddle.fluid as fluid
- import six
- def create_tmp_var(name, dtype, shape):
- return fluid.default_main_program().current_block().create_var(
- name=name, dtype=dtype, shape=shape)
- # Paddle C++ op提供的tanh激活函数
- # 此处仅采用tanh作为示例展示py_func的使用方法
- def tanh(x):
- return np.tanh(x)
- # 跳过前向输入x
- def tanh_grad(y, dy):
- return np.array(dy) * (1 - np.square(np.array(y)))
- def debug_func(x):
- print(x)
- def simple_net(img, label):
- hidden = img
- for idx in six.moves.range(4):
- hidden = fluid.layers.fc(hidden, size=200)
- new_hidden = create_tmp_var(name='hidden_{}'.format(idx),
- dtype=hidden.dtype, shape=hidden.shape)
- # 用户自定义的前向反向计算
- hidden = fluid.layers.py_func(func=tanh, x=hidden,
- out=new_hidden, backward_func=tanh_grad,
- skip_vars_in_backward_input=hidden)
- # 用户自定义的调试层,可以打印出变量细则
- fluid.layers.py_func(func=debug_func, x=hidden, out=None)
- prediction = fluid.layers.fc(hidden, size=10, act='softmax')
- loss = fluid.layers.cross_entropy(input=prediction, label=label)
- return fluid.layers.mean(loss)
random_crop
paddle.fluid.layers.randomcrop(_x, shape, seed=None)该operator对batch中每个实例进行随机裁剪。这意味着每个实例的裁剪位置不同,裁剪位置由均匀分布随机生成器决定。所有裁剪的实例都具有相同的shape,由参数shape决定。
参数:
- x(Variable) - 一组随机裁剪的实例
- shape(int) - 裁剪实例的形状
- seed(int|变量|None) - 默认情况下,随机种子从randint(-65536,-65536)中取得返回: 裁剪后的batch
代码示例:
- import paddle.fluid as fluid
- img = fluid.layers.data("img", [3, 256, 256])
- cropped_img = fluid.layers.random_crop(img, shape=[3, 224, 224])
rank
paddle.fluid.layers.rank(input)- 排序层
返回张量的维数,一个数据类型为int32的0-D Tensor。
- 参数:
- input (Variable):输入变量返回:输入变量的秩
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- input = layers.data(
- name="input", shape=[3, 100, 100], dtype="float32")
- rank = layers.rank(input) # 4
rank_loss
paddle.fluid.layers.rankloss(_label, left, right, name=None)- RankNet 是一个成对的排序模型,训练样本由一对文档组成:A和B。标签P表示a的排名是否高于B:
P 的取值可为: {0, 1} 或 {0, 0.5, 1}, 其中,0.5表示输入的两文档排序相同。
排序的损失函数有三个输入:left(oi)、right(o_j) 和 label (P{i,j})。输入分别表示RankNet对文档A、B的输出得分和标签p的值。由下式计算输入的排序损失C_{i,j}:

排序损失层的输入带有batch_size (batch_size >= 1)
- 参数:
- label (Variable):A的排名是否高于B
- left (Variable):RankNet对doc A的输出分数
- right (Variable):RankNet对doc B的输出分数
- name (str|None):此层的名称(可选)。如果没有设置,层将自动命名。返回:rank loss的值
返回类型: list
抛出异常: ValueError - label, left, 和right至少有一者不是variable变量类型。
代码示例
- import paddle.fluid as fluid
- label = fluid.layers.data(name="label", shape=[-1, 1], dtype="float32")
- left = fluid.layers.data(name="left", shape=[-1, 1], dtype="float32")
- right = fluid.layers.data(name="right", shape=[-1, 1], dtype="float32")
- out = fluid.layers.rank_loss(label, left, right)
reduce_all
paddle.fluid.layers.reduceall(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量(Tensor)元素的与逻辑。
参数:
- input (Variable):输入变量为Tensor或LoDTensor。
- dim (list | int | None):与逻辑运算的维度。如果为None,则计算所有元素的与逻辑并返回包含单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False):是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量的维度将比输入张量小。 - name (str | None):这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- # x是一个布尔型Tensor,元素如下:
- # [[True, False]
- # [True, True]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- import numpy as np
- fluid.layers.reduce_all(x) # False
- fluid.layers.reduce_all(x, dim=0) # [True, False]
- fluid.layers.reduce_all(x, dim=-1) # [False, True]
- fluid.layers.reduce_all(x, dim=1,
- keep_dim=True) # [[False], [True]]
reduce_any
paddle.fluid.layers.reduceany(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量(Tensor)元素的或逻辑。
参数:
- input (Variable):输入变量为Tensor或LoDTensor。
- dim (list | int | None):或逻辑运算的维度。如果为None,则计算所有元素的或逻辑并返回仅包含单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False):是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量的维度将比输入张量小。 - name (str | None):这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- # x是一个布尔型Tensor,元素如下:
- # [[True, False]
- # [False, False]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- import numpy as np
- fluid.layers.reduce_any(x) # True
- fluid.layers.reduce_any(x, dim=0) # [True, False]
- fluid.layers.reduce_any(x, dim=-1) # [True, False]
- fluid.layers.reduce_any(x, dim=1,
- keep_dim=True) # [[True], [False]]
reduce_max
paddle.fluid.layers.reducemax(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量(Tensor)元素最大值。
参数:
- input (Variable):输入变量为Tensor或LoDTensor。
- dim (list | int | None):函数运算的维度。如果为None,则计算所有元素中的最大值并返回单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False):是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量将比输入少一个维度。 - name (str | None):这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 运算、减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- # x是一个Tensor,元素如下:
- # [[0.2, 0.3, 0.5, 0.9]
- # [0.1, 0.2, 0.6, 0.7]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- x = fluid.layers.data(name='x', shape=[4, 2], dtype='float32')
- fluid.layers.reduce_max(x) # [0.9]
- fluid.layers.reduce_max(x, dim=0) # [0.2, 0.3, 0.6, 0.9]
- fluid.layers.reduce_max(x, dim=-1) # [0.9, 0.7]
- fluid.layers.reduce_max(x, dim=1, keep_dim=True) # [[0.9], [0.7]]
- # y是一个shape为[2, 2, 2]的Tensor,元素如下:
- # [[[1.0, 2.0], [3.0, 4.0]],
- # [[5.0, 6.0], [7.0, 8.0]]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- y = fluid.layers.data(name='y', shape=[2, 2, 2], dtype='float32')
- fluid.layers.reduce_max(y, dim=[1, 2]) # [4.0, 8.0]
- fluid.layers.reduce_max(y, dim=[0, 1]) # [7.0, 8.0]
reduce_mean
paddle.fluid.layers.reducemean(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量(Tensor)元素平均值。
参数:
- input (Variable):输入变量为Tensor或LoDTensor。
- dim (list | int | None):函数运算的维度。如果为None,则对输入的所有元素求平均值并返回单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False):是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量将比输入少一个维度。 - name (str | None):这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 运算、减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- # x是一个Tensor,元素如下:
- # [[0.2, 0.3, 0.5, 0.9]
- # [0.1, 0.2, 0.6, 0.7]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- x = fluid.layers.data(name='x', shape=[4, 2], dtype='float32')
- fluid.layers.reduce_mean(x) # [0.4375]
- fluid.layers.reduce_mean(x, dim=0) # [0.15, 0.25, 0.55, 0.8]
- fluid.layers.reduce_mean(x, dim=-1) # [0.475, 0.4]
- fluid.layers.reduce_mean(x, dim=1, keep_dim=True) # [[0.475], [0.4]]
- # y是一个shape为[2, 2, 2]的Tensor元素如下:
- # [[[1.0, 2.0], [3.0, 4.0]],
- # [[5.0, 6.0], [7.0, 8.0]]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。。
- y = fluid.layers.data(name='y', shape=[2, 2, 2], dtype='float32')
- fluid.layers.reduce_mean(y, dim=[1, 2]) # [2.5, 6.5]
- fluid.layers.reduce_mean(y, dim=[0, 1]) # [4.0, 5.0]
reduce_min
paddle.fluid.layers.reducemin(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量元素的最小值。
参数:
- input (Variable):输入变量为Tensor或LoDTensor。
- dim (list | int | None):函数运算的维度。如果为None,则对输入的所有元素做差并返回单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False):是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量将比输入少一个维度。 - name (str | None):这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 运算、减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- # x是一个Tensor,元素如下:
- # [[0.2, 0.3, 0.5, 0.9]
- # [0.1, 0.2, 0.6, 0.7]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- x = fluid.layers.data(name='x', shape=[4, 2], dtype='float32')
- fluid.layers.reduce_min(x) # [0.1]
- fluid.layers.reduce_min(x, dim=0) # [0.1, 0.2, 0.5, 0.7]
- fluid.layers.reduce_min(x, dim=-1) # [0.2, 0.1]
- fluid.layers.reduce_min(x, dim=1, keep_dim=True) # [[0.2], [0.1]]
- # y是一个shape为[2, 2, 2]的Tensor元素如下:
- # [[[1.0, 2.0], [3.0, 4.0]],
- # [[5.0, 6.0], [7.0, 8.0]]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- y = fluid.layers.data(name='y', shape=[2, 2, 2], dtype='float32')
- fluid.layers.reduce_min(y, dim=[1, 2]) # [1.0, 5.0]
- fluid.layers.reduce_min(y, dim=[0, 1]) # [1.0, 2.0]
reduce_prod
paddle.fluid.layers.reduceprod(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量(Tensor)元素乘积。
参数:
- input (Variable):输入变量为Tensor或LoDTensor。
- dim (list | int | None):函数运算的维度。如果为None,则将输入的所有元素相乘并返回单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False):是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量将比输入少一个维度。 - name (str | None):这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 运算、减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- # x是一个Tensor,元素如下:
- # [[0.2, 0.3, 0.5, 0.9]
- # [0.1, 0.2, 0.6, 0.7]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- x = fluid.layers.data(name='x', shape=[4, 2], dtype='float32')
- fluid.layers.reduce_prod(x) # [0.0002268]
- fluid.layers.reduce_prod(x, dim=0) # [0.02, 0.06, 0.3, 0.63]
- fluid.layers.reduce_prod(x, dim=-1) # [0.027, 0.0084]
- fluid.layers.reduce_prod(x, dim=1,
- keep_dim=True) # [[0.027], [0.0084]]
- # y 是一个shape为[2, 2, 2]的Tensor元素如下:
- # [[[1.0, 2.0], [3.0, 4.0]],
- # [[5.0, 6.0], [7.0, 8.0]]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- y = fluid.layers.data(name='y', shape=[2, 2, 2], dtype='float32')
- fluid.layers.reduce_prod(y, dim=[1, 2]) # [24.0, 1680.0]
- fluid.layers.reduce_prod(y, dim=[0, 1]) # [105.0, 384.0]
reduce_sum
paddle.fluid.layers.reducesum(_input, dim=None, keep_dim=False, name=None)计算给定维度上张量(Tensor)元素之和。
参数:
- input (Variable)- 输入变量为Tensor或LoDTensor。
- dim (list | int | None)- 求和运算的维度。如果为None,则对输入的所有元素求和并返回单个元素的Tensor变量,否则必须在
 范围内。如果
范围内。如果 ,则维度将减小为
,则维度将减小为 。
。 - keep_dim (bool | False)- 是否在输出Tensor中保留减小的维度。除非
keep_dim为true,否则结果张量将比输入少一个维度。 - name (str | None)- 这一层的名称(可选)。如果设置为None,则将自动命名这一层。返回: 运算、减少维度之后的Tensor变量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- # x是一个Tensor,元素如下:
- # [[0.2, 0.3, 0.5, 0.9]
- # [0.1, 0.2, 0.6, 0.7]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- x = fluid.layers.data(name='x', shape=[4, 2], dtype='float32')
- fluid.layers.reduce_sum(x) # [3.5]
- fluid.layers.reduce_sum(x, dim=0) # [0.3, 0.5, 1.1, 1.6]
- fluid.layers.reduce_sum(x, dim=-1) # [1.9, 1.6]
- fluid.layers.reduce_sum(x, dim=1, keep_dim=True) # [[1.9], [1.6]]
- # y 是一个shape为[2, 2, 2]的Tensor元素如下:
- # [[[1, 2], [3, 4]],
- # [[5, 6], [7, 8]]]
- # 接下来的示例中,我们在每处函数调用后面都标注出了它的结果张量。
- y = fluid.layers.data(name='y', shape=[2, 2, 2], dtype='float32')
- fluid.layers.reduce_sum(y, dim=[1, 2]) # [10, 26]
- fluid.layers.reduce_sum(y, dim=[0, 1]) # [16, 20]
relu
paddle.fluid.layers.relu(x, name=None)- Relu接受一个输入数据(张量),输出一个张量。将线性函数y = max(0, x)应用到张量中的每个元素上。

