 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 设计思想
- 简介
- 1. Fluid内部执行流程
- 2. Program设计思想
- Programs and Blocks
- BlockDesc and ProgramDesc
- 使用Blocks的Operator
- 3. Executor设计思想
- 代码实例
设计思想
简介
本篇文档主要介绍Fluid底层的设计思想,帮助用户更好的理解框架运作过程。
阅读本文档,您将了解:
- Fluid 内部的执行流程
- Program 如何描述模型
- Executor 如何执行运算
1. Fluid内部执行流程
Fluid使用一种编译器式的执行流程,分为编译时和运行时两个部分,具体包括:编译器定义 Program ,创建Executor 运行 Program 。
本地训练任务执行流程图如下所示:
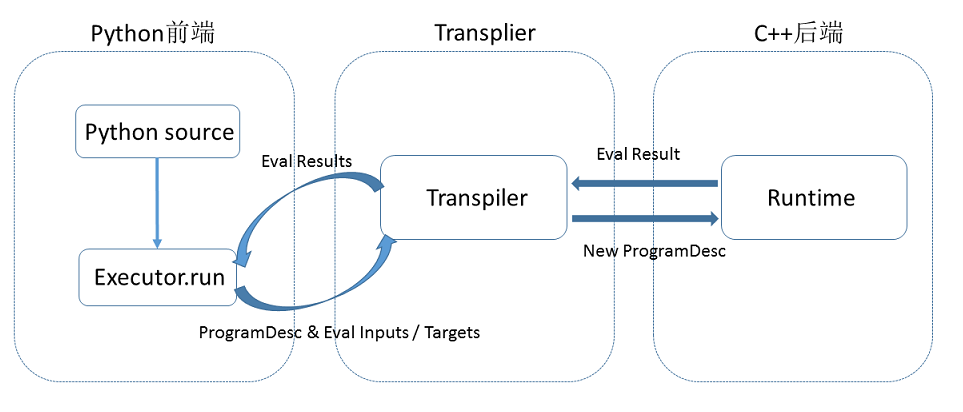
编译时,用户编写一段python程序,通过调用 Fluid 提供的算子,向一段 Program 中添加变量(Tensor)以及对变量的操作(Operators 或者 Layers)。用户只需要描述核心的前向计算,不需要关心反向计算、分布式下以及异构设备下如何计算。
原始的 Program 在平台内部转换为中间描述语言:
ProgramDesc。编译期最重要的一个功能模块是
Transpiler。Transpiler接受一段ProgramDesc,输出一段变化后的ProgramDesc,作为后端Executor最终需要执行的 Fluid Program后端 Executor 接受 Transpiler 输出的这段 Program ,依次执行其中的 Operator(可以类比为程序语言中的指令),在执行过程中会为 Operator 创建所需的输入输出并进行管理。
2. Program设计思想
用户完成网络定义后,一段 Fluid 程序中通常存在 2 段 Program:
- fluid.default_startup_program:定义了创建模型参数,输入输出,以及模型中可学习参数的初始化等各种操作
default_startup_program 可以由框架自动生成,使用时无需显示地创建
如果调用修改了参数的默认初始化方式,框架会自动的将相关的修改加入default_startup_program
- fluid.default_main_program :定义了神经网络模型,前向反向计算,以及优化算法对网络中可学习参数的更新
使用Fluid的核心就是构建起 default_main_program
Programs and Blocks
Fluid 的 Program 的基本结构是一些嵌套 blocks,形式上类似一段 C++ 或 Java 程序。
blocks中包含:
- 本地变量的定义
- 一系列的operatorblock的概念与通用程序一致,例如在下列这段C++代码中包含三个block:
- int main(){ //block 0
- int i = 0;
- if (i<10){ //block 1
- for (int j=0;j<10;j++){ //block 2
- }
- }
- return 0;
- }
类似的,在下列 Fluid 的 Program 包含3段block:
- import paddle.fluid as fluid # block 0
- limit = fluid.layers.fill_constant_batch_size_like(
- input=label, dtype='int64', shape=[1], value=5.0)
- cond = fluid.layers.less_than(x=label, y=limit)
- ie = fluid.layers.IfElse(cond)
- with ie.true_block(): # block 1
- true_image = ie.input(image)
- hidden = fluid.layers.fc(input=true_image, size=100, act='tanh')
- prob = fluid.layers.fc(input=hidden, size=10, act='softmax')
- ie.output(prob)
- with ie.false_block(): # block 2
- false_image = ie.input(image)
- hidden = fluid.layers.fc(
- input=false_image, size=200, act='tanh')
- prob = fluid.layers.fc(input=hidden, size=10, act='softmax')
- ie.output(prob)
- prob = ie()
BlockDesc and ProgramDesc
用户描述的block与program信息在Fluid中以protobuf 格式保存,所有的protobuf信息被定义在framework.proto中,在Fluid中被称为BlockDesc和ProgramDesc。ProgramDesc和BlockDesc的概念类似于一个抽象语法树。
BlockDesc中包含本地变量的定义 vars,和一系列的operatorops:
- message BlockDesc {
- required int32 parent = 1;
- repeated VarDesc vars = 2;
- repeated OpDesc ops = 3;
- }
parent ID表示父块,因此block中的操作符可以引用本地定义的变量,也可以引用祖先块中定义的变量。Program 中的每层 block 都被压平并存储在数组中。blocks ID是这个数组中块的索引。
- message ProgramDesc {
- repeated BlockDesc blocks = 1;
- }
使用Blocks的Operator
Programs and Blocks的例子中,IfElseOp这个Operator包含了两个block——true分支和false分支。
下述OpDesc的定义过程描述了一个operator可以包含哪些属性:
- message OpDesc {
- AttrDesc attrs = 1;
- ...
