 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 11.1 K近邻学习
11.1 K近邻学习
k近邻算法简称kNN(k-Nearest Neighbor),是一种经典的监督学习方法,同时也实力担当入选数据挖掘十大算法。其工作机制十分简单粗暴:给定某个测试样本,kNN基于某种距离度量在训练集中找出与其距离最近的k个带有真实标记的训练样本,然后给基于这k个邻居的真实标记来进行预测,类似于前面集成学习中所讲到的基学习器结合策略:分类任务采用投票法,回归任务则采用平均法。接下来本篇主要就kNN分类进行讨论。
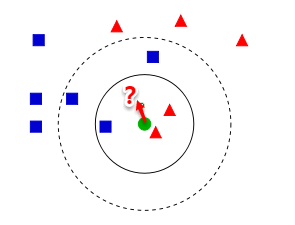
从上图【来自Wiki】中我们可以看到,图中有两种类型的样本,一类是蓝色正方形,另一类是红色三角形。而那个绿色圆形是我们待分类的样本。基于kNN算法的思路,我们很容易得到以下结论:
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
可以发现:kNN虽然是一种监督学习方法,但是它却没有显式的训练过程,而是当有新样本需要预测时,才来计算出最近的k个邻居,因此kNN是一种典型的懒惰学习方法,再来回想一下朴素贝叶斯的流程,训练的过程就是参数估计,因此朴素贝叶斯也可以懒惰式学习,此类技术在训练阶段开销为零,待收到测试样本后再进行计算。相应地我们称那些一有训练数据立马开工的算法为“急切学习”,可见前面我们学习的大部分算法都归属于急切学习。
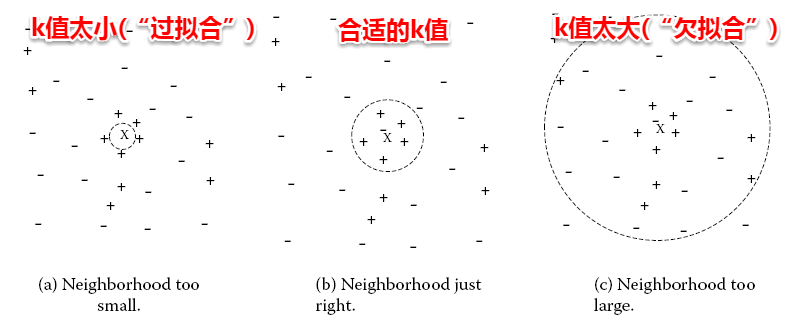
很容易看出:kNN算法的核心在于k值的选取以及距离的度量。k值选取太小,模型很容易受到噪声数据的干扰,例如:极端地取k=1,若待分类样本正好与一个噪声数据距离最近,就导致了分类错误;若k值太大, 则在更大的邻域内进行投票,此时模型的预测能力大大减弱,例如:极端取k=训练样本数,就相当于模型根本没有学习,所有测试样本的预测结果都是一样的。一般地我们都通过交叉验证法来选取一个适当的k值。
对于距离度量,不同的度量方法得到的k个近邻不尽相同,从而对最终的投票结果产生了影响,因此选择一个合适的距离度量方法也十分重要。在上一篇聚类算法中,在度量样本相似性时介绍了常用的几种距离计算方法,包括闵可夫斯基距离,曼哈顿距离,VDM等。在实际应用中,kNN的距离度量函数一般根据样本的特性来选择合适的距离度量,同时应对数据进行去量纲/归一化处理来消除大量纲属性的强权政治影响。
