 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- control_flow
- array_length
- array_read
- array_write
- create_array
- DynamicRNN
- equal
- greater_equal
- greater_than
- IfElse
- increment
- is_empty
- less_equal
- less_than
- not_equal
- reorder_lod_tensor_by_rank
- StaticRNN
- Switch
- While
control_flow
array_length
paddle.fluid.layers.arraylength(_array)- 得到输入LoDTensorArray的长度
此功能用于查找输入数组LOD_TENSOR_ARRAY的长度。
- 相关API:
- array_read
- array_write
- While
- 参数:
- array (LOD_TENSOR_ARRAY)-输入数组,用来计算数组长度返回:输入数组LoDTensorArray的长度
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- tmp = fluid.layers.zeros(shape=[10], dtype='int32')
- i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=10)
- arr = fluid.layers.array_write(tmp, i=i)
- arr_len = fluid.layers.array_length(arr)
array_read
paddle.fluid.layers.arrayread(_array, i)- 此函数用于读取数据,数据以LOD_TENSOR_ARRAY数组的形式读入
- Given:
- array = [0.6,0.1,0.3,0.1]
- And:
- I=2
- Then:
- output = 0.3
- 参数:
- array (Variable|list)-输入张量,存储要读的数据
- i (Variable|list)-输入数组中数据的索引返回:张量类型的变量,已有数据写入
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- array = fluid.layers.create_array(dtype='float32')
- i = fluid.layers.fill_constant(shape=[1],dtype='int64',value=10)
- item = fluid.layers.array_read(array, i)
array_write
paddle.fluid.layers.arraywrite(_x, i, array=None)该函数将给定的输入变量(即
x)写入一个作为输出的LOD_TENSOR_ARRAY变量的某一指定位置中,这一位置由数组下标(即i)指明。 如果LOD_TENSOR_ARRAY(即array)未指定(即为None值), 一个新的LOD_TENSOR_ARRAY将会被创建并作为结果返回。参数:
- x (Variable|list) – 待从中读取数据的输入张量(tensor)
- i (Variable|list) – 输出结果
LOD_TENSOR_ARRAY的下标, 该下标指向输入张量x写入输出数组的位置 - array (Variable|list) – 会被输入张量
x写入的输出结果LOD_TENSOR_ARRAY。如果该项值为None, 一个新的LOD_TENSOR_ARRAY将会被创建并作为结果返回返回: 输入张量x所写入的输出结果LOD_TENSOR_ARRAY
返回类型: 变量(Variable)
代码示例
- import paddle.fluid as fluid
- tmp = fluid.layers.zeros(shape=[10], dtype='int32')
- i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=10)
- arr = fluid.layers.array_write(tmp, i=i)
create_array
paddle.fluid.layers.createarray(_dtype)创建LoDTensorArray数组。它主要用于实现RNN与array_write, array_read和While。
参数:
- dtype (int |float) — lod_tensor_array中存储元素的数据类型。返回: lod_tensor_array, 元素数据类型为dtype。
返回类型: Variable。
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.create_array(dtype='float32')
DynamicRNN
- class
paddle.fluid.layers.DynamicRNN(name=None) - 动态RNN可以处理一批序列数据,每个样本序列的长度可以不同。这个API自动批量处理它们。
必须设置输入lod,请参考 lod_tensor
动态RNN将按照timesteps展开开序列。用户需要在with block中定义如何处理处理每个timestep。
memory用于缓存分段数据。memory的初始值可以是零,也可以是其他变量。
动态RNN可以将多个变量标记为其输出。使用drnn()获得输出序列。
注解
目前不支持在DynamicRNN中任何层上配置 is_sparse = True
代码示例
- import paddle.fluid as fluid
- sentence = fluid.layers.data(name='sentence', shape=[1], dtype='int64', lod_level=1)
- embedding = fluid.layers.embedding(input=sentence, size=[65536, 32], is_sparse=True)
- drnn = fluid.layers.DynamicRNN()
- with drnn.block():
- word = drnn.step_input(embedding)
- prev = drnn.memory(shape=[200])
- hidden = fluid.layers.fc(input=[word, prev], size=200, act='relu')
- drnn.update_memory(prev, hidden) # set prev to hidden
- drnn.output(hidden)
- # 获得上一个timestep的rnn,该值是一个编码后的结果
- rnn_output = drnn()
- last = fluid.layers.sequence_last_step(rnn_output)
stepinput(_x, level=0)将序列标记为动态RNN输入。
参数:
- x (Variable) - 含lod信息的输入序列
- level (int) - 用于拆分步骤的LOD层级,默认值0返回:当前的输入序列中的timestep。
staticinput(_x)将变量标记为RNN输入。输入不会分散到timestep中。为可选项。
参数:
- x (Variable) - 输入序列返回:可以访问的RNN的输入变量。
代码示例
- import paddle.fluid as fluid
- sentence = fluid.layers.data(name='sentence', dtype='float32', shape=[32], lod_level=1)
- encoder_proj = fluid.layers.data(name='encoder_proj', dtype='float32', shape=[32], lod_level=1)
- decoder_boot = fluid.layers.data(name='boot', dtype='float32', shape=[10], lod_level=1)
- drnn = fluid.layers.DynamicRNN()
- with drnn.block():
- current_word = drnn.step_input(sentence)
- encoder_word = drnn.static_input(encoder_proj)
- hidden_mem = drnn.memory(init=decoder_boot, need_reorder=True)
- fc_1 = fluid.layers.fc(input=encoder_word, size=30, bias_attr=False)
- fc_2 = fluid.layers.fc(input=current_word, size=30, bias_attr=False)
- decoder_inputs = fc_1 + fc_2
- h, _, _ = fluid.layers.gru_unit(input=decoder_inputs, hidden=hidden_mem, size=30)
- drnn.update_memory(hidden_mem, h)
- out = fluid.layers.fc(input=h, size=10, bias_attr=True, act='softmax')
- drnn.output(out)
- rnn_output = drnn()
block()用户在RNN中定义operators的block。
memory(init=None, shape=None, value=0.0, need_reorder=False, dtype='float32')- 为动态rnn创建一个memory 变量。
如果 init 不是None, memory 将由这个变量初始化。参数 need_reorder 用于将memory重新排序作为输入变量。当memory初始化依赖于输入样本时,应该将其设置为True。
代码示例
- import paddle.fluid as fluid
- sentence = fluid.layers.data(name='sentence', shape=[32], dtype='float32', lod_level=1)
- boot_memory = fluid.layers.data(name='boot', shape=[10], dtype='float32', lod_level=1)
- drnn = fluid.layers.DynamicRNN()
- with drnn.block():
- word = drnn.step_input(sentence)
- memory = drnn.memory(init=boot_memory, need_reorder=True)
- hidden = fluid.layers.fc(input=[word, memory], size=10, act='tanh')
- drnn.update_memory(ex_mem=memory, new_mem=hidden)
- drnn.output(hidden)
- rnn_output = drnn()
否则,如果已经设置 shape 、 value 、 dtype ,memory将被 value 初始化
代码示例
- import paddle.fluid as fluid
- sentence = fluid.layers.data(name='sentence', dtype='float32', shape=[32], lod_level=1)
- drnn = fluid.layers.DynamicRNN()
- with drnn.block():
- word = drnn.step_input(sentence)
- memory = drnn.memory(shape=[10], dtype='float32', value=0)
- hidden = fluid.layers.fc(input=[word, memory], size=10, act='tanh')
- drnn.update_memory(ex_mem=memory, new_mem=hidden)
- drnn.output(hidden)
- rnn_output = drnn()
- 参数:
- init (Variable|None) – 初始化的Variable
- shape (list|tuple) – memory shape,形状不包含batch_size
- value (float) – 初始化的值
- need_reorder (bool) – memory初始化依赖于输入样本时设置为True
- dtype (str|numpy.dtype) – 初始化memory的数据类型返回:memory Variable
updatememory(_ex_mem, new_mem)将内存从