- }
属性可以是block的类型,实际上就是上面描述的block ID:
- message AttrDesc {
- required string name = 1;
- enum AttrType {
- INT = 1,
- STRING = 2,
- ...
- BLOCK = ...
- }
- required AttrType type = 2;
- optional int32 block = 10; // when type == BLOCK
- ...
- }
3. Executor设计思想
Executor 在运行时将接受一个ProgramDesc、一个block_id和一个Scope。ProgramDesc是block的列表,每一项包含block中所有参数和operator的protobuf定义;block_id指定入口块;Scope是所有变量实例的容器。
其中 Scope 包含了 name 与 Variable 的映射,所有变量都被定义在 Scope 里。大部分API会默认使用 global_scope ,例如 :code:Executor.run,您也可以指定网络运行在某个特定的 Scope 中,一个网络可以在不同的 Scope内运行,并在该 Scope 内更新不同的 Variable。
完成的编译执行的具体过程如下图所示:
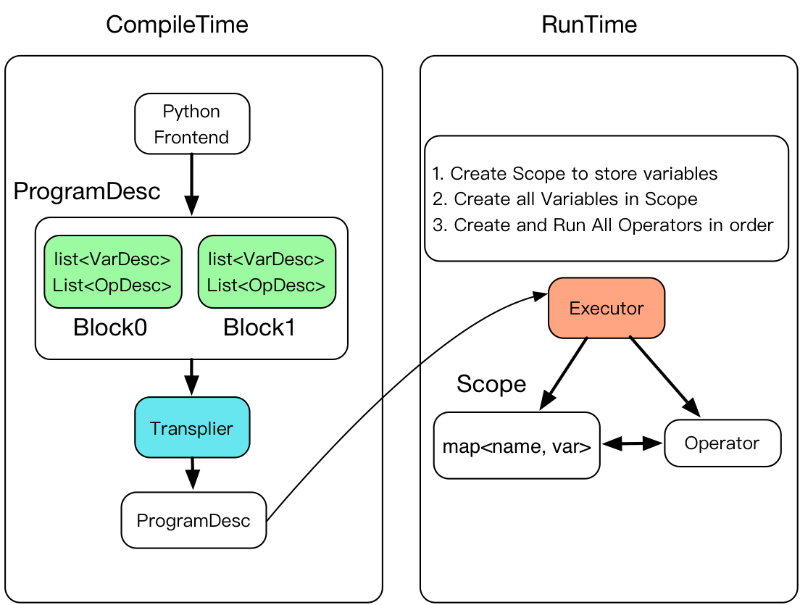
- Executor 为每一个block创建一个Scope,Block是可嵌套的,因此Scope也是可嵌套的
- 创建所有Scope中的变量
- 按顺序创建并执行所有operatorExecutor的C++实现代码如下:
- class Executor{
- public:
- void Run(const ProgramDesc& pdesc,
- Scope* scope,
- int block_id) {
- auto& block = pdesc.Block(block_id);
- //创建所有变量
- for (auto& var : block.AllVars())
- scope->Var(Var->Name());
- }
- //创建OP并按顺序执行
- for (auto& op_desc : block.AllOps()){
- auto op = CreateOp(*op_desc);
- op->Run(*local_scope, place_);
- }
- };
创建Executor
Fluid中使用fluid.Executor(place)创建Executor,place属性由用户定义,代表程序将在哪里执行。
下例代码表示创建一个Executor,其运行场所在CPU内:
- cpu=fluid.CPUPlace()
- exe = fluid.Executor(cpu)
运行Executor
Fluid使用Executor.run来运行程序。定义中通过Feed映射获取数据,通过fetch_list获取结果:
- ...
