 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 11.6 度量学习
11.6 度量学习
本篇一开始就提到维数灾难,即在高维空间进行机器学习任务遇到样本稀疏、距离难计算等诸多的问题,因此前面讨论的降维方法都试图将原空间投影到一个合适的低维空间中,接着在低维空间进行学习任务从而产生较好的性能。事实上,不管高维空间还是低维空间都潜在对应着一个距离度量,那可不可以直接学习出一个距离度量来等效降维呢?例如:咋们就按照降维后的方式来进行距离的计算,这便是度量学习的初衷。
首先要学习出距离度量必须先定义一个合适的距离度量形式。对两个样本xi与xj,它们之间的平方欧式距离为:
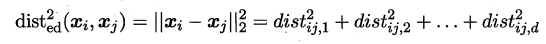
若各个属性重要程度不一样即都有一个权重,则得到加权的平方欧式距离:
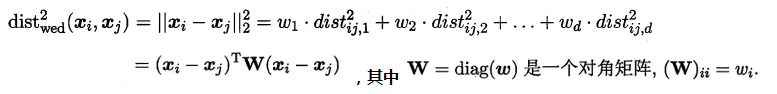
此时各个属性之间都是相互独立无关的,但现实中往往会存在属性之间有关联的情形,例如:身高和体重,一般人越高,体重也会重一些,他们之间存在较大的相关性。这样计算距离就不能分属性单独计算,于是就引入经典的马氏距离(Mahalanobis distance):
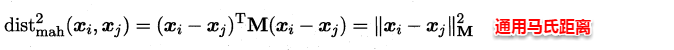
标准的马氏距离中M是协方差矩阵的逆,马氏距离是一种考虑属性之间相关性且尺度无关(即无须去量纲)的距离度量。
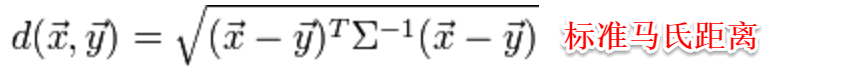
矩阵M也称为“度量矩阵”,为保证距离度量的非负性与对称性,M必须为(半)正定对称矩阵,这样就为度量学习定义好了距离度量的形式,换句话说:度量学习便是对度量矩阵进行学习。现在来回想一下前面我们接触的机器学习不难发现:机器学习算法几乎都是在优化目标函数,从而求解目标函数中的参数。同样对于度量学习,也需要设置一个优化目标,书中简要介绍了错误率和相似性两种优化目标,此处限于篇幅不进行展开。
在此,降维和度量学习就介绍完毕。降维是将原高维空间嵌入到一个合适的低维子空间中,接着在低维空间中进行学习任务;度量学习则是试图去学习出一个距离度量来等效降维的效果,两者都是为了解决维数灾难带来的诸多问题。也许大家最后心存疑惑,那kNN呢,为什么一开头就说了kNN算法,但是好像和后面没有半毛钱关系?正是因为在降维算法中,低维子空间的维数d’通常都由人为指定,因此我们需要使用一些低开销的学习器来选取合适的d’,kNN这家伙懒到家了根本无心学习,在训练阶段开销为零,测试阶段也只是遍历计算了距离,因此拿kNN来进行交叉验证就十分有优势了~同时降维后样本密度增大同时距离计算变易,更为kNN来展示它独特的十八般手艺提供了用武之地。