- 参数:
- x (Variable):输入张量。
- name (str|None,默认None) :如果设置为None,该层将自动命名。返回: 与输入形状相同的输出张量。
返回类型: 变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3, 4], dtype="float32")
- output = fluid.layers.relu(x)
relu6
paddle.fluid.layers.relu6(x, threshold=6.0, name=None)- relu6激活算子(Relu6 Activation Operator)

- 参数:
- x (Variable) - Relu6 operator的输入
- threshold (FLOAT|6.0) - Relu6的阈值
- name (str|None) -这个层的名称(可选)。如果设置为None,该层将被自动命名。返回: Relu6操作符的输出
返回类型: 输出(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3,10,32,32], dtype="float32")
- y = fluid.layers.relu6(x, threshold=6.0)
reshape
paddle.fluid.layers.reshape(x, shape, actual_shape=None, act=None, inplace=False, name=None)- 保持输入张量数据不变的情况下,改变张量的形状。
目标形状可由 shape 或 actual_shape 给出。shape 是一个整数列表,而 actual_shape 是一个张量变量。当两个属性同时被指定时,actual_shape 的优先级高于 shape ,但在编译时仍然应该正确地设置 shape 以保证形状推断。
在指定目标shape时存在一些技巧:
- 1. -1表示这个维度的值是从x的元素总数和剩余维度推断出来的。因此,有且只有一个维度可以被设置为-1。
- 2. 0表示实际的维数是从x的对应维数中复制出来的,因此shape中0的索引值不能超过秩(x)。
这里有一些例子来解释它们:
- 1. 给定一个形状为[2,4,6]的三维张量x,目标形状为[6,8], ``reshape`` 将x变换为形状为[6,8]的二维张量,且x的数据保持不变。
- 2. 给定一个形状为[2,4,6]的三维张量x,指定的目标形状为[2,3,-1,2], ``reshape``将x变换为形状为[2,3,4,2]的4- d张量,不改变x的数据。在这种情况下,目标形状的一个维度被设置为-1,这个维度的值是从x的元素总数和剩余维度推断出来的。
- 3. 给定一个形状为[2,4,6]的三维张量x,目标形状为[- 1,0,3,2],整形算子将x变换为形状为[2,4,3,2]的四维张量,使x的数据保持不变。在这种情况下,0意味着实际的维值将从x的对应维数中复制,-1位置的维度由x的元素总数和剩余维度计算得来。
- 参数:
- x (variable) - 输入张量
- shape (list) - 新的形状。新形状最多只能有一个维度为-1。
- actual_shape (variable) - 一个可选的输入。如果提供,则根据
actual_shape进行 reshape,而不是指定shape。也就是说,actual_shape具有比shape更高的优先级。 - act (str) - 对reshpe后的tensor变量执行非线性激活
- inplace (bool) - 如果
inplace为True,则layers.reshape的输入和输出是同一个变量,否则,layers.reshape的输入和输出是不同的变量。请注意,如果x作为多个层的输入,则inplace必须为False。 - name (str) - 可选变量,此层的名称返回:如果
act为None,返回reshape后的tensor变量。如果inplace为False,将返回一个新的Tensor变量,否则,将改变x自身。如果act不是None,则返回激活的张量变量。
抛出异常:TypeError - 如果 actual_shape 既不是变量也不是None
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name='data', shape=[2, 4, 6], dtype='float32')
- reshaped = fluid.layers.reshape(
- x=data, shape=[-1, 0, 3, 2], inplace=True)
resize_bilinear
paddle.fluid.layers.resizebilinear(_input, out_shape=None, scale=None, name=None, actual_shape=None, align_corners=True, align_mode=1)- 根据指定的out_shape执行双线性插值调整输入大小,输出形状按优先级由actual_shape、out_shape和scale指定。
双线性插值是对线性插值的扩展,即二维变量方向上(如h方向和w方向)插值。关键思想是先在一个方向上执行线性插值,然后再在另一个方向上执行线性插值。
详情请参阅 维基百科 。
align_corners和align_mode是可选参数,插值的计算方法可以由它们选择。
- Example:
- For scale:
- if align_corners = True && out_size > 1 :
- scale_factor = (in_size-1.0)/(out_size-1.0)
- else:
- scale_factor = float(in_size/out_size)
- Bilinear interpolation:
- if align_corners = False , align_mode = 0
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = (H_{in}+0.5) * scale_{factor} - 0.5
- W_out = (W_{in}+0.5) * scale_{factor} - 0.5
- else:
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = H_{in} * scale_{factor}
- W_out = W_{in} * scale_{factor}
- 参数:
- input (Variable) - 双线性插值的输入张量,是一个shape为(N x C x h x w)的4d张量。
- out_shape (list|tuple|Variable|None) - 调整双线性层的输出形状,形式为(out_h, out_w)。默认值:None。
- scale (float|None) - 用于输入高度或宽度的乘数因子。out_shape和scale至少要设置一个。out_shape的优先级高于scale。默认值:None。
- name (str|None) - 输出变量名。
- actual_shape (Variable) - 可选输入,用于动态指定输出形状。如果指定actual_shape,图像将根据给定的形状调整大小,而不是根据指定形状的
out_shape和scale进行调整。也就是说,actual_shape具有最高的优先级。如果希望动态指定输出形状,建议使用actual_shape而不是out_shape。在使用actual_shape指定输出形状时,还需要设置out_shape和scale之一,否则在图形构建阶段会出现错误。默认值:None - align_corners (bool)- 一个可选的bool型参数,如果为True,则将输入和输出张量的4个角落像素的中心对齐,并保留角点像素的值。 默认值:True
- align_mode (int)- 双线性插值的可选项。 可以是‘0’代表src_idx = scale *(dst_indx + 0.5)-0.5;可以为‘1’ ,代表src_idx = scale * dst_index。返回: 插值运算的输出张量,其各维度是(N x C x out_h x out_w)
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[3,6,9], dtype="float32")
- out = fluid.layers.resize_bilinear(input, out_shape=[12, 12])
resize_nearest
paddle.fluid.layers.resizenearest(_input, out_shape=None, scale=None, name=None, actual_shape=None, align_corners=True)- 该层对输入进行放缩,在第三维(高度方向)和第四维(宽度方向)进行最邻近插值(nearest neighbor interpolation)操作。输出形状按优先级顺序依据
actual_shape,out_shape和scale而定。
- Example:
- For scale:
- if align_corners = True && out_size > 1 :
- scale_factor = (in_size-1.0)/(out_size-1.0)
- else:
- scale_factor = float(in_size/out_size)
- Nearest neighbor interpolation:
- if align_corners = False
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = \left \lfloor {H_{in} * scale_{}factor}} \right \rfloor
- W_out = \left \lfloor {W_{in} * scale_{}factor}} \right \rfloor
- else:
- align_corners = True
- input : (N,C,H_in,W_in)
- output: (N,C,H_out,W_out) where:
- H_out = round(H_{in} * scale_{factor})
- W_out = round(W_{in} * scale_{factor})
最邻近插值的详细介绍请参照: Wiki Nearest-neighbor interpolation
- 参数:
- input (Variable) – 插值运算的输入张量, 是一个形为 (N,C,H,W) 的四维张量
- out_shape (list|tuple|Variable|None) – 调整最近邻层的输出形状,形式为(out_h, out_w)。默认值:None。
- scale (float|None) – 输入高、宽的乘法器。
out_shape和scale二者至少设置其一。out_shape具有比scale更高的优先级。 默认: None - name (str|None) – 输出变量的命名
- actual_shape (Variable) – 可选输入, 动态设置输出张量的形状。 如果提供该值, 图片放缩会依据此形状进行, 而非依据
out_shape和scale。 即为,actual_shape具有最高的优先级。 如果想动态指明输出形状,推荐使用actual_shape取代out_shape。 当使用actual_shape来指明输出形状,out_shape和scale也应该进行设置, 否则在图形生成阶段将会报错。默认: None - align_corners (bool)- 一个可选的bool型参数,如果为True,则将输入和输出张量的4个角落像素的中心对齐,并保留角点像素的值。 默认值:True返回:插值运算的输出张量,是一个形为 [N,C,H,W] 的四维张量
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[3,6,9], dtype="float32")
- out = fluid.layers.resize_nearest(input, out_shape=[12, 12])
roi_align
paddle.fluid.layers.roialign(_input, rois, pooled_height=1, pooled_width=1, spatial_scale=1.0, sampling_ratio=-1, name=None)- 实现RoIAlign操作。
Region of Interests align(直译:有意义、有价值选区对齐) 用于实现双线性插值,它可以将不均匀大小的输入变为固定大小的特征图(feature map)。
该运算通过 pooled_width 和 pooled_height 将每个推荐区域划分为等大小分块。位置保持不变。
在每个RoI框中,四个常取样位置会通过双线性插值直接计算。输出为这四个位置的平均值从而解决不对齐问题。
- 参数:
- input (Variable) – (Tensor) 该运算的的输入张量,形为(N,C,H,W)。其中 N 为batch大小, C 为输入通道的个数, H 特征高度, W 特征宽度
- rois (Variable) – 待池化的ROIs (Regions of Interest)
- pooled_height (integer) – (默认为1), 池化后的输出高度
- pooled_width (integer) – (默认为1), 池化后的输出宽度
- spatial_scale (float) – (默认为1.0),乘法性质空间标尺因子,池化时,将RoI坐标变换至运算采用的标度
- sampling_ratio (intger) – (默认为-1),插值格中采样点的数目。 如果它 <=0, 它们将自适应
roi_width和pooled_w, 在高度上也是同样的道理。返回:一个形为 (num_rois, channels, pooled_h, pooled_w) 的四维张量
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(
- name='data', shape=[256, 32, 32], dtype='float32')
- rois = fluid.layers.data(
- name='rois', shape=[4], dtype='float32')
- align_out = fluid.layers.roi_align(input=x,
- rois=rois,
- pooled_height=7,
- pooled_width=7,
- spatial_scale=0.5,
- sampling_ratio=-1)
roi_pool
paddle.fluid.layers.roipool(_input, rois, pooled_height=1, pooled_width=1, spatial_scale=1.0)- roi池化是对非均匀大小的输入执行最大池化,以获得固定大小的特征映射(例如7*7)。
该operator有三个步骤:
- 用pooled_width和pooled_height将每个区域划分为大小相等的部分
- 在每个部分中找到最大的值
- 将这些最大值复制到输出缓冲区
Faster-RCNN.使用了roi池化。roi关于roi池化请参考 https://stackoverflow.com/questions/43430056/what-is-roi-layer-in-fast-rcnn
- 参数:
- input (Variable) - 张量,ROIPoolOp的输入。输入张量的格式是NCHW。其中N为batch大小,C为输入通道数,H为特征高度,W为特征宽度
- roi (Variable) - roi区域。
- pooled_height (integer) - (int,默认1),池化输出的高度。默认:1
- pooled_width (integer) - (int,默认1) 池化输出的宽度。默认:1
- spatial_scale (float) - (float,默认1.0),用于将ROI coords从输入比例转换为池化时使用的比例。默认1.0返回: (张量),ROIPoolOp的输出是一个shape为(num_rois, channel, pooled_h, pooled_w)的4d张量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(
- name='x', shape=[8, 112, 112], dtype='float32')
- rois = fluid.layers.data(
- name='roi', shape=[4], lod_level=1, dtype='float32')
- pool_out = fluid.layers.roi_pool(
- input=x,
- rois=rois,
- pooled_height=7,
- pooled_width=7,
- spatial_scale=1.0)
row_conv
paddle.fluid.layers.rowconv(_input, future_context_size, param_attr=None, act=None)- 行卷积(Row-convolution operator)称为超前卷积(lookahead convolution)。下面关于DeepSpeech2的paper中介绍了这个operator
http://www.cs.cmu.edu/~dyogatam/papers/wang+etal.iclrworkshop2016.pdf
双向的RNN在深度语音模型中很有用,它通过对整个序列执行正向和反向传递来学习序列的表示。然而,与单向RNNs不同的是,在线部署和低延迟设置中,双向RNNs具有难度。超前卷积将来自未来子序列的信息以一种高效的方式进行计算,以改进单向递归神经网络。 row convolution operator 与一维序列卷积不同,计算方法如下:
给定输入序列长度为
 的输入序列
的输入序列 和输入维度
和输入维度 ,以及一个大小为
,以及一个大小为 的滤波器
的滤波器 ,输出序列卷积为:
,输出序列卷积为:

- 公式中:
 : 第i行输出变量形为[1, D].
: 第i行输出变量形为[1, D]. : 下文(future context)大小
: 下文(future context)大小 : 第j行输出变量,形为[1,D]
: 第j行输出变量,形为[1,D] : 第(j-i)行参数,其形状为[1,D]。详细请参考 设计文档 。
: 第(j-i)行参数,其形状为[1,D]。详细请参考 设计文档 。
参数:
- input (Variable) – 输入是一个LodTensor,它支持可变时间长度的输入序列。这个LodTensor的内部张量是一个具有形状(T x N)的矩阵,其中T是这个mini batch中的总的timestep,N是输入数据维数。
- future_context_size (int) – 下文大小。请注意,卷积核的shape是[future_context_size + 1, D]。
- param_attr (ParamAttr) – 参数的属性,包括名称、初始化器等。
- act (str) – 非线性激活函数。返回: 输出(Out)是一个LodTensor,它支持可变时间长度的输入序列。这个LodTensor的内部量是一个形状为 T x N 的矩阵,和X的 shape 一样。
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[16],
- dtype='float32', lod_level=1)
- out = fluid.layers.row_conv(input=x, future_context_size=2)
sampled_softmax_with_cross_entropy
paddle.fluid.layers.sampledsoftmax_with_cross_entropy(_logits, label, num_samples, num_true=1, remove_accidental_hits=True, use_customized_samples=False, customized_samples=None, customized_probabilities=None, seed=0)- Sampled Softmax With Cross Entropy Operator
对于较大的输出类,采样的交叉熵损失Softmax被广泛地用作输出层。该运算符为所有示例采样若干个样本,并计算每行采样张量的SoftMax标准化值,然后计算交叉熵损失。
由于此运算符在内部对逻辑执行SoftMax,因此它需要未分级的逻辑。此运算符不应与SoftMax运算符的输出一起使用,因为这样会产生不正确的结果。
对于T真标签(T>=1)的示例,我们假设每个真标签的概率为1/T。对于每个样本,使用对数均匀分布生成S个样本。真正的标签与这些样本连接起来,形成每个示例的T+S样本。因此,假设逻辑的形状是[N x K],样本的形状是[N x(T+S)]。对于每个取样标签,计算出一个概率,对应于Jean et al., 2014 )中的Q(y|x)。
根据采样标签对逻辑进行采样。如果remove_accidental_hits为“真”,如果sample[i, j] 意外匹配“真”标签,则相应的sampled_logits[i, j]减去1e20,使其SoftMax结果接近零。然后用logQ(y|x)减去采样的逻辑,这些采样的逻辑和重新索引的标签被用来计算具有交叉熵的SoftMax。
- 参数:
- logits (Variable)- 非比例对数概率,是一个二维张量,形状为[N x K]。N是批大小,K是类别号。
- label (Variable)- 基本事实,是一个二维张量。label是一个张量
,其形状为[N x T],其中T是每个示例的真实标签数。 - num_samples (int)- 每个示例的数目num_samples应该小于类的数目。
- num_true (int)- 每个训练实例的目标类别总数。
- remove_accidental_hits (bool)- 指示采样时是否删除意外命中的标签。如果为真,如果一个sample[i,j]意外地碰到了真标签,那么相应的sampled_logits[i,j]将被减去1e20,使其SoftMax结果接近零。默认值为True。
- use_customized_samples (bool)- 是否使用自定义样本和可能性对logits进行抽样。
- customized_samples (Variable)- 用户定义的示例,它是一个具有形状[N, T + S]的二维张量。S是num_samples,T是每个示例的真标签数。
- customized_probabilities (Variable)- 用户定义的样本概率,与customized_samples形状相同的二维张量。
- seed (int)- 用于生成随机数的随机种子,在采样过程中使用。默认值为0。返回:交叉熵损失,是一个二维张量,形状为[N x 1]。
返回类型:Variable
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name='data', shape=[256], dtype='float32')
- label = fluid.layers.data(name='label', shape=[5], dtype='int64')
- fc = fluid.layers.fc(input=input, size=100)
- out = fluid.layers.sampled_softmax_with_cross_entropy(
- logits=fc, label=label, num_samples=25)
sampling_id
paddle.fluid.layers.samplingid(_x, min=0.0, max=1.0, seed=0, dtype='float32')sampling_id算子。用于从输入的多项分布中对id进行采样的图层。为一个样本采样一个id。
参数:
- x (Variable)- softmax的输入张量(Tensor)。2-D形状[batch_size,input_feature_dimensions]
- min (Float)- 随机的最小值。(浮点数,默认为0.0)
- max (Float)- 随机的最大值。(float,默认1.0)
- seed (Float)- 用于随机数引擎的随机种子。0表示使用系统生成的种子。请注意,如果seed不为0,则此算子将始终每次生成相同的随机数。(int,默认为0)
- dtype (np.dtype | core.VarDesc.VarType | str)- 输出数据的类型为float32,float_16,int等。返回: Id采样的数据张量。
返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(
- name="X",
- shape=[13, 11],
- dtype='float32',
- append_batch_size=False)
- out = fluid.layers.sampling_id(x)
scale
paddle.fluid.layers.scale(x, scale=1.0, bias=0.0, bias_after_scale=True, act=None, name=None)- 缩放算子
对输入张量应用缩放和偏移加法。
if bias_after_scale = True:

else:

- 参数:
- x (Variable) - (Tensor) 要比例运算的输入张量(Tensor)。
- scale (FLOAT) - 比例运算的比例因子。
- bias (FLOAT) - 比例算子的偏差。
- bias_after_scale (BOOLEAN) - 在缩放之后或之前添加bias。在某些情况下,对数值稳定性很有用。
- act (basestring|None) - 应用于输出的激活函数。
- name (basestring|None)- 输出的名称。返回: 比例算子的输出张量(Tensor)
返回类型: 变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="X", shape=[1, 2, 5, 5], dtype='float32')
- y = fluid.layers.scale(x, scale = 2.0, bias = 1.0)
scatter
paddle.fluid.layers.scatter(input, index, updates, name=None, overwrite=True)- 通过更新输入在第一维度上指定索引位置处的元素来获得输出。

- 参数:
- input (Variable) - 秩> = 1的源输入。
- index (Variable) - 秩= 1的索引输入。 它的dtype应该是int32或int64,因为它用作索引。
- updates (Variable) - scatter 要进行更新的变量。
- name (str | None) - 输出变量名称。 默认None。
- overwrite (bool) - 具有相同索引时更新输出的模式。如果为True,则使用覆盖模式更新相同索引的输出,如果为False,则使用accumulate模式更新相同索引的grad。默认值为True。您可以设置overwrite=False以使用scatter_add。返回:张量变量, 与输入张量的shape相同
返回类型:output(Variable)
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(name='data', shape=[3, 5, 9], dtype='float32', append_batch_size=False)
- index = fluid.layers.data(name='index', shape=[3], dtype='int64', append_batch_size=False)
- updates = fluid.layers.data(name='update', shape=[3, 5, 9], dtype='float32', append_batch_size=False)
- output = fluid.layers.scatter(input, index, updates)
selu
paddle.fluid.layers.selu(x, scale=None, alpha=None, name=None)- 实现Selu运算
有如下等式:

