 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 5.10. 批量归一化
- 5.10.1. 批量归一化层
- 5.10.1.1. 对全连接层做批量归一化
- 5.10.1.2. 对卷积层做批量归一化
- 5.10.1.3. 预测时的批量归一化
- 5.10.2. 从零开始实现
- 5.10.2.1. 使用批量归一化层的LeNet
- 5.10.3. 简洁实现
- 5.10.4. 小结
- 5.10.5. 练习
- 5.10.6. 参考文献
- 5.10.1. 批量归一化层
5.10. 批量归一化
本节我们介绍批量归一化(batchnormalization)层,它能让较深的神经网络的训练变得更加容易 [1]。在“实战Kaggle比赛:预测房价”一节里,我们对输入数据做了标准化处理:处理后的任意一个特征在数据集中所有样本上的均值为0、标准差为1。标准化处理输入数据使各个特征的分布相近:这往往更容易训练出有效的模型。
通常来说,数据标准化预处理对于浅层模型就足够有效了。随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化。但对深层神经网络来说,即使输入数据已做标准化,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。
批量归一化的提出正是为了应对深度模型训练的挑战。在模型训练时,批量归一化利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。批量归一化和下一节将要介绍的残差网络为训练和设计深度模型提供了两类重要思路。
5.10.1. 批量归一化层
对全连接层和卷积层做批量归一化的方法稍有不同。下面我们将分别介绍这两种情况下的批量归一化。
5.10.1.1. 对全连接层做批量归一化
我们先考虑如何对全连接层做批量归一化。通常,我们将批量归一化层置于全连接层中的仿射变换和激活函数之间。设全连接层的输入为
 ,权重参数和偏差参数分别为
,权重参数和偏差参数分别为
 和
和
 ,激活函数为
,激活函数为
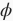 。设批量归一化的运算符为
。设批量归一化的运算符为
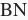 。那么,使用批量归一化的全连接层的输出为
。那么,使用批量归一化的全连接层的输出为

其中批量归一化输入
 由仿射变换
由仿射变换

得到。考虑一个由
 个样本组成的小批量,仿射变换的输出为一个新的小批量
个样本组成的小批量,仿射变换的输出为一个新的小批量
 。它们正是批量归一化层的输入。对于小批量
。它们正是批量归一化层的输入。对于小批量
 中任意样本
中任意样本
 ,批量归一化层的输出同样是
,批量归一化层的输出同样是
 维向量
维向量

并由以下几步求得。首先,对小批量
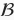 求均值和方差:
求均值和方差:


其中的平方计算是按元素求平方。接下来,使用按元素开方和按元素除法对
 标准化:
标准化:

这里
 是一个很小的常数,保证分母大于0。在上面标准化的基础上,批量归一化层引入了两个可以学习的模型参数,拉伸(scale)参数
是一个很小的常数,保证分母大于0。在上面标准化的基础上,批量归一化层引入了两个可以学习的模型参数,拉伸(scale)参数
 和偏移(shift)参数
和偏移(shift)参数
 。这两个参数和
。这两个参数和
 形状相同,皆为
形状相同,皆为
 维向量。它们与
维向量。它们与
 分别做按元素乘法(符号
分别做按元素乘法(符号
 )和加法计算:
)和加法计算:

至此,我们得到了
 的批量归一化的输出
的批量归一化的输出
 。值得注意的是,可学习的拉伸和偏移参数保留了不对
。值得注意的是,可学习的拉伸和偏移参数保留了不对
 做批量归一化的可能:此时只需学出
做批量归一化的可能:此时只需学出
 和
和
 。我们可以对此这样理解:如果批量归一化无益,理论上,学出的模型可以不使用批量归一化。
。我们可以对此这样理解:如果批量归一化无益,理论上,学出的模型可以不使用批量归一化。
5.10.1.2. 对卷积层做批量归一化
对卷积层来说,批量归一化发生在卷积计算之后、应用激活函数之前。如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数,并均为标量。设小批量中有
 个样本。在单个通道上,假设卷积计算输出的高和宽分别为
个样本。在单个通道上,假设卷积计算输出的高和宽分别为
 和
和
 。我们需要对该通道中
。我们需要对该通道中
 个元素同时做批量归一化。对这些元素做标准化计算时,我们使用相同的均值和方差,即该通道中
个元素同时做批量归一化。对这些元素做标准化计算时,我们使用相同的均值和方差,即该通道中
 个元素的均值和方差。
个元素的均值和方差。
5.10.1.3. 预测时的批量归一化
使用批量归一化训练时,我们可以将批量大小设得大一点,从而使批量内样本的均值和方差的计算都较为准确。将训练好的模型用于预测时,我们希望模型对于任意输入都有确定的输出。因此,单个样本的输出不应取决于批量归一化所需要的随机小批量中的均值和方差。一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。可见,和丢弃层一样,批量归一化层在训练模式和预测模式下的计算结果也是不一样的。
5.10.2. 从零开始实现
下面我们通过NDArray来实现批量归一化层。
- In [1]:
- import d2lzh as d2l
- from mxnet import autograd, gluon, init, nd
- from mxnet.gluon import nn
- def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
- # 通过autograd来判断当前模式是训练模式还是预测模式
- if not autograd.is_training():
- # 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
- X_hat = (X - moving_mean) / nd.sqrt(moving_var + eps)
- else:
- assert len(X.shape) in (2, 4)
- if len(X.shape) == 2:
- # 使用全连接层的情况,计算特征维上的均值和方差
- mean = X.mean(axis=0)
- var = ((X - mean) ** 2).mean(axis=0)
- else:
- # 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
- # X的形状以便后面可以做广播运算
- mean = X.mean(axis=(0, 2, 3), keepdims=True)
- var = ((X - mean) ** 2).mean(axis=(0, 2, 3), keepdims=True)
- # 训练模式下用当前的均值和方差做标准化
- X_hat = (X - mean) / nd.sqrt(var + eps)
- # 更新移动平均的均值和方差
- moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
- moving_var = momentum * moving_var + (1.0 - momentum) * var
- Y = gamma * X_hat + beta # 拉伸和偏移
- return Y, moving_mean, moving_var
接下来,我们自定义一个BatchNorm层。它保存参与求梯度和迭代的拉伸参数gamma和偏移参数beta,同时也维护移动平均得到的均值和方差,以便能够在模型预测时被使用。BatchNorm实例所需指定的num_features参数对于全连接层来说应为输出个数,对于卷积层来说则为输出通道数。该实例所需指定的num_dims参数对于全连接层和卷积层来说分别为2和4。
- In [2]:
- class BatchNorm(nn.Block):
- def __init__(self, num_features, num_dims, **kwargs):
- super(BatchNorm, self).__init__(**kwargs)
- if num_dims == 2:
- shape = (1, num_features)
- else:
- shape = (1, num_features, 1, 1)
- # 参与求梯度和迭代的拉伸和偏移参数,分别初始化成0和1
- self.gamma = self.params.get('gamma', shape=shape, init=init.One())
- self.beta = self.params.get('beta', shape=shape, init=init.Zero())
- # 不参与求梯度和迭代的变量,全在内存上初始化成0
- self.moving_mean = nd.zeros(shape)
- self.moving_var = nd.zeros(shape)
- def forward(self, X):
- # 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
- if self.moving_mean.context != X.context:
- self.moving_mean = self.moving_mean.copyto(X.context)
- self.moving_var = self.moving_var.copyto(X.context)
- # 保存更新过的moving_mean和moving_var
- Y, self.moving_mean, self.moving_var = batch_norm(
- X, self.gamma.data(), self.beta.data(), self.moving_mean,
- self.moving_var, eps=1e-5, momentum=0.9)
- return Y
5.10.2.1. 使用批量归一化层的LeNet
下面我们修改“卷积神经网络(LeNet)”这一节介绍的LeNet模型,从而应用批量归一化层。我们在所有的卷积层或全连接层之后、激活层之前加入批量归一化层。
- In [3]:
- net = nn.Sequential()
- net.add(nn.Conv2D(6, kernel_size=5),
- BatchNorm(6, num_dims=4),
- nn.Activation('sigmoid'),
- nn.MaxPool2D(pool_size=2, strides=2),
- nn.Conv2D(16, kernel_size=5),
- BatchNorm(16, num_dims=4),
- nn.Activation('sigmoid'),
- nn.MaxPool2D(pool_size=2, strides=2),
- nn.Dense(120),
- BatchNorm(120, num_dims=2),
- nn.Activation('sigmoid'),
- nn.Dense(84),
- BatchNorm(84, num_dims=2),
- nn.Activation('sigmoid'),
- nn.Dense(10))
下面我们训练修改后的模型。
- In [4]:
- lr, num_epochs, batch_size, ctx = 1.0, 5, 256, d2l.try_gpu()
- net.initialize(ctx=ctx, init=init.Xavier())
- trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
- train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
- d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx,
- num_epochs)
- training on gpu(0)
- epoch 1, loss 0.6684, train acc 0.760, test acc 0.796, time 3.4 sec
- epoch 2, loss 0.4049, train acc 0.854, test acc 0.714, time 3.3 sec
- epoch 3, loss 0.3492, train acc 0.874, test acc 0.871, time 3.2 sec
- epoch 4, loss 0.3265, train acc 0.881, test acc 0.868, time 3.2 sec
- epoch 5, loss 0.3030, train acc 0.889, test acc 0.858, time 3.3 sec
最后我们查看第一个批量归一化层学习到的拉伸参数gamma和偏移参数beta。
- In [5]:
- net[1].gamma.data().reshape((-1,)), net[1].beta.data().reshape((-1,))
- Out[5]:
- (
- [1.4753449 1.3099607 1.1478884 1.6333511 1.8347042 1.7537688]
- <NDArray 6 @gpu(0)>,
- [ 0.6089993 0.42559218 0.15979916 0.5844886 -0.14368834 -1.6800053 ]
- <NDArray 6 @gpu(0)>)
5.10.3. 简洁实现
与我们刚刚自己定义的BatchNorm类相比,Gluon中nn模块定义的BatchNorm类使用起来更加简单。它不需要指定自己定义的BatchNorm类中所需的num_features和num_dims参数值。在Gluon中,这些参数值都将通过延后初始化而自动获取。下面我们用Gluon实现使用批量归一化的LeNet。
- In [6]:
- net = nn.Sequential()
- net.add(nn.Conv2D(6, kernel_size=5),
- nn.BatchNorm(),
- nn.Activation('sigmoid'),
- nn.MaxPool2D(pool_size=2, strides=2),
- nn.Conv2D(16, kernel_size=5),
- nn.BatchNorm(),
- nn.Activation('sigmoid'),
- nn.MaxPool2D(pool_size=2, strides=2),
- nn.Dense(120),
- nn.BatchNorm(),
- nn.Activation('sigmoid'),
- nn.Dense(84),
- nn.BatchNorm(),
- nn.Activation('sigmoid'),
- nn.Dense(10))
使用同样的超参数进行训练。
- In [7]:
- net.initialize(ctx=ctx, init=init.Xavier())
- trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
- d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx,
- num_epochs)
- training on gpu(0)
- epoch 1, loss 0.6568, train acc 0.769, test acc 0.831, time 1.9 sec
- epoch 2, loss 0.3986, train acc 0.856, test acc 0.826, time 1.9 sec
- epoch 3, loss 0.3478, train acc 0.872, test acc 0.843, time 1.8 sec
- epoch 4, loss 0.3200, train acc 0.883, test acc 0.880, time 2.0 sec
- epoch 5, loss 0.3033, train acc 0.889, test acc 0.875, time 1.9 sec
5.10.4. 小结
- 在模型训练时,批量归一化利用小批量上的均值和标准差,不断调整神经网络的中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
- 对全连接层和卷积层做批量归一化的方法稍有不同。
- 批量归一化层和丢弃层一样,在训练模式和预测模式的计算结果是不一样的。
- Gluon提供的BatchNorm类使用起来简单、方便。
5.10.5. 练习
- 能否将批量归一化前的全连接层或卷积层中的偏差参数去掉?为什么?(提示:回忆批量归一化中标准化的定义。)
- 尝试调大学习率。同“卷积神经网络(LeNet)”一节中未使用批量归一化的LeNet相比,现在是不是可以使用更大的学习率?
- 尝试将批量归一化层插入LeNet的其他地方,观察并分析结果的变化。
- 尝试一下不学习拉伸参数
gamma和偏移参数beta(构造的时候加入参数grad_req='null'来避免计算梯度),观察并分析结果。 - 查看
BatchNorm类的文档来了解更多使用方法,例如,如何在训练时使用基于全局平均的均值和方差。
5.10.6. 参考文献
[1] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Acceleratingdeep network training by reducing internal covariate shift. arXivpreprint arXiv:1502.03167.
