 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- learning_rate_scheduler
- cosine_decay
- exponential_decay
- inverse_time_decay
- linear_lr_warmup
- natural_exp_decay
- noam_decay
- piecewise_decay
- polynomial_decay
learning_rate_scheduler
cosine_decay
paddle.fluid.layers.cosinedecay(_learning_rate, step_each_epoch, epochs)- 使用 cosine decay 的衰减方式进行学习率调整。
在训练模型时,建议一边进行训练一边降低学习率。 通过使用此方法,学习速率将通过如下cosine衰减策略进行衰减:
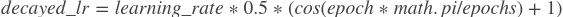
- 参数:
- learning_rate (Variable | float) - 初始学习率。
- step_each_epoch (int) - 一次迭代中的步数。
- epochs - 总迭代次数。代码示例
- import paddle.fluid as fluid
- base_lr = 0.1
- lr = fluid.layers.cosine_decay( learning_rate = base_lr, step_each_epoch=10000, epochs=120)
exponential_decay
paddle.fluid.layers.exponentialdecay(_learning_rate, decay_steps, decay_rate, staircase=False)- 在学习率上运用指数衰减。训练模型时,推荐在训练过程中降低学习率。每次
decay_steps步骤中用decay_rate衰减学习率。
- if staircase == True:
- decayed_learning_rate = learning_rate * decay_rate ^ floor(global_step / decay_steps)
- else:
- decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
- 参数:
- learning_rate (Variable|float)-初始学习率
- decay_steps (int)-见以上衰减运算
- decay_rate (float)-衰减率。见以上衰减运算
- staircase (Boolean)-若为True,按离散区间衰减学习率。默认:False返回:衰减的学习率
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- base_lr = 0.1
- sgd_optimizer = fluid.optimizer.SGD(
- learning_rate=fluid.layers.exponential_decay(
- learning_rate=base_lr,
- decay_steps=10000,
- decay_rate=0.5,
- staircase=True))
inverse_time_decay
paddle.fluid.layers.inversetime_decay(_learning_rate, decay_steps, decay_rate, staircase=False)- 在初始学习率上运用逆时衰减。
训练模型时,最好在训练过程中降低学习率。通过执行该函数,将对初始学习率运用逆向衰减函数。
- if staircase == True:
- decayed_learning_rate = learning_rate / (1 + decay_rate * floor(global_step / decay_step))
- else:
- decayed_learning_rate = learning_rate / (1 + decay_rate * global_step / decay_step)
- 参数:
- learning_rate (Variable|float)-初始学习率
- decay_steps (int)-见以上衰减运算
- decay_rate (float)-衰减率。见以上衰减运算
- staircase (Boolean)-若为True,按间隔区间衰减学习率。默认:False返回:衰减的学习率
返回类型:变量(Variable)
示例代码:
- import paddle.fluid as fluid
- base_lr = 0.1
- sgd_optimizer = fluid.optimizer.SGD(
- learning_rate=fluid.layers.natural_exp_decay(
- learning_rate=base_lr,
- decay_steps=10000,
- decay_rate=0.5,
- staircase=True))
- sgd_optimizer.minimize(avg_cost)
linear_lr_warmup
paddle.fluid.layers.linearlr_warmup(_learning_rate, warmup_steps, start_lr, end_lr)- 在正常学习率调整之前先应用线性学习率热身(warm up)进行初步调整。
- if global_step < warmup_steps:
- linear_step = end_lr - start_lr
- lr = start_lr + linear_step * (global_step / warmup_steps)
- 参数:
- learning_rate (float | Variable) - 学习率,类型为float值或变量。
- warmup_steps (int) - 进行warm up过程的步数。
- start_lr (float) - warm up的起始学习率
- end_lr (float) - warm up的最终学习率。返回:进行热身衰减后的学习率。
示例代码
- import paddle.fluid as fluid
- boundaries = [100, 200]
- lr_steps = [0.1, 0.01, 0.001]
- warmup_steps = 50
- start_lr = 1. / 3.