ex_mem更新到new_mem。注意,ex_mem和new_mem的shape和数据类型必须相同。参数:
- ex_mem (memory Variable)- memory 变量(Variable)
- new_mem (memory Variable)- RNN块中生成的平坦变量(plain variable)返回:None
output(*outputs)标记RNN输出变量。
参数:
- *outputs - 输出变量。返回:None
equal
paddle.fluid.layers.equal(x, y, cond=None)- equal该层返回
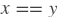 按逐元素运算而得的真值。
按逐元素运算而得的真值。
- 参数:
- x (Variable)-equal的第一个操作数
- y (Variable)-equal的第二个操作数
- cond (Variable|None)-输出变量(可选),用来存储equal的结果返回:张量类型的变量,存储equal的输出结果
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- label = fluid.layers.data(name="label", shape=[3,10,32,32], dtype="float32")
- limit = fluid.layers.data(name="limit", shape=[3,10,32,32], dtype="float32")
- less = fluid.layers.equal(x=label,y=limit)
greater_equal
paddle.fluid.layers.greaterequal(_x, y, cond=None)- 该层逐元素地返回
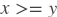 的逻辑值,和重载算子 >= 相同。
的逻辑值,和重载算子 >= 相同。
- 参数:
- x (Variable) - greater_equal 的第一个操作数
- y (Variable) - greater_equal 的第二个操作数
- cond (Variable|None) - 可选的输出变量,存储 greater_equal 的结果返回:存储 greater_equal 的输出的张量变量。
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- out = fluid.layers.greater_equal(x=label, y=limit)
greater_than
paddle.fluid.layers.greaterthan(_x, y, cond=None)- 该层逐元素地返回
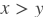 的逻辑值,和重载算子 > 相同。
的逻辑值,和重载算子 > 相同。
- 参数:
- x (Variable) - greater_than 的第一个操作数
- y (Variable) - greater_than 的第二个操作数
- cond (Variable|None) - 可选的输出变量,存储 greater_than 的结果返回:存储 greater_than 的输出的张量变量。
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- out = fluid.layers.greater_than(x=label, y=limit)
IfElse
- class
paddle.fluid.layers.IfElse(cond, name=None) if-else控制流。
参数:
- cond (Variable)-用于比较的条件
- Name (str,默认为空(None))-该层名称代码示例:
- import paddle.fluid as fluid
- image = fluid.layers.data(name="X", shape=[2, 5, 5], dtype='float32')
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- limit = fluid.layers.fill_constant_batch_size_like(
- input=label, dtype='int64', shape=[1], value=5.0)
- cond = fluid.layers.less_than(x=label, y=limit)
- ie = fluid.layers.IfElse(cond)
- with ie.true_block():
- true_image = ie.input(image)
- hidden = fluid.layers.fc(input=true_image, size=100, act='tanh')
- prob = fluid.layers.fc(input=hidden, size=10, act='softmax')
- ie.output(prob)
- with ie.false_block():
- false_image = ie.input(image)
- hidden = fluid.layers.fc(
- input=false_image, size=200, act='tanh')
- prob = fluid.layers.fc(input=hidden, size=10, act='softmax')
- ie.output(prob)
- prob = ie()
increment
paddle.fluid.layers.increment(x, value=1.0, in_place=True)- 该函数为输入
x增加value大小,value即函数中待传入的参数。该函数默认直接在原变量x上进行运算。
注解
x 中元素个数必须为1
- 参数:
- x (Variable|list) – 含有输入值的张量(tensor)
- value (float) – 需要增加在
x变量上的值 - in_place (bool) – 判断是否在x变量本身执行操作,True原地执行,False时,返回增加后的副本返回: 每个元素增加后的对象
返回类型:变量(variable)
代码示例
- import paddle.fluid as fluid
- data = fluid.layers.data(name='data', shape=[1], dtype='float32',