输入 x 可以选择性携带LoD信息。输出和它共享此LoD信息(如果有)。
- 参数:
- x (Variable) – 输入张量
- scale (float, None) – 如果标度没有设置,其默认值为 1.0507009873554804934193349852946。 详情请见: Self-Normalizing Neural Networks
- alpha (float, None) – 如果没有设置改参数, 其默认值为 1.6732632423543772848170429916717。 详情请见: Self-Normalizing Neural Networks
- name (str|None, default None) – 该层命名,若为None则自动为其命名返回:一个形和输入张量相同的输出张量
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name="input", shape=[3, 9, 5], dtype="float32")
- output = fluid.layers.selu(input)
sequence_concat
paddle.fluid.layers.sequenceconcat(_input, name=None)sequence_concat操作通过序列信息连接LoD张量(Tensor)。例如:X1的LoD = [0,3,7],X2的LoD = [0,7,9],结果的LoD为[0,(3 + 7),(7 + 9)],即[0,10,16]。
参数:
- input (list) – 要连接变量的列表
- name (str|None) – 此层的名称(可选)。如果没有设置,该层将被自动命名。返回: 连接好的输出变量。
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[10], dtype='float32')
- y = fluid.layers.data(name='y', shape=[10], dtype='float32')
- out = fluid.layers.sequence_concat(input=[x, y])
sequence_conv
paddle.fluid.layers.sequenceconv(_input, num_filters, filter_size=3, filter_stride=1, padding=None, bias_attr=None, param_attr=None, act=None, name=None)该函数的输入参数中给出了滤波器和步长,通过利用输入以及滤波器和步长的常规配置来为sequence_conv创建操作符。
参数:
- input (Variable) - (LoD张量)输入X是LoD张量,支持可变的时间量的长度输入序列。该LoDTensor的标记张量是一个维度为(T,N)的矩阵,其中T是mini-batch的总时间步数,N是input_hidden_size
- num_filters (int) - 滤波器的数量
- filter_size (int) - 滤波器大小(H和W)
- filter_stride (int) - 滤波器的步长
- padding (bool) - 若为真,添加填充
- bias_attr (ParamAttr|bool|None) - sequence_conv偏离率参数属性。若设为False,输出单元则不加入偏离率。若设为None或ParamAttr的一个属性,sequence_conv将创建一个ParamAttr作为bias_attr。如果未设置bias_attr的初始化函数,则将bias初始化为0.默认:None
- param_attr (ParamAttr|None) - 可学习参数/sequence_conv的权重参数属性。若设置为None或ParamAttr的一个属性,sequence_conv将创建ParamAttr作为param_attr。若未设置param_attr的初始化函数,则用Xavier初始化参数。默认:None
返回:sequence_conv的输出
返回类型:变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[10,10], append_batch_size=False, dtype='float32')
- x_conved = fluid.layers.sequence_conv(x,2)
sequence_enumerate
paddle.fluid.layers.sequenceenumerate(_input, win_size, pad_value=0, name=None)- 为输入索引序列生成一个新序列,该序列枚举输入长度为
win_size的所有子序列。 输入序列和枚举序列第一维上维度相同,第二维是win_size,在生成中如果需要,通过设置pad_value填充。
例子:
- 输入:
- X.lod = [[0, 3, 5]] X.data = [[1], [2], [3], [4], [5]] X.dims = [5, 1]
- 属性:
- win_size = 2 pad_value = 0
- 输出:
- Out.lod = [[0, 3, 5]] Out.data = [[1, 2], [2, 3], [3, 0], [4, 5], [5, 0]] Out.dims = [5, 2]
- 参数:
- input (Variable)- 作为索引序列的输入变量。
- win_size (int)- 枚举所有子序列的窗口大小。
- pad_value (int)- 填充值,默认为0。返回: 枚举序列变量是LoD张量(LoDTensor)。
返回类型: Variable
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(shape[-1, 1], dtype='int32', lod_level=1)
- out = fluid.layers.sequence_enumerate(input=x, win_size=3, pad_value=0)
sequence_expand
paddle.fluid.layers.sequenceexpand(_x, y, ref_level=-1, name=None)- 序列扩张层(Sequence Expand Layer)
将根据指定 y 的 level lod 展开输入变量x,请注意 x 的 lod level 最多为1,而 x 的秩最少为2。当 x 的秩大于2时,它就被看作是一个二维张量。下面的例子将解释 sequence_expand 是如何工作的:
- * 例1
- x is a LoDTensor:
- x.lod = [[2, 2]]
- x.data = [[a], [b], [c], [d]]
- x.dims = [4, 1]
- y is a LoDTensor:
- y.lod = [[2, 2],
- [3, 3, 1, 1]]
- ref_level: 0
- then output is a 1-level LoDTensor:
- out.lod = [[2, 2, 2, 2]]
- out.data = [[a], [b], [a], [b], [c], [d], [c], [d]]
- out.dims = [8, 1]
- * 例2
- x is a Tensor:
- x.data = [[a], [b], [c]]
- x.dims = [3, 1]
- y is a LoDTensor:
- y.lod = [[2, 0, 3]]
- ref_level: -1
- then output is a Tensor:
- out.data = [[a], [a], [c], [c], [c]]
- out.dims = [5, 1]
- 参数:
- x (Variable) - 输入变量,张量或LoDTensor
- y (Variable) - 输入变量,为LoDTensor
- ref_level (int) - x表示的y的Lod层。若设为-1,表示lod的最后一层
- name (str|None) - 该层名称(可选)。如果设为空,则自动为该层命名返回:扩展变量,LoDTensor
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- x = fluid.layers.data(name='x', shape=[10], dtype='float32')
- y = fluid.layers.data(name='y', shape=[10, 20],
- dtype='float32', lod_level=1)
- out = fluid.layers.sequence_expand(x=x, y=y, ref_level=0)
sequence_expand_as
paddle.fluid.layers.sequenceexpand_as(_x, y, name=None)- Sequence Expand As Layer
这一层将根据y的第0级lod扩展输入变量x。当前实现要求输入(Y)的lod层数必须为1,输入(X)的第一维应当和输入(Y)的第0层lod的大小相同,不考虑输入(X)的lod。
以下示例解释sequence_expand如何工作:
- * 例1:
- 给定一维LoDTensor input(X)
- X.data = [[a], [b], [c], [d]]
- X.dims = [4, 1]
- 和 input(Y)
- Y.lod = [[0, 3, 6, 7, 8]]
- ref_level: 0
- 得到1级 LoDTensor
- Out.lod = [[0, 3, 6, 7, 8]]
- Out.data = [[a], [a], [a], [b], [b], [b], [c], [d]]
- Out.dims = [8, 1]
- *例2
- 给定一个 input(X):
- X.data = [[a, b], [c, d], [e, f]]
- X.dims = [3, 2]
- 和 input(Y):
- Y.lod = [[0, 2, 3, 6]]
- ref_level: 0
- 得到输出张量:
- Out.lod = [[0, 2, 3, 6]]
- Out.data = [[a, b], [a, b] [c, d], [e, f], [e, f], [e, f]]
- Out.dims = [6, 2]
- 参数:
- x (Variable) - 输入变量,类型为Tensor或LoDTensor
- y (Variable) - 输入变量,为LoDTensor
- name (str|None) - 该层名称(可选)。如果设为空,则自动为该层命名返回:扩展变量,LoDTensor
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- x = fluid.layers.data(name='x', shape=[10], dtype='float32')
- y = fluid.layers.data(name='y', shape=[10, 20],
- dtype='float32', lod_level=1)
- out = layers.sequence_expand_as(x=x, y=y)
sequence_first_step
paddle.fluid.layers.sequencefirst_step(_input)- 该功能获取序列的第一步
- x是1-level LoDTensor:
- x.lod = [[2, 3, 2]]
- x.data = [1, 3, 2, 4, 6, 5, 1]
- x.dims = [7, 1]
- 输出为张量:
- out.dim = [3, 1]
- with condition len(x.lod[-1]) == out.dims[0]
- out.data = [1, 2, 5], where 1=first(1,3), 2=first(2,4,6), 5=first(5,1)
参数:input (variable)-输入变量,为LoDTensor
返回:序列第一步,为张量
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[7, 1],
- dtype='float32', lod_level=1)
- x_first_step = fluid.layers.sequence_first_step(input=x)
sequence_last_step
paddle.fluid.layers.sequencelast_step(_input)- 该API可以获取序列的最后一步
- x是level-1的LoDTensor:
- x.lod = [[2, 3, 2]]
- x.data = [1, 3, 2, 4, 6, 5, 1]
- x.dims = [7, 1]
- 输出为Tensor:
- out.dim = [3, 1]
- 且 len(x.lod[-1]) == out.dims[0]
- out.data = [3, 6, 1], where 3=last(1,3), 6=last(2,4,6), 1=last(5,1)
参数:input (variable)-输入变量,为LoDTensor
返回:序列的最后一步,为张量
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[7, 1],
- dtype='float32', lod_level=1)
- x_last_step = fluid.layers.sequence_last_step(input=x)
sequence_mask
paddle.fluid.layers.sequencemask(_x, maxlen=None, dtype='int64', name=None)- 该层根据输入
x和maxlen输出一个掩码,数据类型为dtype。
假设x是一个形状为[d_1, d_2,…, d_n]的张量。, y是一个形为[d_1, d_2,… ,d_n, maxlen]的掩码,其中:

- 参数:
- x (Variable) - sequence_mask层的输入张量,其元素是小于maxlen的整数。
- maxlen (int|None) - 序列的最大长度。如果maxlen为空,则用max(x)替换。
- dtype (np.dtype|core.VarDesc.VarType|str) - 输出的数据类型
- name (str|None) - 此层的名称(可选)。如果没有设置,该层将被自动命名。返回: sequence mask 的输出
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- x = fluid.layers.data(name='x', shape=[10], dtype='float32', lod_level=1)
- mask = layers.sequence_mask(x=x)
sequence_pad
paddle.fluid.layers.sequencepad(_x, pad_value, maxlen=None, name=None)- 序列填充操作符(Sequence Pad Operator)
这个操作符将同一batch中的序列填充到一个一致的长度。长度由属性padded_length指定。填充的新元素的值具体由输入 PadValue 指定,并会添加到每一个序列的末尾,使得他们最终的长度保持一致。
以下的例子更清晰地解释此操作符的工作原理:
- 例1:
- 给定 1-level LoDTensor
- input(X):
- X.lod = [[0,2,5]]
- X.data = [a,b,c,d,e]
- input(PadValue):
- PadValue.data = [0]
- 'padded_length'=4
- 得到LoDTensor:
- Out.data = [[a,b,0,0],[c,d,e,0]]
- Length.data = [[2],[3]]
- 例2:
- 给定 1-level LoDTensor
- input(X):
- X.lod = [[0,2,5]]
- X.data = [[a1,a2],[b1,b2],[c1,c2],[d1,d2],[e1,e2]]
- input(PadValue):
- PadValue.data = [0]
- 'padded_length' = -1,表示用最长输入序列的长度(此例中为3)
- 得到LoDTensor:
- Out.data = [[[a1,a2],[b1,b2],[0,0]],[[c1,c2],[d1,d2],[e1,e2]]]
- Length.data = [[2],[3]]
- 例3:
- 给定 1-level LoDTensor
- input(X):
- X.lod = [[0,2,5]]
- X.data = [[a1,a2],[b1,b2],[c1,c2],[d1,d2],[e1,e2]]
- input(PadValue):
- PadValue.data = [p1,p2]
- 'padded_length' = -1,表示用最长输入序列的长度(此例中为3)
- 得到LoDTensor:
- Out.data = [[[a1,a2],[b1,b2],[p1,p2]],[[c1,c2],[d1,d2],[e1,e2]]]
- Length.data = [[2],[3]]
- 参数:
- x (Vairable) - 输入变量,应包含lod信息
- pad_value (Variable) - 变量,存有放入填充步的值。可以是标量或tensor,维度和序列的时间步长相等。如果是标量,则自动广播到时间步长的维度
- maxlen (int,默认None) - 填充序列的长度。可以为空或者任意正整数。当为空时,以序列中最长序列的长度为准,其他所有序列填充至该长度。当是某个特定的正整数,最大长度必须大于最长初始序列的长度
- name (str|None) – 该层的命名(可选项)。 如果为 None, 则自动命名返回:填充序列批(batch)和填充前的初始长度。所有输出序列的长度相等
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- import numpy
- x = fluid.layers.data(name='y', shape=[10, 5],
- dtype='float32', lod_level=1)
- pad_value = fluid.layers.assign(
- input=numpy.array([0.0], dtype=numpy.float32))
- out = fluid.layers.sequence_pad(x=x, pad_value=pad_value)
sequence_pool
paddle.fluid.layers.sequencepool(_input, pool_type, is_test=False, pad_value=0.0)- 该函数为序列的池化添加操作符。将每个实例的所有时间步数特征池化,并用参数中提到的pool_type将特征运用到输入到首部。
支持四种pool_type:
average:

sum:

sqrt:

max:

- x是一级LoDTensor且**pad_value** = 0.0:
- x.lod = [[2, 3, 2, 0]]
- x.data = [1, 3, 2, 4, 6, 5, 1]
- x.dims = [7, 1]
- 输出为张量(Tensor):
- out.dim = [4, 1]
- with condition len(x.lod[-1]) == out.dims[0]
- 对于不同的pool_type:
- average: out.data = [2, 4, 3, 0.0], where 2=(1+3)/2, 4=(2+4+6)/3, 3=(5+1)/2
- sum : out.data = [4, 12, 6, 0.0], where 4=1+3, 12=2+4+6, 6=5+1
- sqrt : out.data = [2.82, 6.93, 4.24, 0.0], where 2.82=(1+3)/sqrt(2),
- 6.93=(2+4+6)/sqrt(3), 4.24=(5+1)/sqrt(2)
- max : out.data = [3, 6, 5, 0.0], where 3=max(1,3), 6=max(2,4,6), 5=max(5,1)
- last : out.data = [3, 6, 1, 0.0], where 3=last(1,3), 6=last(2,4,6), 1=last(5,1)
- first : out.data = [1, 2, 5, 0.0], where 1=first(1,3), 2=first(2,4,6), 5=first(5,1)
- 且以上所有均满足0.0 = **pad_value**
- 参数:
- input (variable) - 输入变量,为LoDTensor
- pool_type (string) - 池化类型。支持average,sum,sqrt和max
- is_test (bool, 默认为 False) - 用于区分训练模式和测试评分模式。默认为False。
- pad_value (float) - 用于填充空输入序列的池化结果。返回:sequence pooling 变量,类型为张量(Tensor)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[7, 1],
- dtype='float32', lod_level=1)
- avg_x = fluid.layers.sequence_pool(input=x, pool_type='average')
- sum_x = fluid.layers.sequence_pool(input=x, pool_type='sum')
- sqrt_x = fluid.layers.sequence_pool(input=x, pool_type='sqrt')
- max_x = fluid.layers.sequence_pool(input=x, pool_type='max')
- last_x = fluid.layers.sequence_pool(input=x, pool_type='last')
- first_x = fluid.layers.sequence_pool(input=x, pool_type='first')
sequence_reshape
paddle.fluid.layers.sequencereshape(_input, new_dim)- Sequence Reshape Layer该层重排输入序列。用户设置新维度。每一个序列的的长度通过原始长度、原始维度和新的维度计算得出。以下实例帮助解释该层的功能
- x是一个LoDTensor:
- x.lod = [[0, 2, 6]]
- x.data = [[1, 2], [3, 4],
- [5, 6], [7, 8],
- [9, 10], [11, 12]]
- x.dims = [6, 2]
- 设置 new_dim = 4
- 输出为LoDTensor:
- out.lod = [[0, 1, 3]]
- out.data = [[1, 2, 3, 4],
- [5, 6, 7, 8],
- [9, 10, 11, 12]]
- out.dims = [3, 4]
目前仅提供1-level LoDTensor,请确保(原长度*原维数)可以除以新的维数,每个序列没有余数。
- 参数:
- input (Variable)-一个2-D LoDTensor,模型为[N,M],维度为M
- new_dim (int)-新维度,输入LoDTensor重新塑造后的新维度返回:根据新维度重新塑造的LoDTensor
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[2, 6], append_batch_size=False, dtype='float32', lod_level=1)
- x_reshaped = fluid.layers.sequence_reshape(input=x, new_dim=4)
sequence_reverse
paddle.fluid.layers.sequencereverse(_x, name=None)- 在第0维上将输入
x的各序列倒序。
- 假设 ``x`` 是一个形为 (5,4) 的LoDTensor, lod信息为 [[0, 2, 5]],其中,
- X.data() = [ [1, 2, 3, 4], [5, 6, 7, 8], # 索引为0,长度为2的序列
- [9, 10, 11, 12], [13, 14, 15, 16], [17, 18, 19, 20] # 索引为1长度为3的序列
输出 Y 与 x 具有同样的维数和LoD信息。 于是有:
- Y.data() = [ [5, 6, 7, 8], [1, 2, 3, 4], # 索引为0,长度为2的逆序列
- [17, 18, 19, 20], [13, 14, 15, 16], [9, 10, 11, 12] # 索引为1,长度为3的逆序列
该运算在建立反dynamic RNN 网络中十分有用。
目前仅支持LoD层次(LoD level)为1的张量倒序。
- 参数:
- x (Variable) – 输入张量
- name (basestring|None) – 输出变量的命名返回:输出LoD张量
返回类型:Variable
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[2, 6], dtype='float32')
- x_reversed = fluid.layers.sequence_reverse(x)
sequence_scatter
paddle.fluid.layers.sequencescatter(_input, index, updates, name=None)- 序列散射层
这个operator将更新张量X,它使用Ids的LoD信息来选择要更新的行,并使用Ids中的值作为列来更新X的每一行。
样例:
- 输入:
- input.data = [[1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
- [1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
- [1.0, 1.0, 1.0, 1.0, 1.0, 1.0]]
- input.dims = [3, 6]
- index.data = [[0], [1], [2], [5], [4], [3], [2], [1], [3], [2], [5], [4]]
- index.lod = [[0, 3, 8, 12]]
- updates.data = [[0.3], [0.3], [0.4], [0.1], [0.2], [0.3], [0.4], [0.0], [0.2], [0.3], [0.1], [0.4]]
- updates.lod = [[ 0, 3, 8, 12]]
- 输出:
- out.data = [[1.3, 1.3, 1.4, 1.0, 1.0, 1.0],
- [1.0, 1.0, 1.4, 1.3, 1.2, 1.1],
- [1.0, 1.0, 1.3, 1.2, 1.4, 1.1]]
- out.dims = X.dims = [3, 6]
- 参数:
- input (Variable) - input 秩(rank) >= 1。
- index (Variable) - LoD Tensor, index 是 sequence scatter op 的输入索引,该函数的input将依据index进行更新。 秩(rank)=1。由于用于索引dtype应该是int32或int64。
- updates (Variable) - 一个 LoD Tensor , update 的值将被 sactter 到输入x。update 的 LoD信息必须与index一致。
- name (str|None) - 输出变量名。默认:None。返回: 输出张量维度应该和输入张量相同
返回类型:Variable
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- input = layers.data( name="x", shape=[3, 6], append_batch_size=False, dtype='float32' )
- index = layers.data( name='index', shape=[1], dtype='int32')
- updates = layers.data( name='updates', shape=[1], dtype='float32')
- output = fluid.layers.sequence_scatter(input, index, updates)
sequence_slice
paddle.fluid.layers.sequenceslice(_input, offset, length, name=None)- 实现Sequence Slice(序列切片)运算
该层从给定序列中截取子序列。截取依据为所给的开始 offset (偏移量) 和子序列长 length 。
仅支持序列数据,LoD level(LoD层次为1)
- 输入变量:
- input.data = [[a1, a2], [b1, b2], [c1, c2], [d1, d2], [e1, e2]],
- input.lod = [[3, 2]],
- input.dims = (5, 2),
- 以及 offset.data = [[0], [1]] and length.data = [[2], [1]],
- 则输出变量为:
- out.data = [[a1, a2], [b1, b2], [e1, e2]],
- out.lod = [[2, 1]],
- out.dims = (3, 2).
注解
input , offset , length 的第一维大小应相同。offset 从0开始。
- 参数:
- input (Variable) – 输入变量 ,承载着完整的序列
- offset (Variable) – 对每个序列切片的起始索引
- length (Variable) – 每个子序列的长度
- name (str|None) – 该层的命名,可选项。 如果None, 则自动命名该层返回:输出目标子序列
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- import numpy as np
- seqs = fluid.layers.data(name='x', shape=[10, 5],
- dtype='float32', lod_level=1)
- offset = fluid.layers.assign(input=np.array([[0, 1]]).astype("int32"))
- length = fluid.layers.assign(input=np.array([[2, 1]]).astype("int32"))
- subseqs = fluid.layers.sequence_slice(input=seqs, offset=offset,
- length=length)
sequence_softmax
paddle.fluid.layers.sequencesoftmax(_input, use_cudnn=False, name=None)- 该函数计算每一个序列所有时间步中的softmax激活函数。每个时间步的维度应为1。
输入张量的形状可为
 或者
或者 ,
, 是所有序列长度之和。
是所有序列长度之和。
对mini-batch的第i序列:

例如,对有3个序列(可变长度)的mini-batch,每个包含2,3,2时间步,其lod为[0,2,5,7],则在
 中进行softmax运算,并且
中进行softmax运算,并且 的结果为7.
的结果为7.
- 参数:
- input (Variable) - 输入变量,为LoDTensor
- use_cudnn (bool) - 是否用cudnn核,仅当下载cudnn库才有效。默认:False
- name (str|None) - 该层名称(可选)。若设为None,则自动为该层命名。默认:None返回:sequence_softmax的输出
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[7, 1],
- dtype='float32', lod_level=1)
- x_sequence_softmax = fluid.layers.sequence_softmax(input=x)
sequence_unpad
paddle.fluid.layers.sequenceunpad(_x, length, name=None)- 实现Sequence Unpad(去除序列填充值)运算
该层从给定序列中删除padding(填充值),并且将该序列转变为未填充时的原序列作为该层的输出,并且实际长度可以在输出的LoD信息中取得。
- 示例:
- 给定输入变量 ``x`` :
- x.data = [[ 1.0, 2.0, 3.0, 4.0, 5.0],
- [ 6.0, 7.0, 8.0, 9.0, 10.0],
- [11.0, 12.0, 13.0, 14.0, 15.0]],
- 其中包含 3 个被填充到长度为5的序列,实际长度由输入变量 ``length`` 指明:
- length.data = [[2], [3], [4]],
- 则去填充(unpad)后的输出变量为:
- out.data = [[1.0, 2.0, 6.0, 7.0, 8.0, 11.0, 12.0, 13.0, 14.0]]
- out.lod = [[2, 3, 4]]
- 参数:
- x (Variable) – 输入变量,承载着多个填充后等长的序列
- length (Variable) – 变量,指明去填充后各个序列所具有的实际长度
- name (str|None) – 可选项,该层名称。 若为 None, 将自动命名该层返回:变量,承载着去填充处理后的序列
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[10, 5], dtype='float32')
- len = fluid.layers.data(name='length', shape=[1], dtype='int64')
- out = fluid.layers.sequence_unpad(x=x, length=len)
shape
paddle.fluid.layers.shape(input)- shape层。
获得输入变量的形状。
- 参数:
- input (Variable)- 输入的变量返回: (Tensor),输入变量的形状
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name="input", shape=[3, 100, 100], dtype="float32")
- out = fluid.layers.shape(input)
shuffle_channel
paddle.fluid.layers.shufflechannel(_x, group, name=None)- Shuffle Channel 运算(通道重排运算)
该算子将输入 x 的通道混洗重排。 它将每个组中的输入通道分成 group 个子组,并通过逐个从每个子组中选择元素来获得新的顺序。
请参阅 https://arxiv.org/pdf/1707.01083.pdf
- 输入一个形为 (N, C, H, W) 的4-D tensor:
- input.shape = (1, 4, 2, 2)
- input.data =[[[[0.1, 0.2],
- [0.2, 0.3]],
- [[0.3, 0.4],
- [0.4, 0.5]],
- [[0.5, 0.6],
- [0.6, 0.7]],
- [[0.7, 0.8],
- [0.8, 0.9]]]]
- 指定组数 group: 2
- 可得到与输入同形的输出 4-D tensor:
- out.shape = (1, 4, 2, 2)
- out.data = [[[[0.1, 0.2],
- [0.2, 0.3]],
- [[0.5, 0.6],
- [0.6, 0.7]],
- [[0.3, 0.4],
- [0.4, 0.5]],
- [[0.7, 0.8],
- [0.8, 0.9]]]]
- 参数:
- x (Variable) – 输入张量变量。 应是形状为[N,C,H,W]的4-D张量
- group (int) – 表示子组的数目,它应该整除通道数。返回:通道混洗结果是一个张量变量,其形状和类型与输入相同。
返回类型:输出(Variable)
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name='input', shape=[4,2,2], dtype='float32')
- out = fluid.layers.shuffle_channel(x=input, group=2)
sigmoid_cross_entropy_with_logits
paddle.fluid.layers.sigmoidcross_entropy_with_logits(_x, label, ignore_index=-100, name=None, normalize=False)- 在类别不相互独立的分类任务中,该函数可以衡量按元素的可能性误差。可以这么认为,为单一数据点预测标签,它们之间不是完全互斥的关系。例如,一篇新闻文章可以同时关于政治,科技,体育或者同时不包含这些内容。
逻辑loss可通过下式计算:

已知:

代入最开始的式子,

为了计算稳定性,防止
 溢出,当
溢出,当 时,loss将采用以下公式计算:
时,loss将采用以下公式计算:

输入 X 和 label 都可以携带LoD信息。然而输出仅采用输入 X 的LoD。
- 参数:
x (Variable) - (Tensor, 默认 Tensor
),形为 N x D 的二维张量,N为batch大小,D为类别数目。该输入是一个由先前运算得出的logit组成的张量。logit是未标准化(unscaled)的log概率, 公式为 
label (Variable) - (Tensor, 默认 Tensor
) 具有和X相同类型,相同形状的二维张量。该输入张量代表了每个logit的可能标签 - ignore_index (int) - (int,默认kIgnoreIndex)指定被忽略的目标值,它不会影响输入梯度
- name (basestring|None) - 输出的名称
- normalize (bool) - 如果为true,则将输出除以除去ignore_index对应目标外的目标数返回: (Tensor, 默认Tensor<float>), 形为 N x D 的二维张量,其值代表了按元素的逻辑loss
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- input = fluid.layers.data(
- name='data', shape=[10], dtype='float32')
- label = fluid.layers.data(
- name='data', shape=[10], dtype='float32')
- loss = fluid.layers.sigmoid_cross_entropy_with_logits(
- x=input,
- label=label,
- ignore_index=-1,
- normalize=True) # or False
- # loss = fluid.layers.reduce_sum(loss) # loss之和
sign
paddle.fluid.layers.sign(x)此函数返回x中每个元素的正负号:1代表正,-1代表负,0代表零。
参数:
- x (Variable|numpy.ndarray) – 输入张量。返回:输出正负号张量,和x有着相同的形状和数据类型。
返回类型:Variable
代码示例
- # [1, 0, -1]
- import paddle.fluid as fluid
- data = fluid.layers.sign(np.array([3, 0, -2]))
similarity_focus
paddle.fluid.layers.similarityfocus(_input, axis, indexes, name=None)- 实现SimilarityFocus(相似度聚焦)运算
通过以下三种方式,该层生成一个和输入 input 同形的mask(掩码):
- 根据
axis和indexes提取一个三维张量,第一维为batch大小。例如,如果axis=1, indexes=[a], 将得到矩阵 T=X[:, a, :, :] 。该例中,如果输入X的形为 (BatchSize, A, B, C) ,则输出张量T的形为 (BatchSize, B, C) 。 - 对于每一个索引,在输出T中找到最大值。所以同一行、同一列最多只有一个数字,这意味着如果在第i行,第j列中找到最大值,那么在相应行、列中的其他数值都将被忽略。然后再在剩余的数值中找到下一个最大值。显然,将会产生 min(B,C)个数字,并把三维相似聚焦掩码张量相应位置的元素置为1,其余则置为0。对每个索引按元素进行or运算。
- 将这个三维相似度聚焦mask调整、适配于输入
input的形状请参照 Similarity Focus Layer 。
- 例如 :
- 给定四维张量 x 形为 (BatchSize, C, A, B), 其中C 为通道Channel数目,
- 特征图(feature map)的形为(A,B):
- x.shape = (2, 3, 2, 2)
- x.data = [[[[0.8, 0.1],
- [0.4, 0.5]],
- [[0.9, 0.7],
- [0.9, 0.9]],
- [[0.8, 0.9],
- [0.1, 0.2]]],
- [[[0.2, 0.5],
- [0.3, 0.4]],
- [[0.9, 0.7],
- [0.8, 0.4]],
- [[0.0, 0.2],
- [0.4, 0.7]]]]
- 给定轴: 1 (即channel轴)
- 给定索引: [0]
- 于是我们得到一个与输入同形的四维输出张量:
- out.shape = (2, 3, 2, 2)
- out.data = [[[[1.0, 0.0],
- [0.0, 1.0]],
- [[1.0, 0.0],
- [0.0, 1.0]],
- [[1.0, 0.0],
- [0.0, 1.0]]],
- [[[0.0, 1.0],
- [1.0, 0.0]],
- [[0.0, 1.0],
- [1.0, 0.0]],
- [[0.0, 1.0],
- [1.0, 0.0]]]]
- 参数:
- input (Variable) – 输入张量(默认类型为float)。应为一个四维张量,形为[BatchSize, A, B, C]
- axis (int) – 指明要选择的轴。 可能取值为 1, 2 或 3.
- indexes (list) – 指明选择维度的索引列表返回:一个和输入张量同形、同类型的张量变量
返回类型:Variable
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(
- name='data', shape=[-1, 3, 2, 2], dtype='float32')
- fluid.layers.similarity_focus(input=data, axis=1, indexes=[0])
slice
paddle.fluid.layers.slice(input, axes, starts, ends)- slice算子。
沿多个轴生成输入张量的切片。与numpy类似: https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html Slice使用 axes 、 starts 和 ends 属性来指定轴列表中每个轴的起点和终点维度,它使用此信息来对输入数据张量切片。如果向 starts 或 ends 传递负值,则表示该维度结束之前的元素数目。如果传递给 starts 或 end 的值大于n(此维度中的元素数目),则表示n。当切片一个未知数量的唯独时,建议传入INT_MAX. axes 的大小必须和 starts 和 ends 的相等。以下示例将解释切片如何工作:
- 案例1:
- 给定:
- data=[[1,2,3,4],[5,6,7,8],]
- axes=[0,1]
- starts=[1,0]
- ends=[2,3]
- 则:
- result=[[5,6,7],]
- 案例2:
- 给定:
- data=[[1,2,3,4],[5,6,7,8],]
- starts=[0,1]
- ends=[-1,1000]
- 则:
- result=[[2,3,4],]
- 参数:
- input (Variable)- 提取切片的数据张量(Tensor)。
- axes (List)- (list
)开始和结束的轴适用于。它是可选的。如果不存在,将被视为[0,1,…,len(starts)- 1]。 - starts (List)- (list
)在轴上开始相应轴的索引。 - ends (List)- (list
)在轴上结束相应轴的索引。 返回: 切片数据张量(Tensor).
返回类型: 输出(Variable)。
代码示例:
- import paddle.fluid as fluid
- starts = [1, 0, 2]
- ends = [3, 3, 4]
- axes = [0, 1, 2]
- input = fluid.layers.data(
- name="input", shape=[3, 4, 5, 6], dtype='float32')
- out = fluid.layers.slice(input, axes=axes, starts=starts, ends=ends)
smooth_l1
paddle.fluid.layers.smoothl1(_x, y, inside_weight=None, outside_weight=None, sigma=None)该layer计算变量
x和y的smooth L1 loss,它以x和y的第一维大小作为批处理大小。对于每个实例,按元素计算smooth L1 loss,然后计算所有loss。输出变量的形状是[batch_size, 1]参数:
- x (Variable) - rank至少为2的张量。输入x的smmoth L1 loss 的op,shape为[batch_size, dim1,…],dimN]。
- y (Variable) - rank至少为2的张量。与
x形状一致的的smooth L1 loss op目标值。 - inside_weight (Variable|None) - rank至少为2的张量。这个输入是可选的,与x的形状应该相同。如果给定,
(x - y)的结果将乘以这个张量元素。 - outside_weight (变量|None) - 一个rank至少为2的张量。这个输入是可选的,它的形状应该与
x相同。如果给定,那么 smooth L1 loss 就会乘以这个张量元素。 - sigma (float|None) - smooth L1 loss layer的超参数。标量,默认值为1.0。返回: smooth L1 loss, shape为 [batch_size, 1]
返回类型: Variable
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[128], dtype='float32')
- label = fluid.layers.data(
- name='label', shape=[100], dtype='float32')
- fc = fluid.layers.fc(input=data, size=100)
- out = fluid.layers.smooth_l1(x=fc, y=label)
soft_relu
paddle.fluid.layers.softrelu(_x, threshold=40.0, name=None)- SoftRelu 激活函数

- 参数:
- x (variable) - SoftRelu operator的输入
- threshold (FLOAT|40.0) - SoftRelu的阈值
- name (str|None) - 该层的名称(可选)。如果设置为None,该层将被自动命名代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name=”x”, shape=[2,3,16,16], dtype=”float32”)
- y = fluid.layers.soft_relu(x, threshold=20.0)
softmax
paddle.fluid.layers.softmax(input, use_cudnn=False, name=None, axis=-1)- softmax操作符的输入是任意阶的张量,输出张量和输入张量的维度相同。
输入变量的 axis 维会被排列到最后一维。然后逻辑上将输入张量压平至二维矩阵。矩阵的第二维(行数)和输入张量的 axis 维相同。第一维(列数)是输入张量除最后一维之外的所有维长度乘积。对矩阵的每一行来说,softmax操作将含有任意实数值的K维向量(K是矩阵的宽度,也就是输入张量 axis 维度的大小)压缩成K维含有取值为[0,1]中实数的向量,并且这些值和为1。
softmax操作符计算k维向量输入中所有其他维的指数和指数值的累加和。维的指数比例和所有其他维的指数值之和作为softmax操作符的输出。
对矩阵中的每行i和每列j有:

- 参数:
- input (Variable) - 输入变量
- use_cudnn (bool) - 是否用cudnn核,只有在cudnn库安装时有效。为了数学稳定性,默认该项为False。
- name (str|None) - 该层名称(可选)。若为空,则自动为该层命名。默认:None
- axis (Variable) - 执行softmax计算的维度索引,应该在
 范围内,其中rank是输入变量的秩。 默认值:-1。返回: softmax输出
范围内,其中rank是输入变量的秩。 默认值:-1。返回: softmax输出
返回类型:变量(Variable)
代码示例
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[2], dtype='float32')
- fc = fluid.layers.fc(input=x, size=10)
- # 在第二维执行softmax
- softmax = fluid.layers.softmax(input=fc, axis=1)
- # 在最后一维执行softmax
- softmax = fluid.layers.softmax(input=fc, axis=-1)
softmax_with_cross_entropy
paddle.fluid.layers.softmaxwith_cross_entropy(_logits, label, soft_label=False, ignore_index=-100, numeric_stable_mode=True, return_softmax=False, axis=-1)- 使用softmax的交叉熵在输出层已被广泛使用。该函数计算输入张量在axis轴上的softmax标准化值,而后计算交叉熵。通过此种方式,可以得到更具数字稳定性的梯度值。
因为该运算是在内部进行logit上的softmax运算,所以它需要未标准化(unscaled)的logit。该运算不应该对softmax运算的输出进行操作,否则会得出错误结果。
当 soft_label 为 False 时,该运算接受互斥的硬标签,batch中的每一个样本都以为1的概率分类到一个类别中,并且仅有一个标签。
涉及到的等式如下:
1.硬标签,即 one-hot label, 每个样本仅可分到一个类别

2.软标签,每个样本可能被分配至多个类别中

3.如果 numeric_stable_mode 为真,在通过softmax和标签计算交叉熵损失前, softmax 首先经由下式计算得出:

- 参数:
- logits (Variable) - 未标准化(unscaled)对数概率的输入张量。
- label (Variable) - 真实值张量。如果
soft_label为True,则该参数是一个和logits形状相同的的Tensor。如果 soft_label为False,label是一个在axis维上形为1,其它维上与logits形对应相同的Tensor。 - soft_label (bool) - 是否将输入标签当作软标签。默认为False。
- ignore_index (int) - 指明要无视的目标值,使之不对输入梯度有贡献。仅在
soft_label为False时有效,默认为kIgnoreIndex。 - numeric_stable_mode (bool) – 标志位,指明是否使用一个具有更佳数学稳定性的算法。仅在
soft_label为 False的GPU模式下生效。若soft_label为 True 或者执行场所为CPU, 算法一直具有数学稳定性。 注意使用稳定算法时速度可能会变慢。默认为 True。 - return_softmax (bool) – 标志位,指明是否额外返回一个softmax值, 同时返回交叉熵计算结果。默认为False。
- axis (int) – 执行softmax计算的维度索引。 它应该在范围
 中,而
中,而 是输入logits的秩。 默认值:-1。
是输入logits的秩。 默认值:-1。
- 返回:
- 如果
return_softmax为 False,则返回交叉熵损失 - 如果
return_softmax为 True,则返回元组 (loss, softmax) ,其中softmax和输入logits形状相同;除了axis维上的形为1,其余维上交叉熵损失和输入logits形状相同返回类型:变量或者两个变量组成的元组
- 如果
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[128], dtype='float32')
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- fc = fluid.layers.fc(input=data, size=100)
- out = fluid.layers.softmax_with_cross_entropy(
- logits=fc, label=label)
space_to_depth
paddle.fluid.layers.spaceto_depth(_x, blocksize, name=None)- 给该函数一个
blocksize值,可以对形为[batch, channel, height, width]的输入LoD张量进行space_to_depth(广度至深度)运算。
该运算对成块的空间数据进行重组,形成深度。确切地说,该运算输出一个输入LoD张量的拷贝,其高度,宽度维度上的值移动至通道维度上。
blocksize 参数指明了数据块大小。
重组时,依据 blocksize , 生成形为
 的输出:
的输出:
该运算适用于在卷积间重放缩激励函数,并保持所有的数据。
- 在各位置上,不重叠的,大小为
的块重组入深度depth- 输出张量的深度为
- 输入各个块中的Y,X坐标变为输出张量通道索引的高序部位
- channel可以被blocksize的平方整除
- 高度,宽度可以被blocksize整除


- 参数:
- x (variable) – 输入LoD张量
- blocksize (variable) – 在每个特征图上选择元素时采用的块大小,应该 > 2返回:输出LoD tensor
返回类型:Variable
- 抛出异常:
TypeError-blocksize必须是long类型代码示例
- import paddle.fluid as fluid
- import numpy as np
- data = fluid.layers.data(
- name='data', shape=[1, 4, 2, 2], dtype='float32', append_batch_size=False)
- space_to_depthed = fluid.layers.space_to_depth(
- x=data, blocksize=2)
- exe = fluid.Executor(fluid.CUDAPlace(0))
- data_np = np.arange(0,16).reshape((1,4,2,2)).astype('float32')
- out_main = exe.run(fluid.default_main_program(),
- feed={'data': data_np},
- fetch_list=[space_to_depthed])
spectral_norm
paddle.fluid.layers.spectralnorm(_weight, dim=0, power_iters=1, eps=1e-12, name=None)- Spectral Normalization Layer
该层计算了fc、conv1d、conv2d、conv3d层的权重参数的谱正则值,其参数应分别为2-D, 3-D, 4-D, 5-D。计算结果如下。
步骤1:生成形状为[H]的向量U,以及形状为[W]的向量V,其中H是输入权重的第 dim 个维度,W是剩余维度的乘积。
步骤2: power_iters 应该是一个正整数,用U和V迭代计算 power_iters 轮。

步骤3:计算 sigma(mathbf{W}) 并权重值归一化。

可参考: Spectral Normalization
- 参数:
- weight (Variable)-spectral_norm算子的输入权重张量,可以是2-D, 3-D, 4-D, 5-D张量,它是fc、conv1d、conv2d、conv3d层的权重。
- dim (int)-将输入(weight)重塑为矩阵之前应排列到第一个的维度索引,如果input(weight)是fc层的权重,则应设置为0;如果input(weight)是conv层的权重,则应设置为1,默认为0。
- power_iters (int)-将用于计算spectral norm的功率迭代次数,默认值1
- eps (float)-epsilon用于计算规范中的数值稳定性
- name (str)-此层的名称,可选。返回:谱正则化后权重参数的张量变量
返回类型:Variable
代码示例:
- import paddle.fluid as fluid
- weight = fluid.layers.data(name='weight', shape=[2, 8, 32, 32], append_batch_size=False, dtype='float32')
- x = fluid.layers.spectral_norm(weight=weight, dim=1, power_iters=2)
split
paddle.fluid.layers.split(input, num_or_sections, dim=-1, name=None)将输入张量分解成多个子张量
参数:
- input (Variable)-输入变量,类型为Tensor或者LoDTensor
- num_or_sections (int|list)-如果num_or_sections是整数,则表示张量平均划分为的相同大小子张量的数量。如果num_or_sections是一列整数,列表的长度代表子张量的数量,整数依次代表子张量的dim维度的大小
- dim (int)-将要划分的维。如果dim<0,划分的维为rank(input)+dim
- name (str|None)-该层名称(可选)。如果设置为空,则自动为该层命名返回:一列分割张量
返回类型:列表(Variable)
代码示例:
- import paddle.fluid as fluid
- # 输入是维为[-1, 3,9,5]的张量:
- input = fluid.layers.data(
- name="input", shape=[3, 9, 5], dtype="float32")
- x0, x1, x2 = fluid.layers.split(x, num_or_sections=3, dim=2)
- # x0.shape [-1, 3, 3, 5]
- # x1.shape [-1, 3, 3, 5]
- # x2.shape [-1, 3, 3, 5]
- x0, x1, x2 = fluid.layers.split(input, num_or_sections=[2, 3, 4], dim=2)
- # x0.shape [-1, 3, 2, 5]
- # x1.shape [-1, 3, 3, 5]
- # x2.shape [-1, 3, 4, 5]
square_error_cost
paddle.fluid.layers.squareerror_cost(_input, label)- 方差估计层(Square error cost layer)
该层接受输入预测值和目标值,并返回方差估计
对于预测值X和目标值Y,公式为:

- 在以上等式中:
- X : 输入预测值,张量(Tensor)
- Y : 输入目标值,张量(Tensor)
- Out : 输出值,维度和X的相同
- 参数:
- input (Variable) - 输入张量(Tensor),带有预测值
- label (Variable) - 标签张量(Tensor),带有目标值返回:张量变量,存储输入张量和标签张量的方差
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- y = fluid.layers.data(name='y', shape=[1], dtype='float32')
- y_predict = fluid.layers.data(name='y_predict', shape=[1], dtype='float32')
- cost = fluid.layers.square_error_cost(input=y_predict, label=y)
squeeze
paddle.fluid.layers.squeeze(input, axes, name=None)- 向张量维度中移除单维输入。传入用于压缩的轴。如果未提供轴,所有的单一维度将从维中移除。如果选择的轴的形状条目不等于1,则报错。
- 例如:
- 例1:
- 给定
- X.shape = (1,3,1,5)
- axes = [0]
- 得到
- Out.shape = (3,1,5)
- 例2:
- 给定
- X.shape = (1,3,1,5)
- axes = []
- 得到
- Out.shape = (3,5)
- 参数:
- input (Variable)-将要压缩的输入变量
- axes (list)-一列整数,代表压缩的维
- name (str|None)-该层名称返回:输出压缩的变量
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- x = fluid.layers.data(name='x', shape=[5, 1, 10])
- y = fluid.layers.sequeeze(input=x, axes=[1])
stack
paddle.fluid.layers.stack(x, axis=0)- 实现了stack层。
沿 axis 轴,该层对输入 x 进行stack运算。
输入 x 可以是单个变量, 或是多个变量组成的列表或元组。如果 x 是一个列表或元组, 那么这些变量必须同形。 假设每个输入的形都为
 , 则输出变量的形为
, 则输出变量的形为 。 如果
。 如果 axis < 0, 则将其取代为 。 如果
。 如果 axis 为 None, 则认为它是 0。
例如:
- 例1:
- 输入:
- x[0].data = [ [1.0 , 2.0 ] ]
- x[0].dims = [1, 2]
- x[1].data = [ [3.0 , 4.0 ] ]
- x[1].dims = [1, 2]
- x[2].data = [ [5.0 , 6.0 ] ]
- x[2].dims = [1, 2]
- 参数:
- axis = 0
- 输出:
- Out.data =[ [ [1.0, 2.0] ],
- [ [3.0, 4.0] ],
- [ [5.0, 6.0] ] ]
- Out.dims = [3, 1, 2]
- 例2:
- 如果
- x[0].data = [ [1.0 , 2.0 ] ]
- x[0].dims = [1, 2]
- x[1].data = [ [3.0 , 4.0 ] ]
- x[1].dims = [1, 2]
- x[2].data = [ [5.0 , 6.0 ] ]
- x[2].dims = [1, 2]
- 参数:
- axis = 1 or axis = -2
- 输出:
- Out.data =[ [ [1.0, 2.0]
- [3.0, 4.0]
- [5.0, 6.0] ] ]
- Out.dims = [1, 3, 2]
参数:
- x (Variable|list(Variable)|tuple(Variable)) – 输入变量
- axis (int|None) – 对输入进行stack运算所在的轴
返回: 经stack运算后的变量
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- x1 = layers.data(name='x1', shape=[1, 2], dtype='int32')
- x2 = layers.data(name='x2', shape=[1, 2], dtype='int32')
- data = layers.stack([x1,x2])
stanh
paddle.fluid.layers.stanh(x, scale_a=0.6666666666666666, scale_b=1.7159, name=None)- STanh 激活算子(STanh Activation Operator.)

- 参数:
- x (Variable) - STanh operator的输入
- scale_a (FLOAT|2.0 / 3.0) - 输入的a的缩放参数
- scale_b (FLOAT|1.7159) - b的缩放参数
- name (str|None) - 这个层的名称(可选)。如果设置为None,该层将被自动命名。返回: STanh操作符的输出
返回类型: 输出(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3,10,32,32], dtype="float32")
- y = fluid.layers.stanh(x, scale_a=0.67, scale_b=1.72)
sum
paddle.fluid.layers.sum(x)- sum算子。
该算子对输入张量求和。所有输入都可以携带LoD(详细程度)信息,但是输出仅与第一个输入共享LoD信息。
- 参数:
- x (Variable)- (vector
)sum算子的输入张量(Tensor)。 返回: (Tensor)求和算子的输出张量。
- x (Variable)- (vector
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- input0 = fluid.layers.data(name="input0", shape=[13, 11], dtype='float32')
- input1 = layers.data(name="input1", shape=[13, 11], dtype='float32')
- out = fluid.layers.sum([input0,input1])
swish
paddle.fluid.layers.swish(x, beta=1.0, name=None)- Swish 激活函数

- 参数:
- x (Variable) - Swish operator 的输入
- beta (浮点|1.0) - Swish operator 的常量beta
- name (str|None) - 这个层的名称(可选)。如果设置为None,该层将被自动命名。返回: Swish operator 的输出
返回类型: output(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name="x", shape=[3,10,32,32], dtype="float32")
- y = fluid.layers.swish(x, beta=2.0)
teacher_student_sigmoid_loss
paddle.fluid.layers.teacherstudent_sigmoid_loss(_input, label, soft_max_up_bound=15.0, soft_max_lower_bound=-15.0)- Teacher Student Log Loss Layer(教师–学生对数损失层)
此图层接受输入预测和目标标签,并返回teacher_student损失。

- 参数:
- input (Variable|list) – 形状为[N x 1]的二维张量,其中N是批大小batch size。 该输入是由前一个运算计算而得的概率。
- label (Variable|list) – 具有形状[N x 1]的二维张量的真实值,其中N是批大小batch_size。
- soft_max_up_bound (float) – 若input > soft_max_up_bound, 输入会被向下限制。默认为15.0
- soft_max_lower_bound (float) – 若input < soft_max_lower_bound, 输入将会被向上限制。默认为-15.0返回:具有形状[N x 1]的2-D张量,teacher_student_sigmoid_loss。
返回类型:变量
代码示例:
- import paddle.fluid as fluid
- batch_size = 64
- label = fluid.layers.data(
- name="label", shape=[batch_size, 1], dtype="int64", append_batch_size=False)
- similarity = fluid.layers.data(
- name="similarity", shape=[batch_size, 1], dtype="float32", append_batch_size=False)
- cost = fluid.layers.teacher_student_sigmoid_loss(input=similarity, label=label)
temporal_shift
paddle.fluid.layers.temporalshift(_x, seg_num, shift_ratio=0.25, name=None)- Temporal Shift Operator
此运算符计算输入(x)的时间移位特征。
输入(x)的形状应为[N*T, C, H, W],N是批大小,T是 seg_num 指定的时间段号,C是通道号,H和W是特征的高度和宽度。
时间偏移计算如下:
步骤1:将输入(X)重塑为[N、T、C、H、W]。
步骤2:填充0到第二个(T)尺寸的变形结果,填充宽度每边为1,填充结果的形状为[N,T+2,C,H,W]。
步骤3:假设shift_ratio为1/4,切片填充结果如下:

步骤4:沿第3(C)维连接三个切片,并将结果重塑为[N*T, C, H, W]。
有关时间移动的详细信息,请参阅文件: Temporal Shift Module
- 参数:
- x (Variable) – 时移算符的输入张量。这是一个4维张量,形状为[N*T,C,H,W]。N为批量大小,T为时间段数,C为信道数,H为特征高度,W为特征宽度
- seg_num (int) – 时间段编号,这应该是一个正整数。
- shift_ratio (float) – 通道的移位比、通道的第一个
shift_ratio部分沿时间维度移动-1,通道的第二个shift_ratio部分沿时间维度移动1。默认值0.25 - name (str, default None) – 该层名称返回:时间移位结果是一个与输入形状和类型相同的张量变量
返回类型:out(Variable)
抛出异常: TypeError – seg_num 必须是int类型
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name='input', shape=[4,2,2], dtype='float32')
- out = fluid.layers.temporal_shift(x=input, seg_num=2, shift_ratio=0.2)
topk
paddle.fluid.layers.topk(input, k, name=None)- 这个算子用于查找最后一维的前k个最大项,返回它们的值和索引。
如果输入是(1-D Tensor),则找到向量的前k最大项,并以向量的形式输出前k最大项的值和索引。values[j]是输入中第j最大项,其索引为indices[j]。如果输入是更高阶的张量,则该operator会基于最后一维计算前k项
例如:
- 如果:
- input = [[5, 4, 2, 3],
- [9, 7, 10, 25],
- [6, 2, 10, 1]]
- k = 2
- 则:
- 第一个输出:
- values = [[5, 4],
- [10, 25],
- [6, 10]]
- 第二个输出:
- indices = [[0, 1],
- [2, 3],
- [0, 2]]
- 参数:
- input (Variable)-输入变量可以是一个向量或者更高阶的张量
- k (int|Variable)-在输入最后一维中寻找的前项数目
- name (str|None)-该层名称(可选)。如果设为空,则自动为该层命名。默认为空返回:含有两个元素的元组。元素都是变量。第一个元素是最后维切片的前k项。第二个元素是输入最后维里值索引
返回类型:元组[变量]
抛出异常: ValueError - 如果k<1或者k不小于输入的最后维
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- input = layers.data(name="input", shape=[13, 11], dtype='float32')
- top5_values, top5_indices = fluid.layers.topk(input, k=5)
transpose
paddle.fluid.layers.transpose(x, perm, name=None)- 根据perm对输入矩阵维度进行重排。
返回张量(tensor)的第i维对应输入维度矩阵的perm[i]。
- 参数:
- x (Variable) - 输入张量(Tensor)
- perm (list) - 输入维度矩阵的转置
- name (str) - 该层名称(可选)返回: 转置后的张量(Tensor)
返回类型:变量(Variable)
代码示例:
- # 请使用 append_batch_size=False 来避免
- # 在数据张量中添加多余的batch大小维度
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[5, 10, 15],
- dtype='float32', append_batch_size=False)
- x_transposed = fluid.layers.transpose(x, perm=[1, 0, 2])
tree_conv
paddle.fluid.layers.treeconv(_nodes_vector, edge_set, output_size, num_filters=1, max_depth=2, act='tanh', param_attr=None, bias_attr=None, name=None)- 基于树结构的卷积Tree-Based Convolution运算。
基于树的卷积是基于树的卷积神经网络(TBCNN,Tree-Based Convolution Neural Network)的一部分,它用于对树结构进行分类,例如抽象语法树。 Tree-Based Convolution提出了一种称为连续二叉树的数据结构,它将多路(multiway)树视为二叉树。 提出基于树的卷积论文: https://arxiv.org/abs/1409.5718v1
- 参数:
- nodes_vector (Variable) – (Tensor) 树上每个节点的特征向量(vector)。特征向量的形状必须为[max_tree_node_size,feature_size]
- edge_set (Variable) – (Tensor) 树的边。边必须带方向。边集的形状必须是[max_tree_node_size,2]
- output_size (int) – 输出特征宽度
- num_filters (int) – filter数量,默认值1
- max_depth (int) – filter的最大深度,默认值2
- act (str) – 激活函数,默认 tanh
- param_attr (ParamAttr) – filter的参数属性,默认None
- bias_attr (ParamAttr) – 此层bias的参数属性,默认None
- name (str) – 此层的名称(可选)。如果设置为None,则将自动命名层,默认为None返回: (Tensor)子树的特征向量。输出张量的形状是[max_tree_node_size,output_size,num_filters]。输出张量可以是下一个树卷积层的新特征向量
返回类型:out(Variable)
代码示例:
- import paddle.fluid as fluid
- # 10 代表数据集的最大节点大小max_node_size,5 代表向量宽度
- nodes_vector = fluid.layers.data(name='vectors', shape=[10, 5], dtype='float32')
- # 10 代表数据集的最大节点大小max_node_size, 2 代表每条边连接两个节点
- # 边必须为有向边
- edge_set = fluid.layers.data(name='edge_set', shape=[10, 2], dtype='float32')
- # 输出的形状会是[None, 10, 6, 1],
- # 10 代表数据集的最大节点大小max_node_size, 6 代表输出大小output size, 1 代表 1 个filter
- out_vector = fluid.layers.tree_conv(nodes_vector, edge_set, 6, 1, 2)
- # reshape之后, 输出张量output tensor为下一个树卷积的nodes_vector
- out_vector = fluid.layers.reshape(out_vector, shape=[-1, 10, 6])
- out_vector_2 = fluid.layers.tree_conv(out_vector, edge_set, 3, 4, 2)
- # 输出tensor也可以用来池化(论文中称为global pooling)
- pooled = fluid.layers.reduce_max(out_vector, dims=2) # 全局池化
uniform_random_batch_size_like
paddle.fluid.layers.uniformrandom_batch_size_like(_input, shape, dtype='float32', input_dim_idx=0, output_dim_idx=0, min=-1.0, max=1.0, seed=0)- uniform_random_batch_size_like算子。
此算子使用与输入张量(Tensor)相同的batch_size初始化张量(Tensor),并使用从均匀分布中采样的随机值。
- 参数:
- input (Variable)- 其input_dim_idx’th维度指定batch_size的张量(Tensor)。
- shape (元组|列表)- 输出的形状。
- input_dim_idx (Int)- 默认值0.输入批量大小维度的索引。
- output_dim_idx (Int)- 默认值0.输出批量大小维度的索引。
- min (Float)- (默认 1.0)均匀随机的最小值。
- max (Float)- (默认 1.0)均匀随机的最大值。
- seed (Int)- (int,default 0)用于生成样本的随机种子。0表示使用系统生成的种子。注意如果seed不为0,则此算子将始终每次生成相同的随机数。
- dtype (np.dtype | core.VarDesc.VarType | str) - 数据类型:float32,float_16,int等。返回: 指定形状的张量(Tensor)将使用指定值填充。
返回类型: Variable
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- input = fluid.layers.data(name="input", shape=[13, 11], dtype='float32')
- out = fluid.layers.uniform_random_batch_size_like(input, [-1, 11])
unsqueeze
paddle.fluid.layers.unsqueeze(input, axes, name=None)向张量shape中插入一个维度。该接口接受axes列表,来指定要插入的维度位置。相应维度变化可以在输出变量中axes指定的索引位置上体现。
比如:
- 给定一个张量,例如维度为[3,4,5]的张量,使用 axes列表为[0,4]来unsqueeze它,则输出维度为[1,3,4,5,1]
- 参数:
- input (Variable)- 未压缩的输入变量
- axes (list)- 一列整数,代表要插入的维数
- name (str|None) - 该层名称返回:输出未压缩变量
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[5, 10])
- y = fluid.layers.unsequeeze(input=x, axes=[1])
unstack
paddle.fluid.layers.unstack(x, axis=0, num=None)- 实现了unstack层。
沿 axis 轴,该层对输入 x 进行unstack运算。
如果 axis <0,则将其以
 代之。
代之。
如果 num 为 None,则它可以从 x.shape[axis] 中推断而来。
如果 x.shape[axis] <= 0或者Unknown, 则抛出异常 ValueError 。
- 参数:
- x (Variable|list(Variable)|tuple(Variable)) – 输入变量
- axis (int|None) – 对输入进行unstack运算所在的轴
- num (int|None) - 输出变量的数目返回: 经unstack运算后的变量
返回类型: list(Variable)
代码示例:
- import paddle.fluid as fluid
- x = fluid.layers.data(name='x', shape=[5, 10], dtype='float32')
- y = fluid.layers.unstack(x, axis=1)
warpctc
paddle.fluid.layers.warpctc(input, label, blank=0, norm_by_times=False, use_cudnn=False)该操作符集成了 开源Warp-CTC库 ,计算基于神经网络的时序类分类(CTC)损失。原生softmax激活函数集成到Wrap-CTC库中,操作符也可称作含CTC的softmax,将输入张量每一行的值正则化。
参数:
- input (Variable) - 变长序列的非尺度化概率,是一个含LoD信息的二维张量。shape为[Lp,num_classes+1],Lp是所有输出序列长度之和,num_classes是实际类别数。(不包括空白标签)
- label (Variable) - 变长序列中正确标记的数据,是一个含LoD信息的二维张量。shape为[Lg,1],Lg是所有标签长度之和
- blank (int,默认0) - 基于神经网络的时序类分类(CTC)损失的空白标签索引,在半开区间间隔内[0,num_classes+1]
- norm_by_times (bool,默认false) - 是否利用时间步长(即序列长度)的数量对梯度进行正则化。如果warpctc层后面跟着mean_op则无需对梯度正则化。
- use_cudnn (bool, 默认false) - 是否使用cudnn返回:基于神经网络的时序类分类(CTC)损失,是一个shape为[batch_size,1]的二维张量
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- label = fluid.layers.data(name='label', shape=[11, 8],
- dtype='float32', lod_level=1)
- predict = fluid.layers.data(name='predict', shape=[11, 1],
- dtype='float32')
- cost = fluid.layers.warpctc(input=predict, label=label)
where
paddle.fluid.layers.where(condition)- 返回一个秩为2的int64型张量,指定condition中真实元素的坐标。
输出的第一维是真实元素的数量,第二维是condition的秩(维数)。如果没有真实元素,则将生成空张量。
- 参数:
- condition (Variable) - 秩至少为1的布尔型张量。返回:存储一个二维张量的张量变量
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- import numpy as np
- # condition为张量[True, False, True]
- out = fluid.layers.where(condition) # [[0], [2]]
- # condition为张量[[True, False], [False, True]]
- out = fluid.layers.where(condition) # [[0, 0], [1, 1]]
- # condition为张量[False, False, False]
- out = fluid.layers.where(condition) # [[]]
