 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 优化网络子系统
- 流量行为
- 速度和双工
- MTU大小
- 增加网络缓冲
- 额外的TCP/IP调整
- 防火墙的影响
- 卸载配置
- 增加包队列
- 增加发送队列长度
- 减少中断
优化网络子系统
优化网络子系统
流量行为
速度和双工
MTU大小
增加网络缓冲
额外的TCP/IP调整
防火墙的影响
卸载配置
增加包队列
增加发送队列长度
减少中断
在系统安装之初和感觉到网络子系统瓶颈的时候,我们应该对其进行优化。子系统间可能导致相互的影响:例如,网络问题可以影响到CPU利用率,尤其当包大小特别小的时候;当TCP连接数太多的时候,内存使用率会变高。
流量行为
在网络性能调优中,最重要的是尽可能准确的理解网络流量模式。性能很大程度上取决于流量特征。
例如, 下面的两张图是使用netperf收集的,说明了流量模式对性能的影响。两张图唯一的区别是流量类型,第一张图是TCP_RR的结果,第二张图是TCP_CRR类型的流量。性能差别主要是由TCP session连接和关闭操作带来的损耗,以及Netfilter连接跟踪导致的。
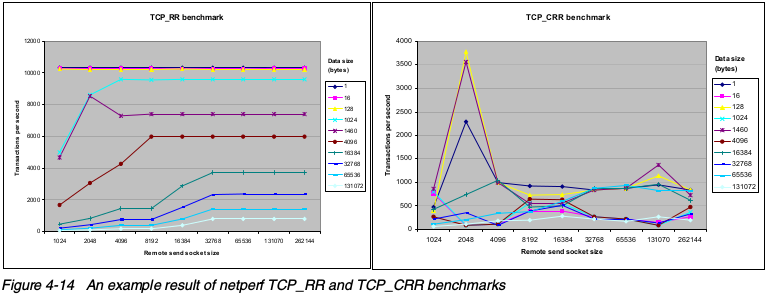
如图所示,在相同的配置的情况下,即使细微的流量行为差别也能导致巨大的性能差别。请熟悉下面的网络流量行为和要求:
事务吞吐需求(峰值和平均值)
数据传输的吞吐需求(峰值和平均值)
延时需求
传输数据大小
接收和发送的比例
连接建立和关闭的频率,还有连接并发数
协议(TCP,UDP,应用协议,比如HTTP,SMTP,LDAP等等)
使用netstat,tcpdump,ethereal等工具可以获得准确的行为。
速度和双工
增强网络性能的最简单办法是检查网卡的实际速度,找到网络组件(比如交换机或hub)和网卡之间的问题。错误的配置可以导致很大的性能问题,如下图:

从下图可以看出来,在网速被错误协商后,小数据传输比大数据传输受到的影响小。大于1KB的数据传输受到极大影响(吞吐减少50~90%)。一定要确保速度双工配置正确!
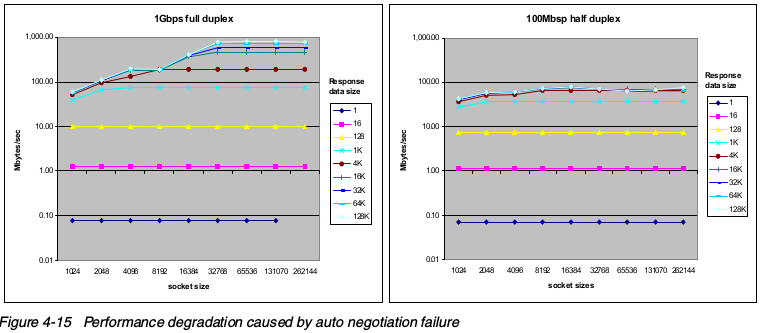
许多网络设备在自动协商中错误的默认为100Mb 半双工模式,使用ethtool检查网络真实的速度和双工设置。
许多网络专家认为,最好的办法是在网卡和交换机或者hub上同时指定静态速度。只要设备驱动支持ethtool命令,可以使用ethtool修改配置。而有些设备可能要修改/etc/modules.conf的内容。
MTU大小
在Gb网络中,最大传输单元(maximum transmission units,MTU)越大,网络性能越好。问题是,太大的MTU可能不受大多数网络的支持,大量的网卡不支持大MTU。如果要在Gb速度上传输大量数据(例如HPC环境),增加默认MTU可以导致明显的性能提升。使用/sbin/ifconfig修改MTU大小。

要使大的MTU值正常生效,这个值必须同时在网卡和网络组件上受到支持。
增加网络缓冲
Linux网络栈在分配内存资源给网络缓冲时十分谨慎!在服务器所连接的现代高速网络中,如下的参数应该增大,使得系统能够处理更多网络包。
TCP的初始内存大小是根据系统内存自动计算出来的;可以在如下文件中找到这个值:
/proc/sys/net/ipv4/tcp_mem
调高默认以及最大接收Socket的内存值:
/proc/sys/net/core/rmem_default/proc/sys/net/core/rmem_max
调高默认和最大发送Socket的内存值:
/proc/sys/net/core/wmem_default/proc/sys/net/core/wmem_max
调高最大缓存值:
/proc/sys/net/core/optmem_max
调整窗口大小
可以通过上面的网络缓冲值参数来优化最大窗口大小。可以通过BDP(时延带宽积,bandwidth delay product)来获得理论上的最优窗口大小。BDP是导线中的传输的数据量。BDP可以使用如下的公式计算得出:
BDP = Bandwidth (bytes/sec) * Delay (or round trip time) (sec)
要使网络管道塞满,达到最大利用率,网络节点必须有和BDP相同大小的缓冲区。另一方面,发送方还必须等待接收方的确认,才能继续发送数据。
例如,在1ms时延的GB级以太网中,BDP等于:
125Mbytes/sec (1Gbit/sec) * 1msec = 125Kbytes
在大多数发行版中,rmem_max和wmem_max的默认值都是128KB,对一般用途的低时延网络环境已经足够。然而,如果时延很大,这个默认值可能就太小了!
再看看另外一个例子,假如一个samba文件服务器要支持来自不同地区的16个同时在线的文件传输会话,在默认配置下,平均每个会话的缓冲大小就降低为8KB。如果数据传输量很大,这个值就会显得很低了!
- 把所有协议的系统最大发送缓冲(wmem)和接收缓冲(rmem)设置为8MB。
sysctl -w net.core.wmem_max=8388608sysctl -w net.core.rmem_max=838860
指定的这个内存值会在TCP socket创建的时候分配给每个TCP socket。
- 此外,还得使用如下的命令设置发送和接收缓冲。分别指定最小、初始和最大值。
sysctl -w net.ipv4.tcp_rmem="4096 87380 8388608"sysctl -w net.ipv4.tcp_wmem="4096 87380 8388608"
第3个值必须小于或等于wmem_max和rmem_max。在高速和高质量网络上,建议调大第一个值,这样,TCP窗口在一个较高的起点开始。
- 调高/proc/sys/net/ipv4/tcp_mem大小。这个值的含义分别是最小、压力和最大情况下分配的TCP缓冲。
可以使用tcpdump查看哪些值在socket缓冲优化中被修改了。如下图所示,把socket缓冲限制在较小的值,导致窗口变小,引起频繁的确认包,会使网络效率低下。相反,增加套接字缓冲会增加窗口大小。
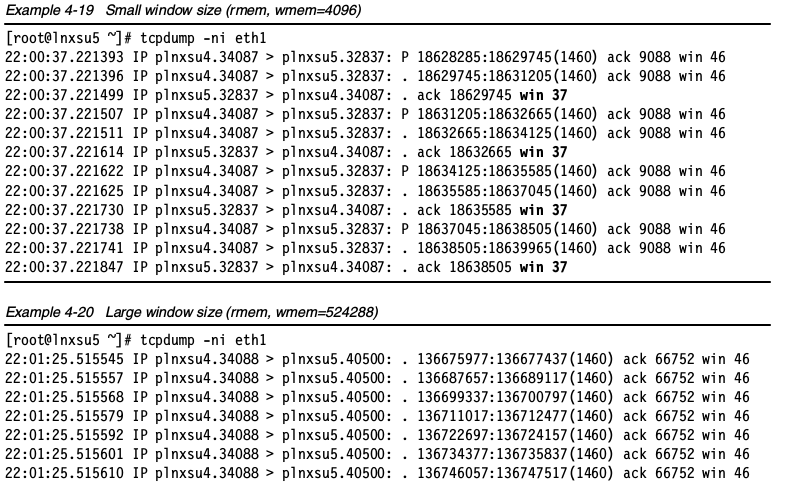

socket缓冲大小
在服务器处理许多大文件并发传输的时候,小socket缓冲可能引起性能降低。如下图所示,在小socket缓冲的情况下,导致明显的性能下降。在rmem_max和wmem_max很小的情况下,即使对方拥有充足的socket缓冲可用,还是会影响可用缓冲大小。这使得窗口变小,成为大数据传输时候的瓶颈。下图中没有包含小数据(小于4KB)传输的情况,实际中,小数据传输不会受到明显的影响。

额外的TCP/IP调整
还有很多其它增加或降低网络性能的配置。如下的参数可能会帮助提升网络性能。
优化IP和ICMP
如下的sysctl命令可以优化IP和ICMP:
禁用如下的参数可以阻止骇客进行针对服务器IP的地址欺骗攻击。
sysctl -w net.ipv4.conf.eth0.accept_source_route=0sysctl -w net.ipv4.conf.lo.accept_source_route=0sysctl -w net.ipv4.conf.default.accept_source_route=0sysctl -w net.ipv4.conf.all.accept_source_route=0
如下的服务器配置用来忽略来自网关机器的重定向。重定向可能是攻击,所以我们值允许来自可信来源的重定向。
sysctl -w net.ipv4.conf.eth0.secure_redirects=1sysctl -w net.ipv4.conf.lo.secure_redirects=1sysctl -w net.ipv4.conf.default.secure_redirects=1sysctl -w net.ipv4.conf.all.secure_redirects=1
你可以设置网卡是否接收ICMP重定向。ICMP重定向是路由器向主机传达路由信息的一种机制。例如,当路由器从某个接口收到发往远程网络的数据时,发现源ip地址与下一跳属于同一网段,这是路由器会发送ICMP重定向报文。网关检查路由表获取下一跳地址,下一个网关把网络包发给目标网络。使用如下的命令静止重定向:
sysctl -w net.ipv4.conf.eth0.accept_redirects=0sysctl -w net.ipv4.conf.lo.accept_redirects=0sysctl -w net.ipv4.conf.default.accept_redirects=0sysctl -w net.ipv4.conf.all.accept_redirects=0
如果服务器不是网关,它就没必要发送重定向包,可以禁用如下的参数
sysctl -w net.ipv4.conf.eth0.send_redirects=0sysctl -w net.ipv4.conf.lo.send_redirects=0sysctl -w net.ipv4.conf.default.send_redirects=0sysctl -w net.ipv4.conf.all.send_redirects=0
配置服务器忽略广播ping和smurf攻击:
sysctl -w net.ipv4.icmp_echo_ignore_broadcasts=1
忽略所有类型的icmp包和ping:
sysctl -w net.ipv4.icmp_echo_ignore_all=1
有些路由器会发送错误的广播响应包,内核会对每一个包都会生成日志,这个响应包可以忽略:
sysctl -w net.ipv4.icmp_ignore_bogus_error_responses=1
还应该设置ip碎片参数,尤其是NFS和Samba服务器来说。可以设置用来做IP碎片整理的最大和最小缓冲。当以bytes为单位设置ipfrag_high_thresh的值之后,分配处理器会丢掉报文,直到达到ipfrag_low_thresh的值。
当TCP包传输中发生错误时,就会产生碎片。有效的数据包会放在缓冲中,而错误的包会重传。
例如,设置可用内存范围为256M到384M,使用:
sysctl -w net.ipv4.ipfrag_low_thresh=262144sysctl -w net.ipv4.ipfrag_high_thresh=393216
优化TCP
这里讨论通过调整参数,修改TCP的行为。
如下的命令可以用来调整服务器支持巨大的连接数。
- 对于并发连接很高的服务器,TIME-WAIT套接字可以重复利用。这对web服务器很有用:
sysctl -w net.ipv4.tcp_tw_reuse=1
如果使用了上面的参数,还应该开启TIME-WAIT的套接字快速回收参数:
sysctl -w net.ipv4.tcp_tw_recycle=1
下图显示了在启用这些参数之后,连接数明显降低了。这有益于提升服务器性能,因为每个TCP连接都需要维护缓存,存放每个远端服务器信息。在这个缓存中会存放往返时间,最大分片大小和拥塞窗口。

- tcp_fin_timeout是socket在服务器上关闭后,socket保持在FIN-WAIT-2状态的时间。
TCP连接以三次握手同步syn开始,以3次FIN结束,过程中都不会传递数据。通过修改tcp_fin_timeout值,定义何时FIN队列可以释放内存给新的连接,由此提升性能。因为死掉的socket有内存溢出的风险,这个值必须在仔细的观察之后才能修改:
sysctl -w net.ipv4.tcp_fin_timeout=30
- 服务器可能会遇到大量的TCP连接打开着,却没有使用的问题。TCP有keepalive功能,探测这些连接,默认情况下,在7200秒(2小时)后释放。这个时间对服务器来说可能太长了,还可能导致超出内存量,降低服务器性能。
把这个值设置为1800秒(30分钟):
sysctl -w net.ipv4.tcp_keepalive_time=1800
- 当服务器负载很高,拥有很多坏的高时延客户端连接,会导致半开连接的增长。在web服务器中,这个现象很常见,尤其是在许多拨号用户的情况下。这些半开连接保存在backlog connections队列中。你应该该值最小为4096(默认是1024)。
即使服务器不会收到这类连接,也应该设置这个参数,他可以保护免受DoS(syn-flood)攻击。
sysctl -w net.ipv4.tcp_max_syn_backlog=4096
- TCP SYN cookies可以帮助保护服务器免受syn-flood攻击,无论是DoS(拒绝服务攻击,denial-of-service)还是DDoS(分布式拒绝服务攻击,distributed denial-of-service),都会对系统性能产生不利影响。建议只有在明确需要TCP SYN cookies的时候才开启。
sysctl -w net.ipv4.tcp_syncookies=1
注意,只有在内核编译了CONFIG_SYNCOOKIES选项的时候,上面的命令才是正确的
优化TCP选项
如下的TCP选项可以进一步优化Linux的TCP协议栈。
选择性确认可以在相当大的成都上优化TCP流量。然而,SACK和DSACK可能对Gb网络产生不良影响。tcp_sack和tcp_dsack默认情况下是启用的,但是和优化TCP/IP性能向背,在高速网络上应该禁用这两个参数。
sysctl -w net.ipv4.tcp_sack=0sysctl -w net.ipv4.tcp_dsack=0
每个发往Linux网络栈的以太帧都会收到一个时间戳。这对于防火墙、Web服务器这类系统是很有用且必要的,但是后端服务器可能会从禁用TCP时间戳,减少负载中获益。可以使用如下的命令禁用TCP时间戳:
sysctl -w net.ipv4.tcp_timestamps=0
我们已经知道缩放窗口可以增大传输窗口。然而,测试表明,窗口缩放对高网络负载的环境不合适。另外,某些网络设备不遵守RFC指导,可能导致窗口缩放故障。建议禁用窗口缩放,并且手动设置窗口大小。
sysctl -w net.ipv4.tcp_window_scaling=0
防火墙的影响
Netfilter提供TCP/IP连接跟踪和包过滤功能,在某些环境下,可能对性能产生很大影响。在连接数很高时,Netfilter的影响很明显。下图展示了测试不同连接情况下的结果,清楚表明了Netfilter的影响。

在开启Netfilter之后,情况发生了明显的变化。
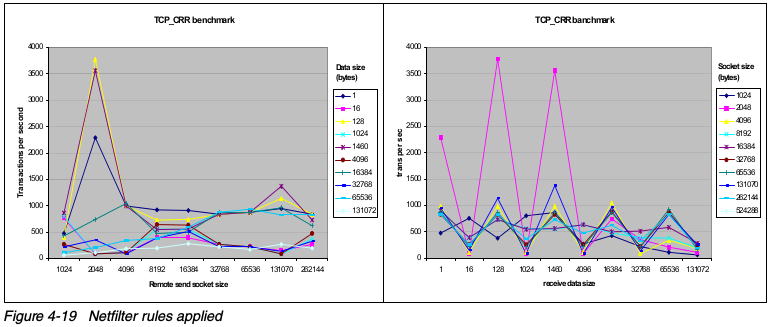
然而,Netfilter提供包过滤功能,增强了网络安全性。这是一个安全和性能之间的权衡考虑。Netfilter对性能的影响取决于如下的因素:
防火墙规则数量
防火墙规则顺序
防火墙规则复杂度
连接跟踪级别(取决于协议)
Netfilter内核参数配置
卸载配置
如果网卡支持的话,有些网络操作可以卸载到网卡上。可以使用ethtool命令确认当前的卸载配置。

修改配置命令的语法如下:
ethtool -K DEVNAME [ rx on|off ] [ tx on|off ] [ sg on|off ] [ tso on|off ] [ufo on|off ] [ gso on|off ]

对offload能力的支持受因网卡设备、Linux发行版、内核版本已经平台差异而不同。如果你使用一个不支持的offload参数,可能会获得错误信息。
offloading
测试表明,网卡offloading会降低CPU利用率。下图展示了在大块数据传输中CPU利用率的提升。大数据包从校验码offloading中获得优势,因为校验码需要计算整个数据包,所以,数据增加,处理能力就被消耗掉。
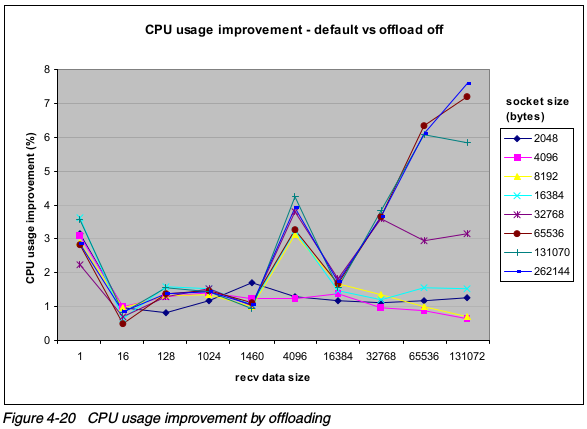
下图,在offloading中也产生了明显的性能下降。在网卡上,对如此大量的包传输率做校验,对局域网卡处理器有很大压力。随着包大小的增加,每秒种处理的包数量降低(因为要花大量时间发送和接收所有数据),所以谨慎使用网卡做校验操作。

在网络应用为大帧请求数据生成请求的时候,LAN适配器很有效率。请求小块数据的一个应用需要LAN适配器处理器花费大量的时间处理每个数据传输自己的开销。这就是为什么大多数LAN适配器不能为所有帧大小维持全速。
增加包队列
在增加各种网络缓冲大小之后,建议增加未处理包的数量,那么,花更长的时间,内核才会丢弃包。可以通过修改/proc/sys/net/core/netdev_max_backlog来实现。
增加发送队列长度
把每个接口的txqueuelength参数值增加到1000至20000。这对数据均匀且量大的高速网络连接十分有用。可以使用ifconfig命令调整传输队列长度。
[root@linux ipv4]# ifconfig eth1 txqueuelen 2000
减少中断
除非使用NAPI,处理网络包的时候需要Linux内核处理大量的中断和上下文切换。对Intel e1000–based网卡来说,要确保网卡驱动编译了CFLAGS_EXTRA -DCONFIG_E1000_NAP 标志。Broadcom tg3模块的最新版本内建了NAPI支持。
如果你需要重新编译e1000驱动支持NAPI,你可以通过在你的系统做如下操作;
make CFLAGS_EXTRA -DCONFIG_E1000_NAPI
此外,在多处理器系统中,把网卡中断绑定到物理CPU可能带来额外的性能提升。为实现这个目标,首先要识别特定网卡的IRQ。可以通过ifconfig命令获得中断号。
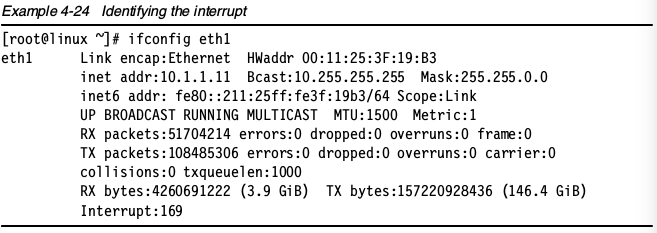
获取中断号之后,你可以使用在/proc/irq/%{irq number}中mp_affinity参数把中断和CPU绑定在一起。如下图示范了如何把之前获取的eth1网卡的169号中断,绑定到系统的第二个处理器。

原文: https://lihz1990.gitbooks.io/transoflptg/content/04.系统调优/4.7.优化网络子系统.html
