 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 16.3 有模型学习
- 16.3.1 策略评估
- 16.3.2 策略改进
16.3 有模型学习
若学习任务中的四个要素都已知,即状态空间、动作空间、转移概率以及奖赏函数都已经给出,这样的情形称为“有模型学习”。假设状态空间和动作空间均为有限,即均为离散值,这样我们不用通过尝试便可以对某个策略进行评估。
16.3.1 策略评估
前面提到:在模型已知的前提下,我们可以对任意策略的进行评估(后续会给出演算过程)。一般常使用以下两种值函数来评估某个策略的优劣:
状态值函数(V):V(x),即从状态x出发,使用π策略所带来的累积奖赏;状态-动作值函数(Q):Q(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
根据累积奖赏的定义,我们可以引入T步累积奖赏与r折扣累积奖赏:
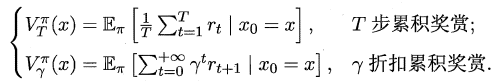
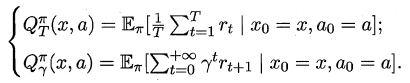
由于MDP具有马尔可夫性,即现在决定未来,将来和过去无关,我们很容易找到值函数的递归关系:

类似地,对于r折扣累积奖赏可以得到:
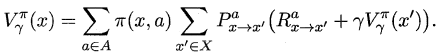
易知:当模型已知时,策略的评估问题转化为一种动态规划问题,即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,再求解每个状态的两步累积奖赏,一直迭代逐步求解出每个状态的T步累积奖赏。算法流程如下所示:

对于状态-动作值函数,只需通过简单的转化便可得到:
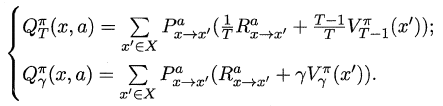
16.3.2 策略改进
理想的策略应能使得每个状态的累积奖赏之和最大,简单来理解就是:不管处于什么状态,只要通过该策略执行动作,总能得到较好的结果。因此对于给定的某个策略,我们需要对其进行改进,从而得到最优的值函数。
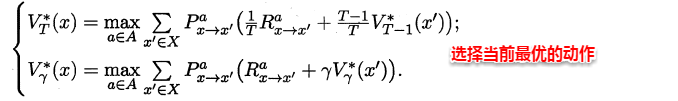
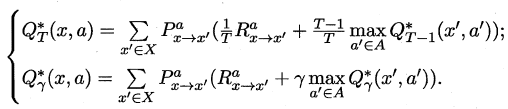
最优Bellman等式改进策略的方式为:将策略选择的动作改为当前最优的动作,而不是像之前那样对每种可能的动作进行求和。易知:选择当前最优动作相当于将所有的概率都赋给累积奖赏值最大的动作,因此每次改进都会使得值函数单调递增。
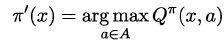
将策略评估与策略改进结合起来,我们便得到了生成最优策略的方法:先给定一个随机策略,现对该策略进行评估,然后再改进,接着再评估/改进一直到策略收敛、不再发生改变。这便是策略迭代算法,算法流程如下所示:

可以看出:策略迭代法在每次改进策略后都要对策略进行重新评估,因此比较耗时。若从最优化值函数的角度出发,即先迭代得到最优的值函数,再来计算如何改变策略,这便是值迭代算法,算法流程如下所示:

