 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 学习率调度器
学习率调度器
当我们使用诸如梯度下降法等方式来训练模型时,一般会兼顾训练速度和损失(loss)来选择相对合适的学习率。但若在训练过程中一直使用一个学习率,训练集的损失下降到一定程度后便不再继续下降,而是在一定范围内震荡。其震荡原理如下图所示,即当损失函数收敛到局部极小值附近时,会由于学习率过大导致更新步幅过大,每步参数更新会反复越过极小值而出现震荡。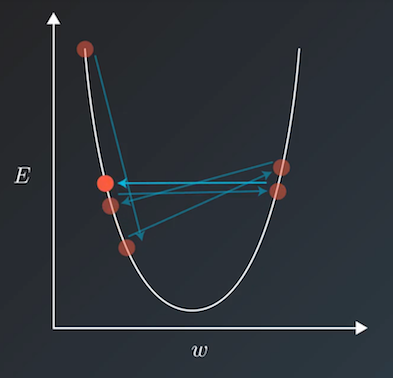 学习率调度器定义了常用的学习率衰减策略来动态生成学习率,学习率衰减函数以epoch或step为参数,返回一个随训练逐渐减小的学习率,从而兼顾降低训练时间和在局部极小值能更好寻优两个方面。
学习率调度器定义了常用的学习率衰减策略来动态生成学习率,学习率衰减函数以epoch或step为参数,返回一个随训练逐渐减小的学习率,从而兼顾降低训练时间和在局部极小值能更好寻优两个方面。
下面介绍学习率调度器中相关的Api:
noam_decay: 诺姆衰减,相关算法请参考 《Attention Is All You Need》 。相关API Reference请参考 noam_decayexponential_decay: 指数衰减,即每次将当前学习率乘以给定的衰减率得到下一个学习率。相关API Reference请参考 exponential_decaynatural_exp_decay: 自然指数衰减,即每次将当前学习率乘以给定的衰减率的自然指数得到下一个学习率。相关API Reference请参考 natural_exp_decayinverse_time_decay: 逆时间衰减,即得到的学习率与当前衰减次数成反比。相关API Reference请参考 inverse_time_decaypolynomial_decay: 多项式衰减,即得到的学习率为初始学习率和给定最终学习之间由多项式计算权重定比分点的插值。相关API Reference请参考 polynomial_decaypiecewise_decay: 分段衰减,即由给定step数分段呈阶梯状衰减,每段内学习率相同。相关API Reference请参考 piecewise_decayappend_LARS: 通过Layer-wise Adaptive Rate Scaling算法获得学习率,相关算法请参考 《Train Feedfoward Neural Network with Layer-wise Adaptive Rate via Approximating Back-matching Propagation》 。相关API Reference请参考 cn_api_fluid_layers_append_LARScosine_decay: 余弦衰减,即学习率随step数变化呈余弦函数。相关API Reference请参考 cosine_decaylinear_lr_warmup: 学习率随step数线性增加到指定学习率。相关API Reference请参考 linear_lr_warmup