- end_lr = 0.1
- decayed_lr = fluid.layers.linear_lr_warmup(
- fluid.layers.piecewise_decay(boundaries, lr_steps),
- warmup_steps, start_lr, end_lr)
natural_exp_decay
paddle.fluid.layers.naturalexp_decay(_learning_rate, decay_steps, decay_rate, staircase=False)- 将自然指数衰减运用到初始学习率上。
- if not staircase:
- decayed_learning_rate = learning_rate * exp(- decay_rate * (global_step / decay_steps))
- else:
- decayed_learning_rate = learning_rate * exp(- decay_rate * (global_step / decay_steps))
- 参数:
- learning_rate - 标量float32值或变量。是训练过程中的初始学习率。
- decay_steps - Python int32数
- decay_rate - Python float数
- staircase - Boolean.若设为true,每个decay_steps衰减学习率返回:衰减的学习率
示例代码:
- import paddle.fluid as fluid
- base_lr = 0.1
- sgd_optimizer = fluid.optimizer.SGD(
- learning_rate=fluid.layers.natural_exp_decay(
- learning_rate=base_lr,
- decay_steps=10000,
- decay_rate=0.5,
- staircase=True))
noam_decay
paddle.fluid.layers.noamdecay(_d_model, warmup_steps)- Noam衰减方法。noam衰减的numpy实现如下。
- import padde.fluid as fluid
- import numpy as np
- # 设置超参数
- d_model = 2
- current_steps = 20
- warmup_steps = 200
- # 计算
- lr_value = np.power(d_model, -0.5) * np.min([
- np.power(current_steps, -0.5),
- np.power(warmup_steps, -1.5) * current_steps])
请参照 attention is all you need
- 参数:
- d_model (Variable)-模型的输入和输出维度
- warmup_steps (Variable)-超参数返回:衰减的学习率
代码示例:
- import padde.fluid as fluid
- warmup_steps = 100
- learning_rate = 0.01
- lr = fluid.layers.learning_rate_scheduler.noam_decay(
- 1/(warmup_steps *(learning_rate ** 2)),
- warmup_steps)
piecewise_decay
paddle.fluid.layers.piecewisedecay(_boundaries, values)- 对初始学习率进行分段衰减。
该算法可用如下代码描述。
- boundaries = [10000, 20000]
- values = [1.0, 0.5, 0.1]
- if step < 10000:
- learning_rate = 1.0
- elif 10000 <= step < 20000:
- learning_rate = 0.5
- else:
- learning_rate = 0.1
- 参数:
- boundaries -一列代表步数的数字
- values -一列学习率的值,从不同的步边界中挑选返回:衰减的学习率
代码示例:
- import paddle.fluid as fluid
- boundaries = [10000, 20000]
- values = [1.0, 0.5, 0.1]
- optimizer = fluid.optimizer.Momentum(
- momentum=0.9,
- learning_rate=fluid.layers.piecewise_decay(boundaries=boundaries, values=values),
- regularization=fluid.regularizer.L2Decay(1e-4))
polynomial_decay
paddle.fluid.layers.polynomialdecay(_learning_rate, decay_steps, end_learning_rate=0.0001, power=1.0, cycle=False)- 对初始学习率使用多项式衰减
- if cycle:
- decay_steps = decay_steps * ceil(global_step / decay_steps)
- else:
- global_step = min(global_step, decay_steps)
- decayed_learning_rate = (learning_rate - end_learning_rate) *
- (1 - global_step / decay_steps) ^ power + end_learning_rate
- 参数:
- learning_rate (Variable|float32)-标量float32值或变量。是训练过程中的初始学习率。
- decay_steps (int32)-Python int32数
- end_learning_rate (float)-Python float数
- power (float)-Python float数
- cycle (bool)-若设为true,每decay_steps衰减学习率返回:衰减的学习率
返回类型:变量(Variable)
代码示例:
- import paddle.fluid as fluid
- start_lr = 0.01
- total_step = 5000
- end_lr = 0
- lr = fluid.layers.polynomial_decay(
- start_lr, total_step, end_lr, power=1)
