 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 5.5 深度学习
5.5 深度学习
理论上,参数越多,模型复杂度就越高,容量(capability)就越大,从而能完成更复杂的学习任务。深度学习(deep learning)正是一种极其复杂而强大的模型。
怎么增大模型复杂度呢?两个办法,一是增加隐层的数目,二是增加隐层神经元的数目。前者更有效一些,因为它不仅增加了功能神经元的数量,还增加了激活函数嵌套的层数。但是对于多隐层神经网络,经典算法如标准BP算法往往会在误差逆传播时发散(diverge),无法收敛达到稳定状态。
那要怎么有效地训练多隐层神经网络呢?一般来说有以下两种方法:
无监督逐层训练(unsupervised layer-wise training):每次训练一层隐节点,把上一层隐节点的输出当作输入来训练,本层隐结点训练好后,输出再作为下一层的输入来训练,这称为预训练(pre-training)。全部预训练完成后,再对整个网络进行微调(fine-tuning)训练。一个典型例子就是深度信念网络(deep belief network,简称DBN)。这种做法其实可以视为把大量的参数进行分组,先找出每组较好的设置,再基于这些局部最优的结果来训练全局最优。
权共享(weight sharing):令同一层神经元使用完全相同的连接权,典型的例子是卷积神经网络(Convolutional Neural Network,简称CNN)。这样做可以大大减少需要训练的参数数目。
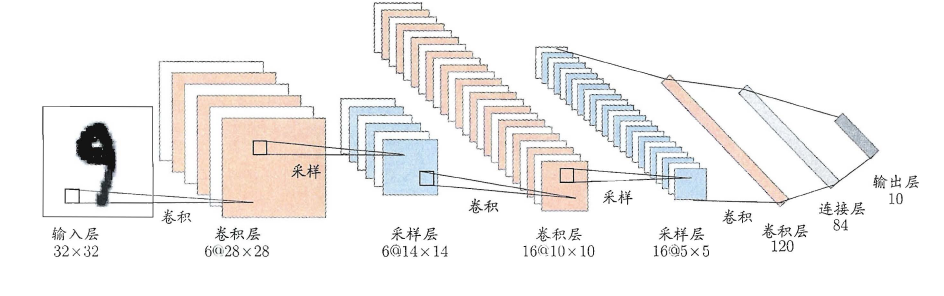
深度学习可以理解为一种特征学习(feature learning)或者表示学习(representation learning),无论是DBN还是CNN,都是通过多个隐层来把与输出目标联系不大的初始输入转化为与输出目标更加密切的表示,使原来只通过单层映射难以完成的任务变为可能。即通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示,从而使得最后可以用简单的模型来完成复杂的学习任务。
传统任务中,样本的特征需要人类专家来设计,这称为特征工程(feature engineering)。特征好坏对泛化性能有至关重要的影响。而深度学习为全自动数据分析带来了可能,可以自动产生更好的特征。