- append_batch_size=False)
- data = fluid.layers.increment(x=data, value=3.0, in_place=True)
is_empty
paddle.fluid.layers.isempty(_x, cond=None)测试变量是否为空
参数:
- x (Variable)-测试的变量
- cond (Variable|None)-输出参数。返回给定x的测试结果,默认为空(None)返回:布尔类型的标量。如果变量x为空则值为真
返回类型:变量(Variable)
抛出异常:TypeError-如果input不是变量或cond类型不是变量
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[4, 32, 32], dtype="float32")
- res = fluid.layers.is_empty(x=input)
- # or:
- # fluid.layers.is_empty(x=input, cond=res)
less_equal
paddle.fluid.layers.lessequal(_x, y, cond=None)- 该层逐元素地返回
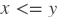 的逻辑值,和重载算子 <= 相同。
的逻辑值,和重载算子 <= 相同。
- 参数:
- x (Variable) - less_equal 的第一个操作数
- y (Variable) - less_equal 的第二个操作数
- cond (Variable|None) - 可选的输出变量,存储 less_equal 的结果返回:存储 less_equal 的输出的张量变量。
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- out = fluid.layers.less_equal(x=label, y=limit)
less_than
paddle.fluid.layers.lessthan(_x, y, force_cpu=None, cond=None)- 该函数按元素出现顺序依次在X,Y上操作,并返回
Out,它们三个都是n维tensor(张量)。其中,X、Y可以是任何类型的tensor,Out张量的各个元素可以通过
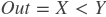 计算得出。
计算得出。
- 参数:
- x (Variable) –
less_than运算的左操作数 - y (Variable) –
less_than运算的右操作数 - force_cpu (BOOLEAN) – 值True则强制将输出变量写入CPU内存中。否则,将其写入目前所在的运算设备上。默认为True
- cond (Variable|None) – 可选的用于存储
lessthan输出结果的变量,为None则由函数自动生成Out变量返回: n维bool型tensor,其中各个元素可以通过 _Out=X<Y 计算得出
- x (Variable) –
代码示例:
- import paddle.fluid as fluid
- label = fluid.layers.data(name='y', shape=[1], dtype='int64')
- limit = fluid.layers.fill_constant(shape=[1], dtype='int64', value=5)
- cond = fluid.layers.less_than(x=label, y=limit)
not_equal
paddle.fluid.layers.notequal(_x, y, cond=None)- 该层逐元素地返回
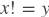 的逻辑值,和重载算子 != 相同。
的逻辑值,和重载算子 != 相同。
- 参数:
- x (Variable) - not_equal 的第一个操作数
- y (Variable) - not_equal 的第二个操作数
- cond (Variable|None) - 可选的输出变量,存储 not_equal 的结果返回:存储 not_equal 的输出的张量变量。
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- out = fluid.layers.not_equal(x=label, y=limit)
paddle.fluid.layers.Print(input, first_n=-1, message=None, summarize=-1, print_tensor_name=True, print_tensor_type=True, print_tensor_shape=True, print_tensor_lod=True, print_phase='both')- Print操作命令
该操作命令创建一个打印操作,打印正在访问的张量。
封装传入的张量,以便无论何时访问张量,都会打印信息message和张量的当前值。
- 参数:
- input (Variable)-将要打印的张量
- summarize (int)-打印张量中的元素数目,如果值为-1则打印所有元素
- message (str)-字符串类型消息,作为前缀打印
- first_n (int)-只记录first_n次数
- print_tensor_name (bool)-打印张量名称
- print_tensor_type (bool)-打印张量类型
- print_tensor_shape (bool)-打印张量维度
- print_tensor_lod (bool)-打印张量lod
- print_phase (str)-打印的阶段,包括
forward,backward和both.若设置为backward或者both,则打印输入张量的梯度。返回:输出张量
返回类型:变量(Variable)
注解
输入和输出是两个不同的变量,在接下来的过程中,你应该使用输出变量而非输入变量,否则打印层将失去输出层前的信息。
代码示例:
- import paddle.fluid as fluid
- input = fluid.layers.data(name="input", shape=[4, 32, 32], dtype="float32")
- input = fluid.layers.Print(input, message = "The content of input layer:")
- # value = some_layer(...)