- x = numpy.random.random(size=(10, 1)).astype('float32')
- outs = exe.run(
- feed={'X': x},
- fetch_list=[loss.name])
代码实例
本节通过Fluid编程指南中简单的线性回归例子,为您介绍上述内容如何在代码中实现。
定义Program
您可以随意定义自己的数据和网络结构,定义的结果都将作为一段 Program 被 Fluid 接收,Program 的基本结构是一些 blocks,本节的 Program 仅包含一个 block 0:
- #加载函数库
- import paddle.fluid as fluid #block 0
- import numpy
- #定义数据
- train_data=numpy.array([[1.0],[2.0],[3.0],[4.0]]).astype('float32')
- y_true = numpy.array([[2.0],[4.0],[6.0],[8.0]]).astype('float32')
- #定义网络
- x = fluid.layers.data(name="x",shape=[1],dtype='float32')
- y = fluid.layers.data(name="y",shape=[1],dtype='float32')
- y_predict = fluid.layers.fc(input=x,size=1,act=None)
- #定义损失函数
- cost = fluid.layers.square_error_cost(input=y_predict,label=y)
- avg_cost = fluid.layers.mean(cost)
- #定义优化方法
- sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.01)
- sgd_optimizer.minimize(avg_cost)
完成上述定义,也就是完成了 fluid.default_main_program 的构建过程,fluid.default_main_program 中承载着神经网络模型,前向反向计算,以及优化算法对网络中可学习参数的更新。
此时可以输出这段 Program 观察定义好的网络形态:
- print(fluid.default_main_program().to_string(True))
完整ProgramDesc可以在本地查看,本次仅节选前三个变量的结果如下:
- blocks {
- idx: 0
- parent_idx: -1
- vars {
- name: "mean_1.tmp_0"
- type {
- type: LOD_TENSOR
- lod_tensor {
- tensor {
- data_type: FP32
- dims: 1
- }
- }
- }
- persistable: false
- }
- vars {
- name: "square_error_cost_1.tmp_1"
- type {
- type: LOD_TENSOR
- lod_tensor {
- tensor {
- data_type: FP32
- dims: -1
- dims: 1
- }
- lod_level: 0
- }
- }
- persistable: false
- }
- vars {
- name: "square_error_cost_1.tmp_0"
- type {
- type: LOD_TENSOR
- lod_tensor {
- tensor {
- data_type: FP32
- dims: -1
- dims: 1
- }
- lod_level: 0
- }
- }
- persistable: false
- ...
从输出结果中可以看到,整个定义过程在框架内部转化为了一段ProgramDesc,以block idx为索引。本次线性回归模型中仅有1个block,ProgramDesc中也仅有block 0一段BlockDesc。BlockDesc中包含定义的 vars 和一系列的 ops,以输入x为例,python代码中定义 x 是一个数据类型为"float 32"的1维数据:
- x = fluid.layers.data(name="x",shape=[1],dtype='float32')
在BlockDesc中,变量x被描述为:
- vars {
- name: "x"
- type {
- type: LOD_TENSOR
- lod_tensor {
- tensor {
- data_type: FP32
- dims: -1
- dims: 1
- }
- lod_level: 0
- }
- }
- persistable: false
在Fluid中所有的数据类型都为LoD-Tensor,对于不存在序列信息的数据(如此处的变量X),其lod_level=0。dims表示数据的维度,这里表示 x 的维度为[-1,1],其中-1是batch的维度,无法确定具体数值时,Fluid 自动用 -1 占位。
参数persistable表示该变量在整个训练过程中是否为持久化变量。
创建Executor
Fluid使用Executor来执行网络训练,Executor运行细节请参考Executor设计思想的介绍。作为使用者,实际并不需要了解内部机制。
创建Executor只需调用 fluid.Executor(place) 即可,在此之前请您依据训练场所定义place变量:
- #在CPU内执行训练
- cpu = fluid.CPUPlace()
- #创建Executor
- exe = fluid.Executor(cpu)
运行ExecutorFluid使用Executor.run来运行一段Program。
正式进行网络训练前,需先执行参数初始化。其中 defalut_startup_program 中定义了创建模型参数,输入输出,以及模型中可学习参数的初始化等各种操作。
- #参数初始化
- exe.run(fluid.default_startup_program())
由于传入数据与传出数据存在多列,因此 fluid 通过 feed 映射定义数据的传输数据,通过 fetch_list 取出期望结果:
- #开始训练
- outs = exe.run(
- feed={'x':train_data,'y':y_true},
- fetch_list=[y_predict.name,avg_cost.name])
上述代码段中定义了train_data传入x变量,y_true传入y变量,输出y的预测值和最后一轮cost值。输出结果为:
- [array([[1.5248038],
- [3.0496075],
- [4.5744114],
- [6.099215 ]], dtype=float32), array([1.6935859], dtype=float32)]
至此您已经了解了Fluid 内部的执行流程的核心概念,更多框架使用细节请参考使用指南相关内容,模型库中也为您提供了丰富的模型示例以供参考。
