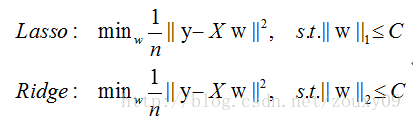我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 12.4 嵌入式选择与正则化
12.4 嵌入式选择与正则化
前面提到了的两种特征选择方法:过滤式中特征选择与后续学习器完全分离,包裹式则是使用学习器作为特征选择的评价准则;嵌入式是一种将特征选择与学习器训练完全融合的特征选择方法,即将特征选择融入学习器的优化过程中。在之前《经验风险与结构风险》中已经提到:经验风险指的是模型与训练数据的契合度,结构风险则是模型的复杂程度,机器学习的核心任务就是:在模型简单的基础上保证模型的契合度。例如:岭回归就是加上了L2范数的最小二乘法,有效地解决了奇异矩阵、过拟合等诸多问题,下面的嵌入式特征选择则是在损失函数后加上了L1范数。
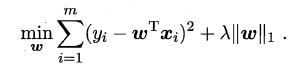
L1范数美名又约Lasso Regularization,指的是向量中每个元素的绝对值之和,这样在优化目标函数的过程中,就会使得w尽可能地小,在一定程度上起到了防止过拟合的作用,同时与L2范数(Ridge Regularization )不同的是,L1范数会使得部分w变为0, 从而达到了特征选择的效果。
总的来说:L1范数会趋向产生少量的特征,其他特征的权值都是0;L2会选择更多的特征,这些特征的权值都会接近于0。这样L1范数在特征选择上就十分有用,而L2范数则具备较强的控制过拟合能力。可以从下面两个方面来理解:
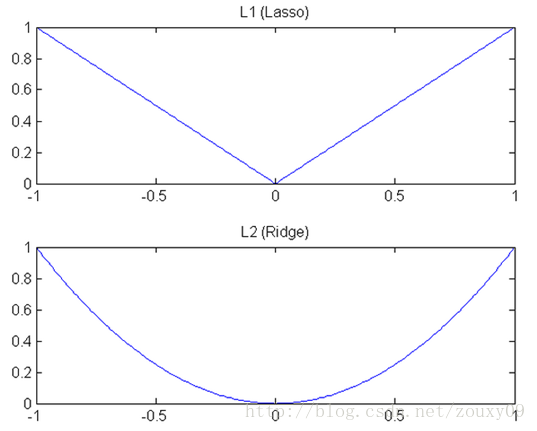
(1)下降速度:L1范数按照绝对值函数来下降,L2范数按照二次函数来下降。因此在0附近,L1范数的下降速度大于L2范数,故L1范数能很快地下降到0,而L2范数在0附近的下降速度非常慢,因此较大可能收敛在0的附近。
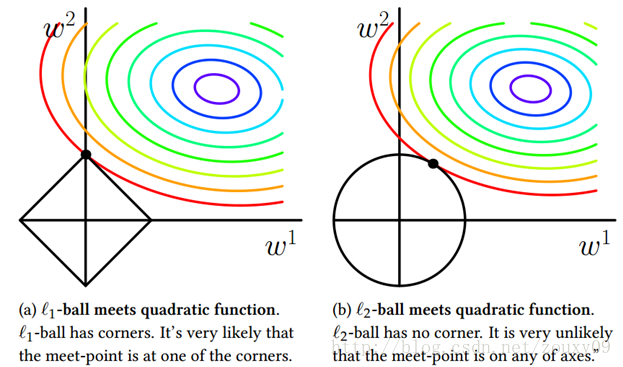
(2)空间限制:L1范数与L2范数都试图在最小化损失函数的同时,让权值W也尽可能地小。我们可以将原优化问题看做为下面的问题,即让后面的规则则都小于某个阈值。这样从图中可以看出:L1范数相比L2范数更容易得到稀疏解。