- # Print(value, summarize=10,
- # message="The content of some_layer: ")
reorder_lod_tensor_by_rank
paddle.fluid.layers.reorderlod_tensor_by_rank(_x, rank_table)- 函数参数
X是由多个序列(sequence)组成的的一个数据批(batch)。rank_table存储着batch中序列的重新排列规则。该算子(operator)根据rank_table中提供的规则信息来实现对X的重新排列。
- 例如:
- 假设在 RankTable 中存储的序列索引为 [3,0,2,1], X 将会被这样被重新排列:
- X 中的第四个序列(即索引为3的序列,后面以此类推)会变成排列后的batch中的第一个,紧接着就是原来batch中的第一个元素,第三个元素,和第二个元素。
- 简言之,若有原batch:X = [Seq0, Seq1, Seq2, Seq3] 且 RankTable 中的索引为 [3,0,2,1],那么输出即为 Out = [Seq3, Seq0, Seq2, Seq1] ,它携带着新的LoD信息。
- 如果 X 的LoD信息是空的,这表明 X 不是序列型数据。这和由多个定长为1的序列组成的batch是相同的情况。此时,该函数将对 X 中的切片(slice) 在第一轴(axis)上按 rank_table 里的规则加以排列。
- 例如,现有 X = [Slice0, Slice1, Slice2, Slice3] ,并且它LoD信息为空,在 RankTable 索引为[3, 0, 2, 1]。则 Out = [Slice3, Slice0, Slice2, Slice1] ,并且不在其中追加LoD信息。
- 注意,该operator对 ``X`` 进行的排序所依据的 ``LoDRankTable`` 不一定是在 ``X`` 的基础上得出来的。它可以由其他不同的序列得出,并由该operator依据这个 ``LoDRankTable`` 来对 ``X`` 排序。
- 参数:
- x(Variable) - (LoDTensor),待根据提供的
RankTable进行排序的LoD tensor - rank_table(Variable) - 变量返回: 重新排列后的LoDTensor
- x(Variable) - (LoDTensor),待根据提供的
返回类型: out(Variable)
代码示例:
- import paddle.fluid as fluid
- data_desc = (['input', [9], 0], ['ref', [5], 1])
- data = fluid.layers.data(name=data_desc[0][0], shape=data_desc[0][1])
- rank_data = fluid.layers.data(name=data_desc[1][0], shape=data_desc[1][1])
- table = fluid.layers.control_flow.lod_rank_table(rank_data)
- new_data = fluid.layers.reorder_lod_tensor_by_rank(
- x=data, rank_table=table)
StaticRNN
- class
paddle.fluid.layers.StaticRNN(name=None) - StaticRNN可以处理一批序列数据。每个样本序列的长度必须相等。StaticRNN将拥有自己的参数,如输入、输出和存储器等。请注意,输入的第一个维度表示序列长度,且输入的所有序列长度必须相同。并且输入和输出的每个轴的含义是相同的。
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- vocab_size, hidden_size=10000, 200
- x = layers.data(name="x", shape=[-1, 1, 1], dtype='int64')
- x_emb = layers.embedding(
- input=x,
- size=[vocab_size, hidden_size],
- dtype='float32',
- is_sparse=False)
- x_emb = layers.transpose(x_emb, perm=[1, 0, 2])
- rnn = fluid.layers.StaticRNN()
- with rnn.step():
- word = rnn.step_input(x_emb)
- prev = rnn.memory(shape=[-1, hidden_size], batch_ref = word)
- hidden = fluid.layers.fc(input=[word, prev], size=hidden_size, act='relu')
- rnn.update_memory(prev, hidden) # set prev to hidden
- rnn.step_output(hidden)
- result = rnn()
StaticRNN将序列展开为时间步长。用户需要定义如何在with步骤中处理每个时间步长。
内存用作在time step之间缓存数据。内存的初始值可以是填充常量值的变量或指定变量。
StaticRNN可以将多个变量标记为其输出。使用rnn()获取输出序列。
step()用户在该代码块中定义RNN中的operators。
memory(init=None, shape=None, batch_ref=None, init_value=0.0, init_batch_dim_idx=0, ref_batch_dim_idx=1)为静态RNN创建一个内存变量。如果init不为None,则此变量将初始化内存。 如果init为None,则必须设置shape和batch_ref,并且此函数将初始化init变量。
- 参数:
- init (Variable|None) - 初始化过的变量,如果没有设置,则必须提供shape和batch_ref,默认值None
- shape (list|tuple) - boot memory的形状,注意其不包括batch_size,默认值None
- batch_ref (Variable|None) - batch引用变量,默认值None
- init_value (float) - boot memory的初始化值,默认值0.0
- init_batch_dim_idx (int) - init变量的batch_size轴,默认值0
- ref_batch_dim_idx (int) - batch_ref变量的batch_size轴返回:内存变量
代码示例:
- import paddle.fluid as fluid
- import paddle.fluid.layers as layers
- vocab_size, hidden_size=10000, 200
- x = layers.data(name="x", shape=[-1, 1, 1], dtype='int64')
- x_emb = layers.embedding(
- input=x,
- size=[vocab_size, hidden_size],
- dtype='float32',
- is_sparse=False)
- x_emb = layers.transpose(x_emb, perm=[1, 0, 2])
- rnn = fluid.layers.StaticRNN()
- with rnn.step():
- word = rnn.step_input(x_emb)
- prev = rnn.memory(shape=[-1, hidden_size], batch_ref = word)
- hidden = fluid.layers.fc(input=[word, prev], size=hidden_size, act='relu')
- rnn.update_memory(prev, hidden)
stepinput(_x)标记作为StaticRNN输入的序列。
- 参数:
- x (Variable) – 输入序列,x的形状应为[seq_len, …]。返回:输入序列中的当前时间步长。
stepoutput(_o)标记作为StaticRNN输出的序列。
- 参数:
- -o (Variable) – 输出序列返回:None
output(*outputs)标记StaticRNN输出变量。
- 参数:
- -outputs – 输出变量返回:None
updatememory(_mem, var)将内存从ex_mem更新为new_mem。请注意,ex_mem和new_mem的形状和数据类型必须相同。
- 参数:
- mem (Variable) – 内存变量
- var (Variable) – RNN块中产生的普通变量返回:None
Switch
- class
paddle.fluid.layers.Switch(name=None) - Switch类实现的功能十分类似if-elif-else。它可以在学习率调度器(learning rate scheduler)中调整学习率。
- 语义上,
- 1. switch控制流挨个检查cases
- 2. 各个case的条件是一个布尔值(boolean),它是一个标量(scalar)变量
- 3. 它将执行第一个匹配的case后面的分支,如果没有匹配的case,但若存在一个default case,则会执行default case后面的语句
- 4. 一旦匹配了一个case,它降会执行这个case所对应的分支,且仅此分支。
代码示例
- import paddle.fluid as fluid
- lr = fluid.layers.create_global_var(
- shape=[1],
- value=0.0,
- dtype='float32',
- persistable=True,
- name="learning_rate")
- zero_var = fluid.layers.fill_constant(
- shape=[1], dtype='float32', value=0.0)
- one_var = fluid.layers.fill_constant(
- shape=[1], dtype='float32', value=1.0)
- two_var = fluid.layers.fill_constant(
- shape=[1], dtype='float32', value=2.0)
- global_step = fluid.layers.autoincreased_step_counter(
- counter_name='@LR_DECAY_COUNTER@', begin=0, step=1)
- with fluid.layers.control_flow.Switch() as switch:
- with switch.case(global_step == zero_var):
- fluid.layers.assign(input=one_var, output=lr)
- with switch.default():
- fluid.layers.assign(input=two_var, output=lr)
While
- class
paddle.fluid.layers.While(cond, is_test=False, name=None) 该类用于实现while循环控制功能。
参数:
- cond (Variable) – 用于比较的条件
- is_test (bool) – 用于表明是不是在测试阶段执行
- name (str) - 该层的命名代码示例
- import paddle.fluid as fluid
- i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=0)
- d0 = fluid.layers.data("d0", shape=[10], dtype='float32')
- data_array = fluid.layers.array_write(x=d0, i=i)
- array_len = fluid.layers.fill_constant(shape=[1],dtype='int64', value=3)
- cond = fluid.layers.less_than(x=i, y=array_len)
- while_op = fluid.layers.While(cond=cond)
- with while_op.block():
- d = fluid.layers.array_read(array=data_array, i=i)
- i = fluid.layers.increment(x=i, value=1, in_place=True)
- fluid.layers.less_than(x=i, y=array_len, cond=cond)
